GPT-3 e l'addestramento personalizzato: fine-tune training
Come possiamo personalizzare la base di conoscenza di GPT-3 e far mantenere all'intelligenza artificiale un "tone of voice" allineato con il brand? Addestrando il modello su un set di dati specifico (fine-tune training). Vediamo di cosa si tratta.


Quando si pensa alla natura dei modelli (LLM - Large Language Models) come GPT-3 di OpenAI, probabilmente si materializza un dubbio..
Se il training avviene utilizzando i dati presenti online, come possiamo personalizzare la base di conoscenza e dare all'intelligenza artificiale un "tone of voice" che sia allineato con il brand?
Proprio per andare incontro a questo concetto, OpenAI ha implementato la possibilità, per gli sviluppatori, di addestrare GPT-3 su un set di dati specifico, creando una versione personalizzata dell'applicazione. Tale aspetto, rende GPT-3 affidabile per una varietà di casi d'uso più ampia, e l'esecuzione del modello più veloce.
È possibile utilizzare un set di dati esistente di qualsiasi forma e dimensione, o aggiungere dati in modo incrementale in base al feedback degli utenti. OpenAI riporta due casi di clienti che utilizzano le API, che, grazie alla customizzazione del training, hanno ottenuto i seguenti miglioramenti:
- l'aumento degli output corretti dall'83% al 95%, aggiungendo nuovi dati ogni settimana (incrementale);
- la riduzione dei tassi di errore del 50%.
Iniziare ad usare il training personalizzato è abbastanza semplice, e nei prossimi paragrafi lo vediamo.
GPT-3, come sappiamo, può eseguire un'ampia gamma di attività utilizzando il linguaggio naturale, e grazie alla personalizzazione può produrre risultati ancora migliori, perché consente di mettere a disposizione più dati per il dominio di interesse.
Con un centinaio di esempi (anche meno) si iniziano ad osservare i vantaggi dell'addestramento aggiuntivo, e le prestazioni continuano a migliorare man mano che si aggiungono dati. In una ricerca pubblicata da OpenAI viene mostrato come con circa 100 esempi possono migliorare le prestazioni su determinati task, ma anche come, raddoppiando gli esempi, la qualità aumenta in modo lineare.
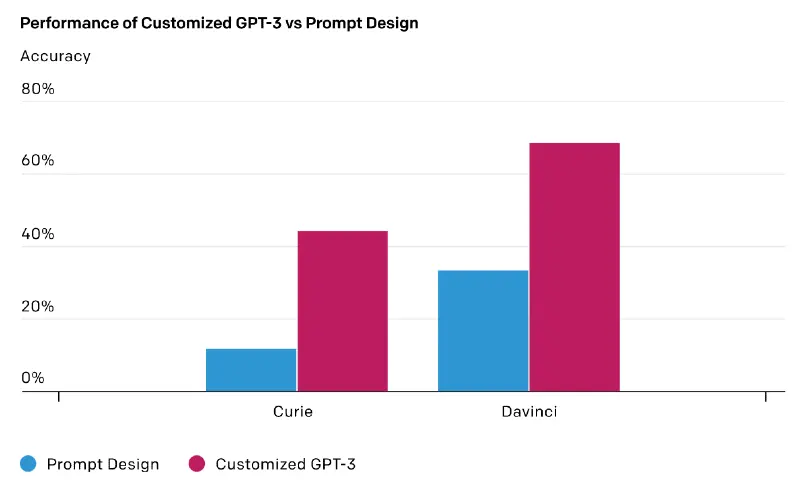
La personalizzazione di GPT-3 migliora l'affidabilità dell'output, offrendo risultati più coerenti e precisi per i casi d'uso in produzione. Un cliente di OpenAI ha affermato che il fine-tune training ha ridotto la frequenza degli output inaffidabili dal 17% al 5%. Poiché inoltre le versioni custom di GPT-3 sono centrate su un'applicazione specifica, il prompt richiesto per ottenere l'output dalle singole chiamate API può essere molto più breve, riducendo i costi e migliorando la latenza.
Il principio di funzionamento
GPT-3 è stato pre-addestrato su una grande quantità di testo estrapolato dal web. Nel momento in cui viene fornito un prompt (l'input che viene inviato all'intelligenza artificiale per ottenere un completamento o altre lavorazioni) con solo alcuni esempi, il sistema può intuire l'intento cercando di generare un completamento plausibile. Questo processo viene spesso definito "few-shot learning".
Il fine-tune training va a migliorarlo, attraverso un addestramento basato su un numero di esempi molto superiore di quelli che possono essere compresi in un prompt, consentendo di ottenere risultati migliori su un ampio numero di attività. Una volta che un modello è stato messo a punto, non sarà più necessario fornire esempi nel prompt.
Ad alto livello, la customizzazione prevede i seguenti passaggi:
- preparazione e caricamento dei dati di training (gli esempi aggiuntivi);
- creazione di un nuovo modello "perfezionato";
- utilizzo del nuovo modello perfezionato.
Come si personalizza GPT-3 per un'applicazione specifica
Vediamo in dettaglio i singoli step.
Installazione
Per installare la console di OpenAI (CLI) è sufficiente eseguire il seguente comando.
pip install --upgrade openai
Nota: la CLI OpenAI richiede Python 3.
Una volta completata l'installazione, è necessario impostare l'API key di OpenAI come variabile d'ambiente in modo da renderla sempre disponibile alle chiamate remote successive. Il seguente comando permette di farlo.
export OPENAI_API_KEY="<OPENAI_API_KEY>"
Nota: per abilitare le API di OpenAI, segui i semplici step descritti qui.
Preparazione dei dati di training
I dati devono essere in un documento JSONL, in cui ogni riga corrisponde ad un esempio di training, ovvero ad una coppia di prompt e completamento ideale.
{"prompt": "<prompt esempio>", "completion": "<testo generato ideale>"}
{"prompt": "<prompt esempio>", "completion": "<testo generato ideale>"}
{"prompt": "<prompt esempio>", "completion": "<testo generato ideale>"}
...
Mentre per i prompt classici dei modelli di base (Davinci, Curie, Babbage, Ada) sono costituiti da più esempi ("few-shot learning"), in questo caso ogni esempio è costituito da un singolo input e un output.
È disponibile un tool che prepara i dati per la creazione del modello, fornendo anche suggerimenti per l'ottimizzazione. Per utilizzarlo, il comando da utilizzare è il seguente.
openai tools fine_tunes.prepare_data -f <FILE JSONL>
Lo strumento accetta formati diversi, ad esempio CSV, TSV, XLSX, JSON o JSONL. L'unico requisito è che contengano una colonna di prompt e una di completamento. L'output è un file JSONL pronto per il fine-tune training.
Un esempio di esecuzione in shell.
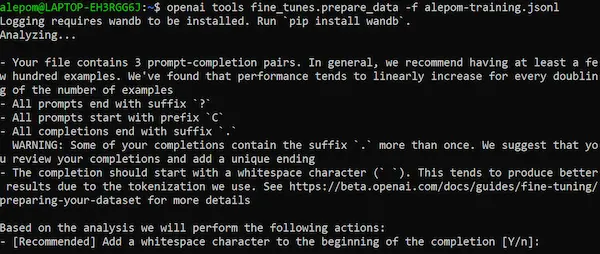
Come si vede, stampa una serie di consigli e, richiedendo il permesso, attua delle ottimizzazioni.
Creazione del modello personalizzato
Il seguente comando permette di generare un nuovo modello sulla base di uno dei modelli predefiniti.
openai api fine_tunes.create -t <FILE JSONL> -m <MODELLO DI BASE>
La stringa "MODELLO DI BASE " corrisponde al nome del modello dal quale si parte, e può essere ada , babbage , curie ( modello predefinito ) o davinci.
La scelta del modello influenza sia il comportamento dell'algoritmo, sia il costo di utilizzo e di fine-tune training.
L'attività di creazione del modello può durare pochi minuti, ma anche diverse ore se il training set è molto ampio.
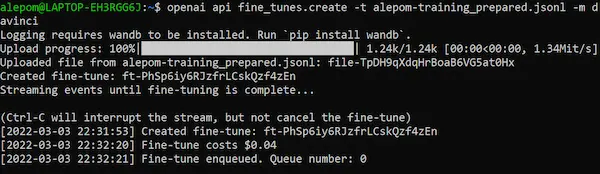
Una volta completata la creazione, il nuovo modello personalizzato diventa a disposizione per l'account OpenAI, ed è visibile da subito anche tra i modelli nel Playground.
Nel pannello di utilizzo della API, allo stesso modo, si possono consultare non solo le chiamate per le funzionalità di GPT-3, ma anche di creazione di fine-tune training.
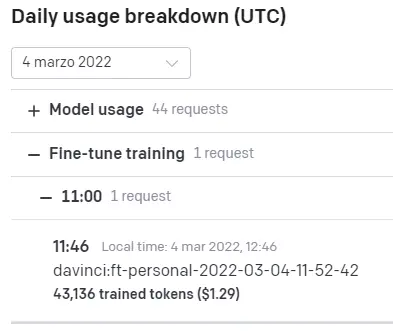
L'utilizzo del modello personalizzato
L'utilizzo del modello può avvenire attraverso il comando più noto agli utilizzatori di GPT-3:
openai api completions.create -m <MODELLO PERSONALIZZATO> -p <PROMPT>
Si tratta di un comando della CLI di OpenAI, ma è possibile utilizzare il modello usando diversi linguaggi di programmazione e CURL.
Nella documentazione della funzione "Completions", sono consultabili tutti i parametri a disposizione per perfezionare le richieste.
L'immagine che segue, mostra una chiamata API utilizzando il modello davinci.

Vediamo, invece, un esempio di una richiesta utilizzando un modello personalizzato.

All'interno della documentazione di OpenAI è possibile trovare ulteriori approfondimenti relativi ad ulteriori comandi e funzionalità.
L'analisi dei dati dei modelli personalizzati
OpenAI mette a disposizione Weights & Biases: uno strumento per tenere traccia ed analizzare i dati relativi ai modelli personalizzati.
Quello che segue, è un esempio di visualizzazione dei dati a disposizione.
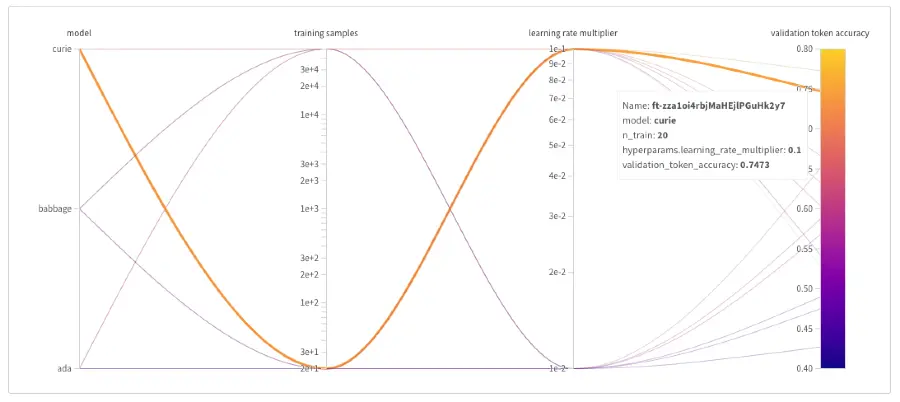
Prima di tutto, è necessario attivare un account del servizio (a pagamento). Successivamente, il seguente comando esegue l'installazione di W&B.
pip install --upgrade openai wandb
Infine, per sincronizzare i fine-tune training con Weights & Biases, è necessario eseguire:
openai wandb sync
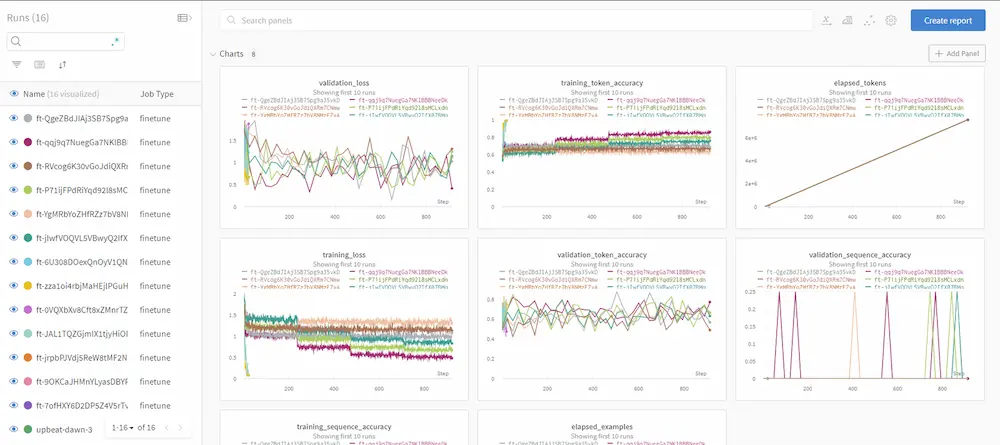
Ed ecco un altro esempio delle dashbord che si possono consultare.
Conclusioni
Grazie al training personalizzato si possono ottenere dei modelli che si adattano alle informazioni del brand di riferimento. Un allineamento da sfruttare insieme alle potenzialità di GPT-3.
Negli esempi che ho riportato, come si vede, utilizzo dei prompt con delle semplici domande. Se l'applicazione che si desidera realizzare ha lo scopo di generare un semplice sistema Q&A, consiglio di consultare anche la funzionalità di OpenAI denominata "Question answering".
Una curiosità: come si possono fare dei test con la console di OpenAI su Windows?
In ambienti come Linux e Mac, installare ed utilizzare la CLI di OpenAI è assolutamente semplice (basta seguire gli step del post o della documentazione). Su Windows, un po' meno; già allo step della scrittura della variabile d'ambiente iniziano le prime difficoltà.
Per i miei test, infatti, ho utilizzato una console Linux.. ma su un laptop con Windows 10! Come ho fatto? Semplicemente sfruttando WSL (Windows Subsystem for Linux), ovvero una virtualizzazione di Linux all'interno di Windows, disponibile in pochi clic.
La seguente risorsa spiega in maniera dettagliata come procedere.
Per approfondire
 Alessio Pomaro
Alessio Pomaro Alessio Pomaro
Alessio Pomaro

