Il rendering delle pagine web: concetti di base per i SEO
Sono un SEO.. perché dovrei conoscere le basi del rendering delle pagine web? Perché sono fondamentali per comprendere fino in fondo le metriche dei Core Web Vitals, e perché rappresentano le fondamenta delle web performance e della user experience (UX).


Punti salienti
- Importanza del rendering per i SEO
Comprendere il rendering è essenziale per migliorare le metriche dei Core Web Vitals e ottimizzare performance e user experience. - DOM (Document Object Model)
Il DOM rappresenta la struttura della pagina come un albero di nodi modificabile, consentendo la gestione dinamica degli elementi. - CSSOM (CSS Object Model)
Il CSSOM costruisce una struttura che applica gli stili CSS agli elementi del DOM, garantendo coerenza visiva. - Albero di rendering (Render-Tree)
Combina DOM e CSSOM per visualizzare solo gli elementi utili, migliorando l’efficienza e riducendo i tempi di caricamento. - Sequenza di rendering
La pagina viene visualizzata in più fasi: Layout, Paint e Composizione, per un’esperienza fluida e performante. - Percorso di rendering critico
Ottimizzare il percorso critico aiuta a ridurre i tempi di caricamento e migliorare l’esperienza utente complessiva. - Gestione degli script e degli stili
L’uso di attributi come async e defer permette di caricare JavaScript senza bloccare il rendering, migliorando la velocità. - JavaScript e CSS parser-blocking
Gli script e i CSS esterni possono bloccare il parsing e il rendering; una gestione ottimale evita ritardi e flash di contenuto non stilizzato (FOUC). - Impatto delle performance sulle conversioni
Ottimizzare le web performance aumenta il conversion rate, come dimostra lo studio “Milliseconds make millions”.
L'importanza di offrire una buona esperienza utente all'interno di un sito web sta diventando una priorità nella gestione di un progetto online. Probabilmente, il lavoro realizzato da Google con i Core Web Vitals e la cultura che è stata diffusa su queste metriche, insieme al fatto che Search Console le mette a disposizione in modo semplice, ha puntato i riflettori sui SEO come figure di riferimento in questo ambito.
Credo che questo abbia messo in luce un enorme gap di competenze e confini poco definiti..
I SEO devono avere competenze tecniche e suggerire le implementazioni agli sviluppatori? Gli sviluppatori devono accedere a Search Console per consultare le metriche? I SEO devono spiegare il problema agli sviluppatori? È un tema che riguarda solo SEO e sviluppatori?
Di certo, la soluzione è la cooperazione, ma in ogni caso, i SEO che si occupano di questi aspetti devono conoscere le basi del rendering.
È difficile, ad esempio, pensare di risolvere un problema di CLS se non si approfondiscono concetti come DOM, CSSOM e Render Tree. Lo stesso vale per l'ottimizzazione di LCP se non si conosce il percorso di rendering critico e non si sanno individuare i colli di bottiglia tra ritardo di caricamento, tempo di caricamento e rendering delay.
Per questo motivo, con questo post, vorrei descrivere le basi dalle quali partire per comprendere il processo di rendering, che a sua volta è alla base delle web performance e dell'esperienza utente che il web di oggi richiede, cercando di evitare caricamenti lenti di risorse, attese e ritardi non necessari, "flash" derivanti da elementi privi di stili (Flash Of Unstyled Content - FOUC), ecc..
La richiesta di una risorsa da parte del client
Quando un client (l'utente con il suo browser) richiede una pagina web, il server risponde con un documento HTML. Quello che segue è un esempio di una pagina molto semplice.
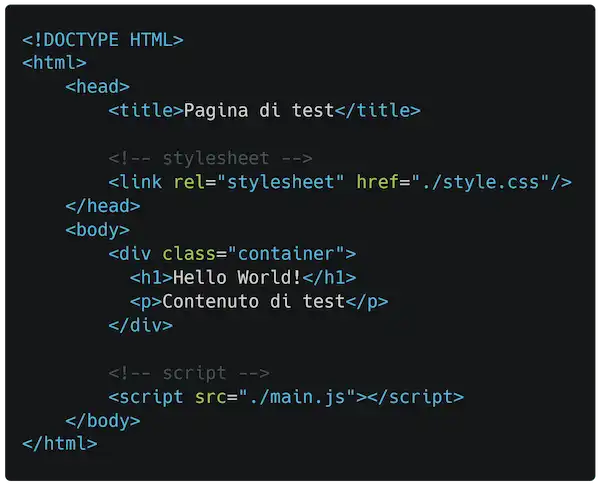
Come vediamo, la pagina dipende da style.css, responsabile degli stili degli elementi HTML e da main.js per effettuare operazioni in JavaScript.
Quello che segue potrebbe essere un esempio della pagina visualizzata dall'utente nel suo browser.

Come fa un browser a generare questo layout da un semplice file HTML che contiene del testo? Per rispondere a questa domanda dobbiamo capire cosa sono DOM, CSSOM e Render Tree.
DOM (Document Object Model)
Il DOM (Document Object Model) è un modello ad oggetti che rappresenta la struttura e il contenuto di una pagina web, ed è una sorta di interfaccia universale (Web API) accessibile e modificabile attraverso lo sviluppo.
Quando il browser processa la pagina, ogni volta che incontra un elemento HTML come html, body, div, ecc., crea un oggetto chiamato Node (nodo del DOM), e questo vale per tutte le componenti della pagina. Ogni elemento HTML ha proprietà diverse, quindi ogni nodo ha della caratteristiche in comune con gli altri, ma è un'entità ben definita.
Dopo aver creato i nodi a partire dal documento HTML, il browser crea una struttura ad albero che li comprende, poiché gli elementi HTML sono annidati uno dentro l'altro. Tale struttura consente di gestire in modo efficiente la pagina web per tutto il suo ciclo di vita.
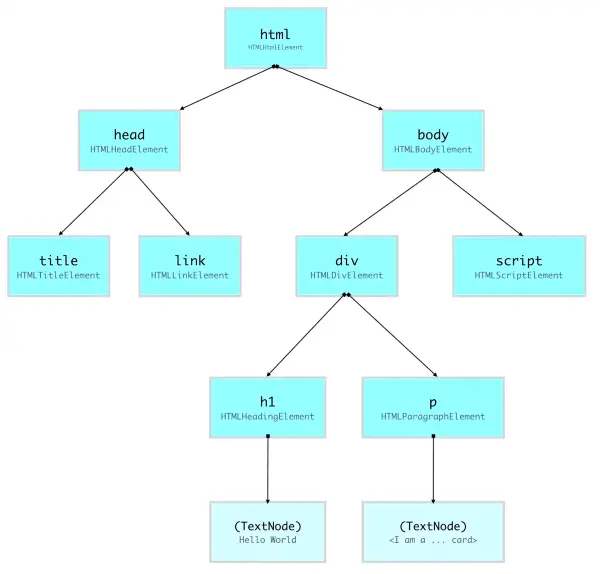
I nodi del DOM non corrispondono esclusivamente a elementi HTML, ma comprendono anche commenti, attributi e testo.
Aprendo gli strumenti per gli sviluppatori di Chrome (DevTools) e cliccando su un elemento, è possibili visualizzare e proprietà del nodo del DOM nella tab "Proprietà".
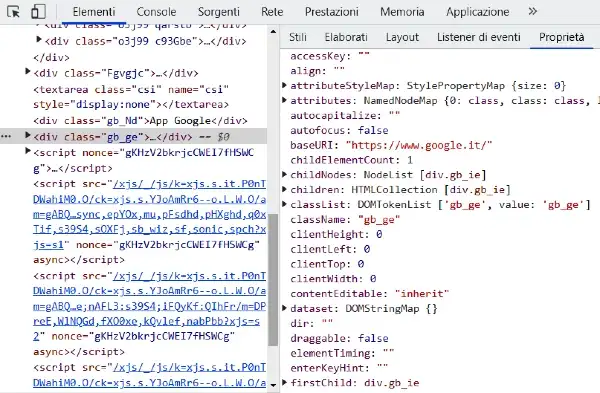
Una nota importante: il DOM non fa parte di specifiche o librerie JavaScript, ma si tratta di una Web API messa a disposizione dal browser per un rendering efficiente delle pagine, che può essere utilizzata dagli sviluppatori (attraverso JavaScript) per manipolare dinamicamente gli elementi.
Utilizzando l'API DOM è possibile aggiungere, rimuovere, clonare elementi HTML, modificarne l'aspetto ed associare "event listener".
CSS Object Model (CSSOM)
In una pagina web, gli "stili" degli elementi HTML vengono definiti dai CSS, ovvero Cascading Style Sheets. Attraverso i cosiddetti selettori CSS, è possibile specificare dei pattern che identificano gli elementi del DOM ai quali associare le regole CSS e quindi impostare un valore per le rispettive proprietà (es. font-size o color).
Esistono diversi metodi per applicare gli stili agli elementi HTML:
- utilizzando un file CSS esterno,
- attraverso delle regole CSS incorporate nella pagina web (tag <style>),
- mediante l'attributo "style" nei tag HTML,
- via JavaScript.
Indipendentemente dal metodo, il browser deve fare il duro lavoro di applicare gli stili CSS agli elementi del DOM.
Per la pagina esempio vista in precedenza, quello che segue è lo style CSS di riferimento.
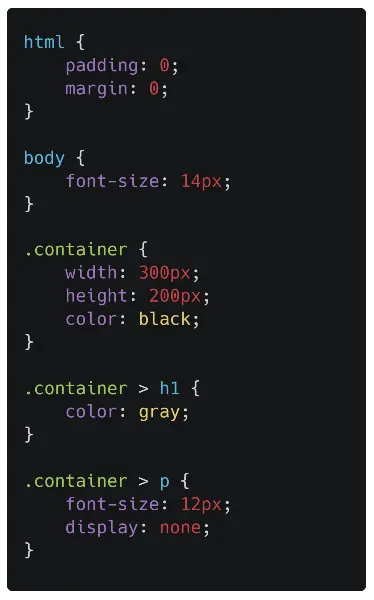
Dopo aver costruito il DOM, quindi, il browser legge i CSS da tutte le fonti (esterne, incorporate, inline, ecc.) e costruisce un CSSOM. CSSOM è l'acronimo di CSS Object Model che è una struttura ad albero proprio come il DOM.
Ogni nodo dell'albero contiene informazioni sullo stile CSS che vengono applicate agli elementi del DOM di destinazione (specificati dal selettore). CSSOM, tuttavia, non contiene elementi del DOM che non possono essere stampati sullo schermo come <meta>, <script>, <title>, ecc..
Il browser, quindi, prima di tutto calcola le proprietà CSS per l'elemento DOM sovrascrivendo il suo CSS predefinito ("user agent stylessheet") con quello definito dallo sviluppo (utilizzando le regole di specificità), e quindi costruisce un nodo.
Anche se una proprietà CSS (ad esempio "display") di un elemento HTML non viene definita né dal browser, né dallo sviluppatore, viene utilizzato un valore predefinito, come specificato dallo standard W3C CSS.
Durante la selezione del valore predefinito di una proprietà CSS, vengono utilizzate alcune regole di ereditarietà. Ad esempio, se per un elemento HTML non vengono specificate le proprietà color e font-size eredita il valore dell'elemento genitore. Il nome "Cascading Style Sheets" deriva proprio da questa caratteristica.
Nota: attraverso i DevTools di Chrome è possibile visualizzare le regole CSS per ogni elemento HTML di una pagina attraverso la tab "Elementi". Selezionando un elemento, il pannello di destra mette in evidenza gli stili (tab "Stili") e anche le proprietà finali (tab "Elaborati").
Quello che segue è un esempio di albero del CSSOM.
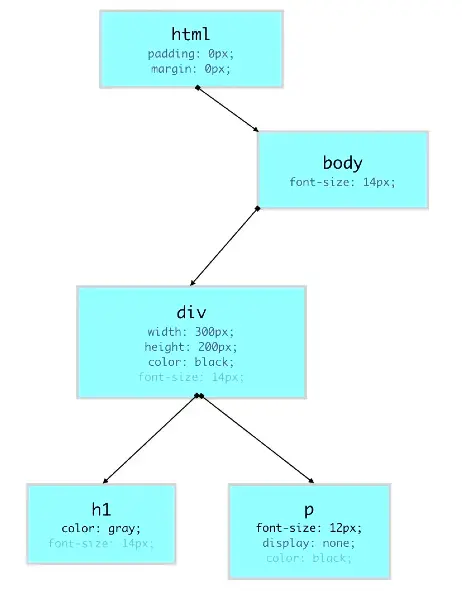
Come si vede, l'albero CSSOM non contiene elementi che non vengono stampati sullo schermo. Le proprietà CSS in grigio leggero vengono ereditate a cascata dagli elementi genitori, mentre quelle più marcate vanno a sovrascriverle.
L'albero di rendering (Render-Tree)
L'albero di rendering (Render-Tree) è una struttura che si compone combinando gli alberi del DOM e del CSSOM, e che rappresenta gli elementi che effettivamente verranno stampati sullo schermo. Proprio per questo motivo, gli elementi che non occupano uno spazio (es. elementi display:none o che hanno come dimensioni zero pixel - 0px) non sono presenti.
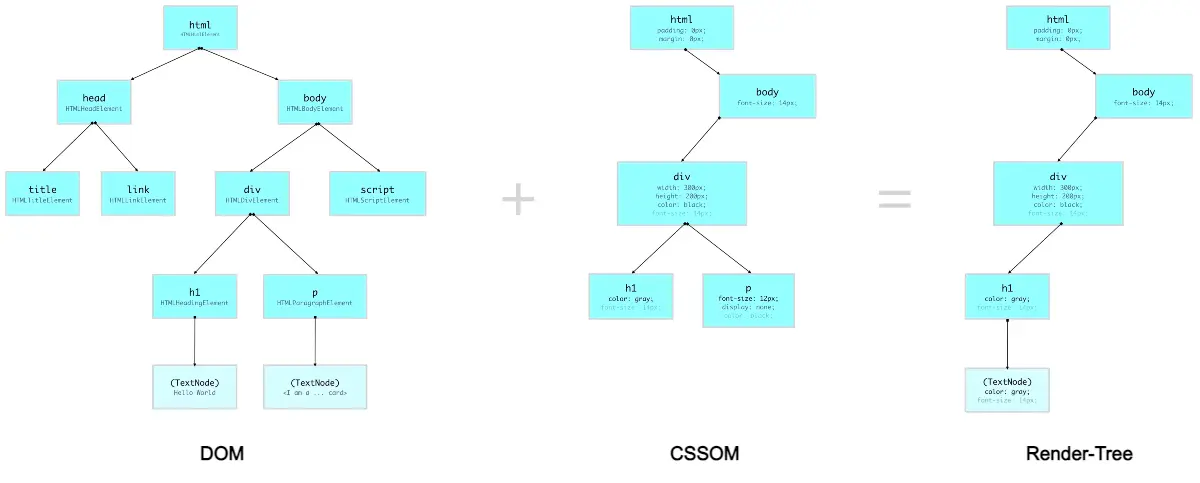
Come si vede dallo schema, l'elemento "p" all'interno del "div" ha una regola CSS che lo rende "display:none". Questo fa sì che quell'elemento e i suoi figli non compaiano nell'albero di rendering perché non occuperanno spazio sullo schermo. Se, invece, ad esempio, si utilizzassero "visibility:hidden" oppure "opacity:0", pur non essendo elementi visibili all'utente (come con "display:none"), sarebbero presenti nell'albero di rendering, perché queste proprietà fanno sì che l'elemento comunque occupi spazio sullo schermo.
Nota importante: la conoscenza di questi concetti può far risolvere problematiche di CLS (Cumulative Layout Shift) con qualche regola di CSS (un esempio nelle conclusioni).
A differenza dell'API DOM che dà accesso agli elementi del DOM, CSSOM è tenuto "nascosto" all'utente. Ma poiché il browser combina DOM e CSSOM per generare l'albero di rendering, il browser espone il nodo CSSOM di un elemento del DOM fornendo un'API di alto livello sull'elemento DOM stesso. Ciò consente agli sviluppatori, attraverso JavaScript, di accedere e modificare le proprietà CSS di un nodo CSSOM.
Sequenza di rendering
Ora che abbiamo compreso cosa sono DOM, CSSOM e Render-Tree, cerchiamo di capire come un browser esegue il rendering di una pagina web. Avere una conoscenza minima di questo processo è fondamentale per massimizzare l'esperienza utente (UX) e le web performance.
Un piccolo ripasso. Quando viene caricata una pagina web, come abbiamo visto, il browser interpreta l'HTML e da esso costruisce l'albero del DOM. Quindi elabora il CSS indipendentemente dal fatto che sia inline, incorporato o esterno e da esso costruisce l'albero del CSSOM.
Da tali strutture costruisce il Render-Tree, ed infine avvia la stampa degli elementi sullo schermo con le fasi che seguono.
Layout
Durante l'operazione di layout il browser calcola le dimensioni di ogni nodo dell'albero di rendering in pixel e la posizione in cui verrà stampato sullo schermo. Tale processo viene definito anche reflow o browser reflow e può verificarsi anche quando si scorre e si ridimensiona la finestra o si manipolano elementi DOM.
Paint
Fino a questo momento siamo di fronte ad un elenco di "geometrie" che devono essere stampate sullo schermo. Poiché gli elementi del Render-Tree possono sovrapporsi l'un l'altro e possono avere proprietà CSS che fanno cambiare loro frequentemente l'aspetto, la posizione o la geometria (es. attraverso le animazioni), il browser li dispone in livelli.
Attraverso la gestione a livelli il browser riesce ad eseguire in modo efficiente le operazioni di "disegno" per tutto il ciclo di vita di una pagina web, ad esempio durante lo scorrimento o il ridimensionamento della finestra del browser. Avere livelli aiuta anche il browser a disegnare correttamente gli elementi nell'ordine di sovrapposizione (lungo l'asse z) come previsto in fase di sviluppo (sfruttando il noto z-index).
Possiamo fare un'analogia con i livelli di Photoshop.
All'interno di ogni livello, il browser riempie i singoli pixel per tutte le proprietà degli elementi (bordo, sfondo, ombra, testo, ecc.). Questo processo viene definito rasterizzazione.
I diversi livelli di una pagina possono essere visualizzati attraverso i DevTools di Chrome nell'apposita tab.
Composizione
Fino a questo momento, nessun pixel è stato disegnato effettivamente sullo schermo: abbiamo i diversi livelli da rappresentare in un ordine specifico. Nella fase di composizione, avviene proprio questo passaggio: i livelli vengono inviati alla GPU per essere rappresentati sulla finestra del browser.
Il percorso di rendering critico
I concetti e le fasi descritte in precedenza, determinano una sequenza di eventi che il browser attraversa partendo dalla risposta del server, quindi da un documento di testo contenente HTML e CSS, fino a ciò che l'utente visualizza nella finestra del browser.

Tale sequenza prende il nome di Percorso di Rendering Critico (CRP, dall'acronimo del termine in inglese).
Più saremo in grado di efficientare tale percorso grazie al lavoro sulle nostre pagine web, e più potremo contare su web performance e UX straordinarie.
Il motivo lo capiremo a breve.
Perché in browser diversi possiamo avere visualizzazioni diverse?
HTML, CSS o JavaScript, chiaramente, seguono degli standard. Tuttavia, il modo in cui un browser li gestisce per visualizzare gli elementi sullo schermo non è standardizzato. Google Chrome, ad esempio, potrebbe rappresentare dei componenti in modo diverso da Safari.
Tuttavia, la documentazione di HTML 5 è molto precisa, con lo scopo di avvicinare il più possibile le operazioni di rendering. Infatti, oggi, le differenze si sono ridotte rispetto al passato.
Parsing e risorse eterne
Il parsing è il processo di lettura del contenuto HTML con la relativa costruzione dell'albero del DOM.
Quando la risposta del server arriva al browser, appena disponibili i primi caratteri del documento, l'operazione può iniziare e il DOM viene costruito in maniera incrementale, nodo dopo nodo.
Se facciamo un test di una pagina abbastanza pesante ed impostando una connessione molto lenta (es. 10 kbs), noteremo che il browser inizia subito a costruire il DOM e a stampare elementi sullo schermo mentre sta ancora scaricando il documento in background.
Da quando abbiamo iniziato a parlare di Core Web Vitals, abbiamo scoperto termini coma FP (First Paint), ovvero il tempo che impiega il browser per iniziare a stampare sullo schermo, FCP (First Contentful Paint), ovvero il tempo che viene impiegato per la stampa del primo pixel del contenuto (es. testo o un'immagine), LCP (Largest Contentful Paint), che indica il tempo per la stampa dell'elemento più largo del viewport. Grazie alla comprensione delle fasi di rendering, è possibile comprendere con molta più chiarezza tali concetti.
Risorse esterne
Ogni volta che il browser incontra nel documento una risorsa esterna come un file di script (JavaScript) attraverso <script src="script.js"></script>, un foglio di stile (CSS) attraverso <link rel="stylesheet" href="style.css">, un'immagine attraverso <img src="immagine.webp" />, o qualunque altra tipologia di risorsa, avvierà il download del file in background (e in thread secondari).
Ciò che è importante ricordare è che la creazione del DOM avviene nel thread principale, e se questo è impegnato per altre operazioni, dovrà necessariamente interrompersi.
Ogni richiesta di file esterni (es. immagini, CSS, video, ecc.) non blocca il parsing e la costruzione del DOM, ad eccezione degli script (JavaScript).
JavaScript: script parser-blocking
Uno script parser-blocking è un file o un blocco di codice JavaScript che interrompe il parsing dell'HTML. Quando il browser incontra uno script, se si tratta di codice incorporato verrà eseguito prima di continuare ad analizzare l'HTML per costruire il DOM. Quindi..
tutti gli script JavaScript incorporati bloccano il parsing, fine della discussione!
Se si tratta di uno script esterno, il browser avvierà il download del file ed interromperà il parsing dell'HTML. Una volta scaricato verrà eseguito. Solo successivamente continuerà il lavoro di creazione del DOM.
Perché il browser deve interrompere l'analisi del DOM fino a quando JavaScript non viene scaricato ed eseguito? Perché, come abbiamo visto, JavaScript può modificare il DOM, ma se nel frattempo l'albero continua ad essere generato potrebbero crearsi delle situazioni di concorrenza.
Gli attributi async e defer
L'interruzione del parsing durante il download dello script è inutile nella maggior parte dei casi. Quindi HTML5 ha introdotto l'attributo "async", il quale fa sì che questo non avvenga. Una volta scaricato il file, però, il parsing si interromperà e lo script verrà eseguito.
Esiste anche l'attributo "defer" per gli script, il quale consente di non interrompere mail il pasring: il download avviene parallelamente, mentre l'esecuzione sarà dopo il completamento dell'albero del DOM.
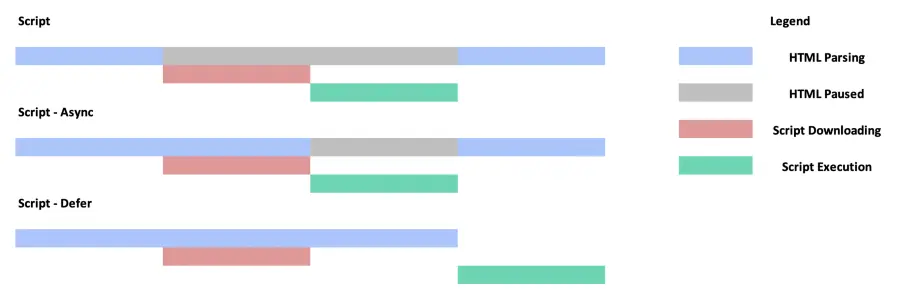
Ricapitolando, tutti gli script (incorporati o esterni) bloccano il parser poiché bloccano la costruzione del DOM. Gli script async (asincroni) non bloccano il parser fino a quando non vengono scaricati. Non appena uno script async viene scaricato, diventa parser-blocking. Tutti gli script defer (differiti) non sono bloccanti per il parsing, in quanto vengono scaricati parallelamente e vengono eseguiti a DOM completo.
Il blocco del parsing viene anche definito blocco del rendering, perché chiaramente il rendering non avverrà a meno che non venga costruito l'albero DOM, tuttavia si tratta di concetti diversi.
CSS parser-blocking
Come abbiamo visto in precedenza, qualsiasi richiesta di risorse esterne, ad eccezione del JavaScript, non blocca il processo di creazione del DOM. Quindi il CSS (anche embedded) non blocca il parser.. però blocca il rendering. Vediamo cosa significa.
Ricapitoliamo velocemente il processo di rendering. DOM e CSSOM vengono costruiti contemporaneamente e insieme vanno a generare il Render Tree, il quale nasce dall'unione dei due in modo incrementale, man mano che viene costruito l'albero del DOM.
La costruzione del CSSOM, al contrario, non è incrementale ed avviene in maniera diversa. Quando il browser trova un blocco <style>, analizzerà tutte le regole CSS incorporate e aggiornerà l'albero CSSOM. Successivamente, continuerà ad analizzare l'HTML. Lo stesso vale per lo stile inline.
Tuttavia, le cose cambiano drasticamente quando il browser incontra un file CSS esterno. A differenza di un file JavaScript esterno, un foglio di stile esterno non blocca il parsing, quindi il browser può scaricarlo in background e la generazione del DOM continuerà.
Ma a differenza del documento HTML (per la costruzione del DOM), il browser non elaborerà il contenuto del CSS un byte alla volta. Questo perché non è possibile creare l'albero del CSSOM in modo incrementale. Perché una regola CSS alla fine del file potrebbe sovrascrivere una regola CSS indicata nella parte iniziale.
Quindi, se il browser iniziasse a costruire il CSSOM in modo incrementale mentre analizza il contenuto del CSS, questo porterebbe a più aggiornamenti dell'albero di rendering, e sarebbe un'esperienza utente spiacevole: si vedrebbero elementi che cambiano stile sullo schermo mentre il CSS viene analizzato.
Per evitare questo, l'aggiornamento del CSSOM avviene dopo che tutte le regole CSS sono state elaborate. Segue l'aggiornamento dell'albero di rendering e la visualizzazione sullo schermo.
CSS è una risorsa che blocca il rendering.
Cosa accadrebbe, invece, se, per assurdo, la generazione dell'albero di rendering continuasse con regole CSS di default? Permetterlo sarebbe un errore, perché in questo caso, successivamente:
- una volta scaricato e analizzato il foglio di stile e aggiornato CSSOM,
- il Render Tree verrebbe aggiornato e visualizzato sullo schermo,
- i nodi dell'albero di rendering generati con le regole CSS di default verrebbero ricreati con nuovi stili.
Si potrebbe creare, quindi, un FOUC (Flash of Unstyled Content), che è molto dannoso per la UX e per le metriche relative ai Core Web Vitals.
Una volta che il browser effettua una richiesta per recuperare un foglio di stile esterno, la costruzione dell'albero di rendering viene interrotta. Pertanto anche il Percorso di Rendering Critico viene bloccato e sullo schermo non viene visualizzato nulla. Tuttavia, la costruzione dell'albero DOM è ancora in corso mentre il foglio di stile viene scaricato in background.
Per questi motivi si consiglia di caricare tutti i fogli di stile esterni il prima possibile, possibilmente nel blocco head della pagina.
CSS + JavaScript in sequenza
Immaginiamo uno scenario in cui il browser ha avviato l'analisi dell'HTML e incontra un CSS esterno. Avvierà quindi il download del file in background, bloccherà il Percorso di Rendering Critico e continuerà con la generazione del DOM.
Successivamente incontra un JavaScript esterno. Quindi avvierà il download e bloccherà la generazione del DOM. Il browser si trova in uno stato inattivo, in attesa che il CSS e il JavaScript vengano scaricati completamente.
Cosa accade se il JavaScript esterno termina il download prima del CSS? Il browser eseguirà JavaScript? Oppure sarebbe dannoso?
Mentre il foglio di stile viene scaricato in background, JavaScript potrebbe essere eseguito perché il thread principale non viene bloccato dal CSS. Il rischio è che se JavaScript agisce sulle proprietà CSS di un elemento DOM che successivamente vengono modificate una volta che viene elaborato il foglio di stile, non otterremo l'effetto desiderato. Per questo motivo, non è sicuro eseguire JavaScript durante il download del foglio di stile.
Secondo la documentazione di HTML5 , il browser può scaricare un file JavaScript, ma non lo eseguirà a meno che non vengano analizzati tutti i fogli di stile precedenti. Quando un foglio di stile blocca l'esecuzione di uno script, questo viene definito CSS script-blocking.
Come gli attributi async e defer rendono il JavaScript non parser-blocking , un CSS esterno può diventare non render-blocking utilizzando l'attributo media.
Conclusioni
Spero che queste osservazioni, questi concetti e questi appunti posano essere d'aiuto a comprendere al meglio il senso dei Core Web Vitals e a conoscere ciò che governa il rendering di una pagina web.
Scrivendo questo post, e quindi entrando nei concetti in modo estremamente dettagliato, mi è venuta un'idea su come risolvere i problemi di CLS di questo sito web da desktop. Quello che segue è il risultato.
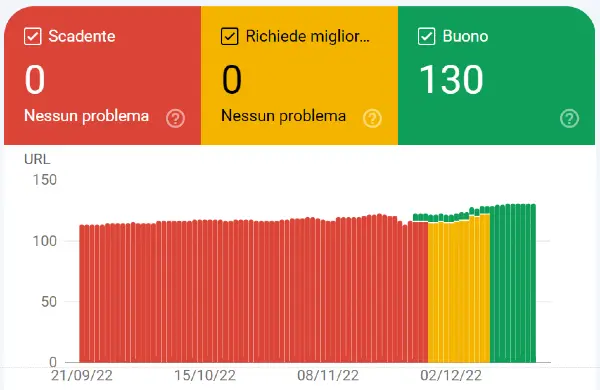
Come ho fatto? L'ho recentemente raccontato durante una giornata di formazione con gli amici di H-FARM Digital Marketing. Il video che segue riprende i passaggi.
Come ho risolto un problema di CLS grazie alla conoscenza del rendering delle pagine web
Con 4 righe di CSS e una di JavaScript abbiamo risolto il problema!
Chiudo il post con una nota e con una considerazione.
La nota: lo scenario che ho descritto nell'articolo, relativo al problema di CLS, l'ho davvero risolto con queste conoscenze, 4 righe di CSS e una di JavaScript.
La considerazione: come ci ricordano anche Google e Deloitte nel noto studio "Milliseconds make millions", il miglioramento delle web performance si trasformano in profitto per i brand. Non mi stancherò mai di ripeterlo.

Buon percorso di rendering critico!
Per approfondire

 Alessio Pomaro
Alessio Pomaro