Search Marketing Connect 2021
Durante il Search Marketing Connect ho proposto due interventi: uno in sala "Advanced SEO" e riguardante l'importanza della coerenza delle informazioni e dei segnali nella SEO di oggi, e uno in "Plenaria" sulle architetture "headless". In questo post vediamo una sintesi dei concetti.


Il 3 e 4 dicembre si è svolto il Search Marketing Connect, in un'edizione che fa parte dell'iniziativa "Capodanno della Formazione Digitale".


Quest'anno, come relatore, ho potuto portare due tematiche che mi hanno appassionato durante il 2021:
- l'importanza della coerenza delle informazioni e dei segnali nella SEO di oggi (in sala Advanced SEO);
- le architetture headless (in Plenaria - Connect The Future).
In questo post, riassumo i concetti che ho condiviso all'evento.
Quanto conta la coerenza delle informazioni nella SEO?
Un viaggio tra Knowledge Panel, dati strutturati ed entità interconnesse.

Lo speech in sala "Advanced SEO", ripercorre alcune riflessioni che avevo iniziato nel post che segue.
 Alessio Pomaro
Alessio Pomaro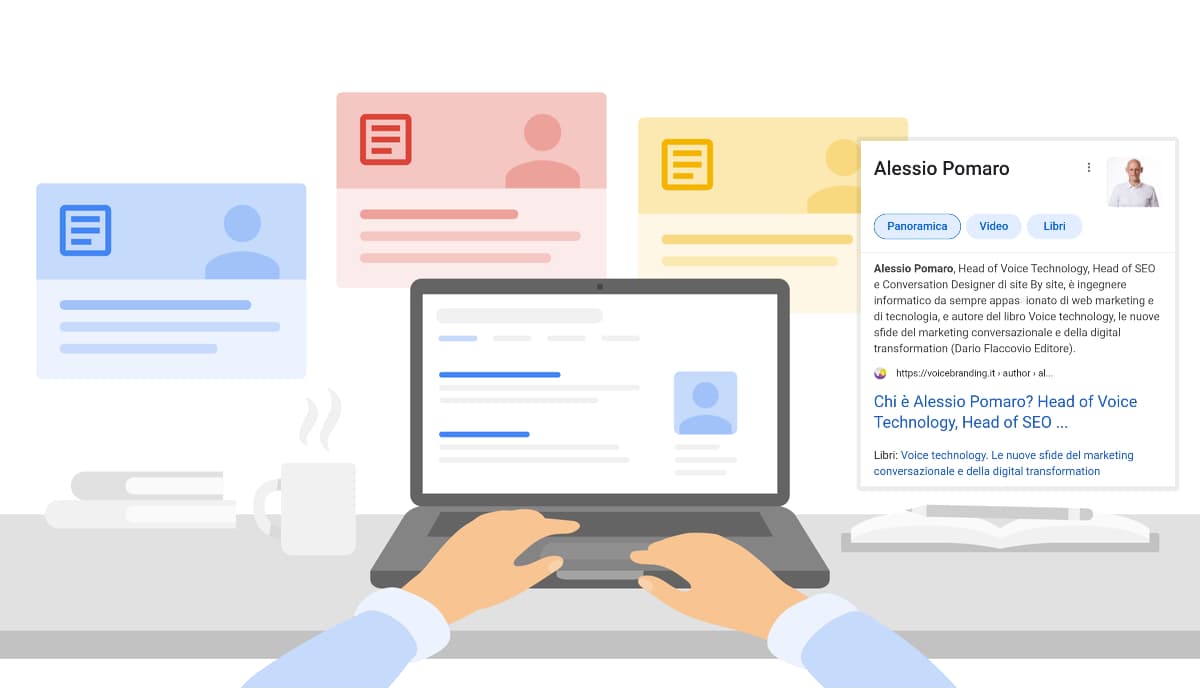
Il viaggio dell'intervento è stato molto dettagliato su tutte le operazioni svolte con l'obiettivo di rendere la mia entità (intesa come di autore) estremamente definita negli attributi, e nelle relazioni con le altre identità e con il mondo reale.
Un aspetto sul quale mi sono soffermato particolarmente è quello che viene definito "Riconciliazione".
Cos'è la Riconciliazione?
Si tratta dell’allineamento delle informazioni e dei segnali (attraverso link, dati strutturati, contenuti, ecc.) che il motore di ricerca compie per comprendere in maniera approfondita le entità e le relazioni che le caratterizzano. Un aspetto assolutamente cruciale, ma del quale si parla molto poco.
“Our systems try to recognize who that is, what that entity is. And we do that based on a number of different factors and that does include things like links to profile pages for example. Or visible information that that we can find on these pages themselves.
We call that reconciliation when it comes to structured data, kind of recognizing which of these entities belong together”.
- John Mueller, Google
Cosa possiamo fare per contribuire a questo processo?
- Possiamo creare link tra le pagine che rappresentano la stessa entità (per riconciliarle, appunto), ma anche tra le diverse entità per rendere le relazioni più chiare.
- Attraverso il costante allineamento delle informazioni. Se, ad esempio, la biografia viene modificata, tutto dev'essere assolutamente in linea. Più i dati (attributi e relazioni) sono coordinati, più i segnali risulteranno forti e precisi.
- E soprattutto usando la property “SameAs” dei dati strutturati, che fa parte dello schema (type) “Thing”, il quale viene esteso da tutti gli schemi. Di seguito vediamo un esempio di implementazione, che allinea tutte le mie pagine biografia (es. i social, i blog dove scrivo, la pagina autore di Amazon, ecc.).
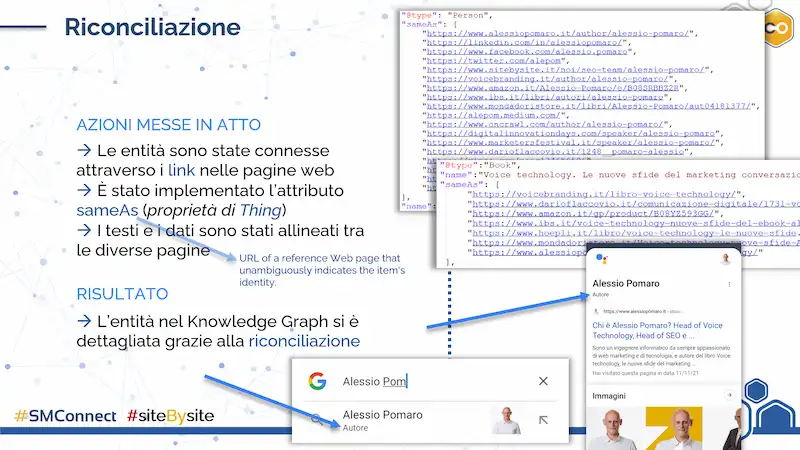
Come si nota dall'immagine, dopo aver applicato questi accorgimenti, il mio Knowledge Panel si è subito arricchito di dettagli, ad esempio della tipologia (vengo riconosciuto come “Autore”).
Non solo. In SERP, sono comparsi i box di Twitter e di YouTube relativi ai miei rispettivi profili: la riconciliazione ha avuto effetto e l'allineamento tra la mia entità e i profili social si è manifestata tra i risultati di ricerca.
L'esperimento mi ha permesso di riflettere su quattro punti che cerco di sintetizzare.
Motori di ricerca e search intent
Il semplice esperimento ci fa comprendere la tendenza di "ragionamento" dei motori di ricerca: in Google, da Hummingbird in poi, puntano ad usare entità e relazioni per determinare l'intento di ricerca e la pertinenza. Nessuna novità, certo: si tratta di concetti che risalgono a diversi anni fa.
La novità è che l'accelerazione tecnologica ed il miglioramento degli algoritmi sarà sempre più elevato. E dobbiamo entrare in queste logiche, soprattutto in fase di analisi, di determinazione delle tipologie di contenuti da creare e di strutturazione delle informazioni.
Oggi i motori di ricerca sono sempre più capaci di comprendere le entità, le correlazioni e il search intent (corrispondenza semantica). Le pagine web con informazioni coerenti "aiutano" i motori di ricerca nella fase di comprensione, e a migliorare la loro base di conoscenza.
Architettura e "topic leadership"
Dobbiamo cambiare direzione, non solo considerando la creazione di “pagine per intercettare query”, ma ragionando sul concetto di esplorazione di un topic nelle fasi dei customer journey.
L'ingrediente segreto? La conoscenza della tematica e del pubblico (le query si analizzano, ma l'esperto può anticiparle), con l'obiettivo di diventare "topic leader": il riferimento per gli utenti su un determinato argomento.
Per dirlo in tre parole: Esperienza, Autorevolezza, Affidabilità (EAT - Expertise, Authoritativeness, Trustworthiness).
Coerenza dei dati e segnali
I segnali che diamo, con dati strutturati, link e contenuti, allineano le entità e le relazioni dei grafi di conoscenza. Non mi riferisco solo alla generazione di knowledge panel, ma al fatto di aumentare la comprensione delle "cose" e velocizzare (o permettere) la scalata verso la topic leadership.
Non solo rich snippet!
Credo che dovremmo uscire dalla logica di agire solo quando Google introduce nuove SERP features!
Dobbiamo considerare i dati strutturati come dei mezzi potenti per dare segnali forti sulla struttura del nostro Knowledge Graph: delle nostre entità e di come queste si relazionano.
La SERP si evolverà sempre di più, le features aumenteranno, e ragionando in questo modo interconnesso saremo già pronti a qualunque innovazione.
E non pensiamo ai dati strutturati associandoli esclusivamente alla SERP, infatti possono essere usati per relazionarsi con ecosistemi ed applicazioni.
Un esempio? Prova a chiedere una ricetta a Google Assistant su un Nest Hub.. l'esperienza che otterrai sarà completamente generata attraverso i dati strutturati nelle pagine web.
Una visione sul futuro per concludere: i dati strutturati collegano entità digitali con il mondo reale.. proviamo ad accostare questo a Google Maps, Google My Business.. e al mondo e-commerce!
Lo scenario digital sarà sempre più "headless"?

Anche in questo caso, l'intervento deriva da alcune riflessioni iniziate in due post di questo blog che linko di seguito.
Alessio Pomaro Alessio Pomaro
Alessio Pomaro
Attraverso i seguenti punti, vediamo un take away che sintetizza i concetti più importanti presentati durante lo speech in plenaria.
1) Quali sono i 3 desideri delle aziende relativamente allo stack tecnologico?
La risposta che mi sono dato è questa: flessibilità, scalabilità e prestazioni su tutti i touchpoint. Quindi una struttura che si innesta facilmente nei flussi dei brand, che può evolversi rapidamente e che offre un’esperienza straordinaria agli utenti.
Questi sono esattamente gli obiettivi di un’architettura "headless"!
2) Cos'è un CMS Headless?
Si tratta di un sistema che fa quello che dovrebbe fare un Content Management System, ovvero gestire i contenuti. E lo fa in una struttura che separa il back-end, che metaforicamente rappresenta il “corpo” del sistema, dal front-end, che invece rappresenta la "testa".
Un’altra caratteristica fondamentale di questa architettura è che i contenuti vengono gestiti attraverso API, per ottenere l’esposizione a diversi tipi di dispositivi e piattaforme.
Nei post linkati in precedenza e nel video che segue riporto alcuni schemi che approfondiscono più dettagliatamente il funzionamento.
3) È solo questione di stack tecnologico?
No, non è solo questione di stack tecnologico, infatti il sistema che segue potrebbe non essere considerato un sistema headless.
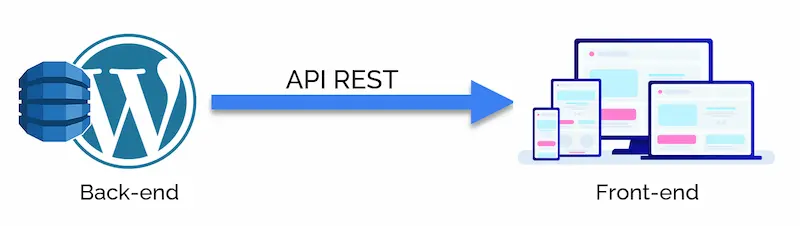
Perché? Perché va considerata anche la modalità con la quale vengono gestiti i dati!
In un sistema headless i dati devono essere salvati per essere visualizzati indipendentemente dalla piattaforma di destinazione.
Questo significa che non possono essere contaminati da parti di front-end.
4) Perché oggi sta aumentando l’interesse verso i sistemi headless?
Prima di tutto si tratta di un’evoluzione naturale dell’architettura: separare le componenti, e quindi svincolarle l'una dall'altra, permette ad ognuna di raggiungere livelli superiori in termini proprio di scalabilità, flessibilità e prestazioni!
Quindi abbracciamo il concetto iniziale (punto 1) e aggiungiamo che i brand hanno la necessità di strutturazione e di creare esperienze sempre migliori per gli utenti.. il tutto supportato da una forte accelerazione tecnologica.
5) Come si sta evolvendo l'architettura nel mondo?
Lo vediamo in alcuni punti.
- Automattic, gruppo che possiede WordPress, ha acquisito Frontity (un framework React) per potenziare il front-end. Ma di fatto inizia un percorso per rendere il CMS più diffuso al mondo, un CMS headless.
- In casa Salesforce, leader mondiale in ambito di CRM, si parla di headless commerce, che si innesta nel loro ecosistema per migliorare la customer experience. Non a caso hanno acquisito Mobify recentemente: un brand specializzato in API e front-end dedicati all’e-commerce.
- Lo scenario dei CMS headless si sta espandendo sempre maggiormente. Tra i più noti possiamo nominare Ghost, Contentful e Sanity.
- Magento e Shopify possiedono già la loro versione headless. Entrambi, per descriverla, parlano di "nuove e performanti esperienze su tutti i touchpoint".
6) L'evoluzione del front-end
L'evoluzione dei CMS headless, comporta un'enorme crescita anche in ambito front-end, grazie, ad esempio ad architetture definite JAMstack, quindi basate su Javascript. Durante l'intervento ho parlato dei framework Javascript che sono stati definiti i migliori nel 2021, e sono Gatsby a Hugo, NuxtJS, Jekyll e NextJS.
Secondo Http Archive, la page experience dei siti web sta migliorando, e quelli con front-end sviluppato attraverso un framework Javascript, sono proprio quelli con il maggior incremento di miglioramento.

7) I pro e i contro di un'architettura headless
Un'architettura headless, come abbiamo visto, ha diversi pro: possiamo ottenere una gestione dei dati migliore, e una migliore qualità di sviluppo, uniti ad una User Experience straordinaria su tutti i touchpoint.
Il contro? Le competenze richieste. Un sistema headless non è semplice da gestire. Serve un pensiero digitale maturo e un grande know-how tecnico.
Quindi.. Lo scenario digital sarà sempre più "headless"? La risposta è nel far quadrare questo bilancio.
Per approfondire


