Generative AI: novità e riflessioni - #9 / 2024
Come funzionano i nuovi modelli di OpenAI? Come si addestra Flux per immagini professionali? Come si trasforma un documento in un podcast coinvolgente? Le novità di Anthropic, di Llama e di Google, spunti per il Prompt Engineering e SearchGPT.. e molto altro.


Buon aggiornamento, e buone riflessioni..
La sostenibilità dell'AI: una riflessione
Il tema della sostenibilità dell'AI è sempre più centrale nel dibattito contemporaneo.
Un parallelismo interessante è quello che sento spesso da Luciano Floridi (che stimo tantissimo) sul Concorde.

Il Concorde, un aereo rivoluzionario, offriva enormi vantaggi in termini di velocità di spostamento, ma non era economicamente sostenibile ed è stato dismesso.
La domanda è: quante persone nel mondo beneficiavano del Concorde? E quanti utenti, oggi, stanno usando l'AI ogni giorno?
Togliamo pure chi la usa per "giocare".. per quante realtà queste tecnologie stanno diventando degli ingranaggi straordinari nei flussi di lavoro?
Sto vedendo delle applicazioni davvero dirompenti in produzione. Per questo mi chiedo.. è reversibile ciò che stiamo vivendo? Ho qualche dubbio in merito, considerando anche il potenziale messo a disposizione dal mondo open source.
Nel frattempo... Llama 3.1-Nemotron di Nvidia
Nvidia ha rilasciato un LLM altamente efficiente basato su Llama 3.1-70B, con miglioramenti nell'accuratezza e nell'efficienza grazie all'uso di una nuova tecnica chiamata Neural Architecture Search (NAS).
Il modello (Llama 3.1-Nemotron) è più veloce di 2,2 volte rispetto al modello di riferimento e può eseguire workload 4 volte più grandi su una singola GPU, mantenendo un'accuratezza simile.
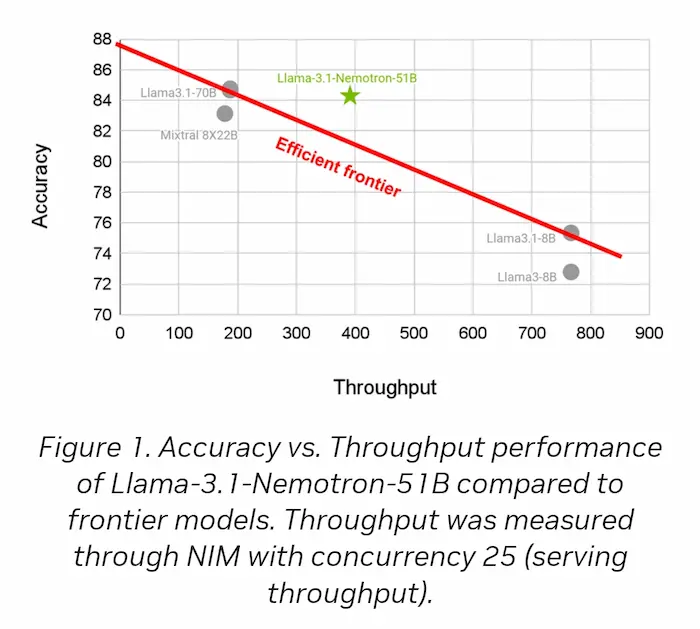
Grazie alla riduzione del consumo di memoria e della larghezza di banda, il modello è più economico da eseguire su una singola GPU, aprendo nuove possibilità di applicazioni anche su sistemi edge e cloud.
[risorsa gratuita] Come creare GPTs con un Web Scraper
Come si può usare un semplice web scraper nei nostri GPTs personalizzati senza introdurre codice e servizi esterni?
Attraverso WebPilot!
Un GPT custom con Web Scraper
Nel video, un piccolo esempio di funzionamento.
I nuovi modelli "o1" (strawberry) di OpenAI
OpenAI rilascia una nuova serie di modelli, denominata "o1-preview" (Strawberry).
Migliora la capacità di ragionamento, grazie a un'elaborazione più approfondita prima di rispondere. Nelle immagini si vedono alcuni passaggi, con gli step di ragionamento.
o1 supera GPT-4o (di molto), in ambito scientifico, nella programmazione e nella matematica, con risultati comparabili a studenti di dottorato in fisica, chimica e biologia.
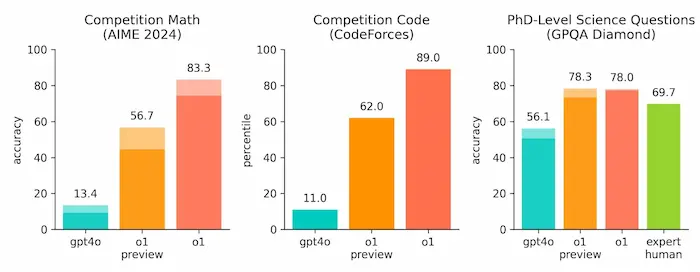
Ho fatto dei test anche con la scrittura di contenuti lunghi, con contesti strutturati.
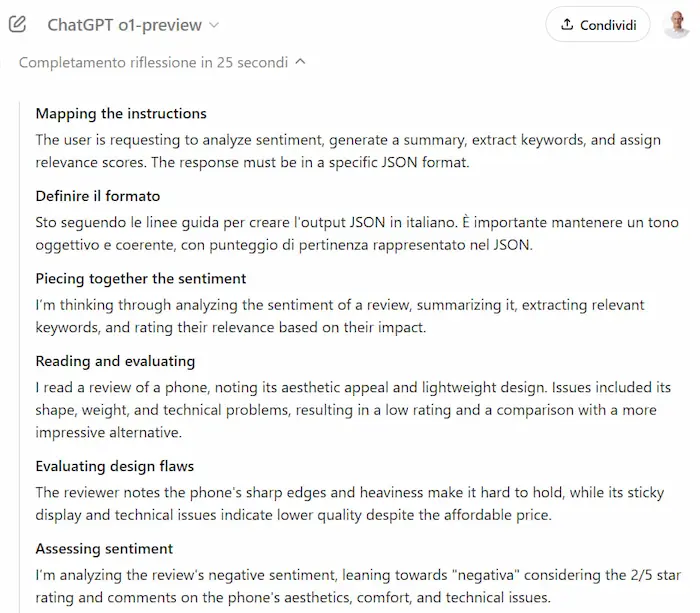


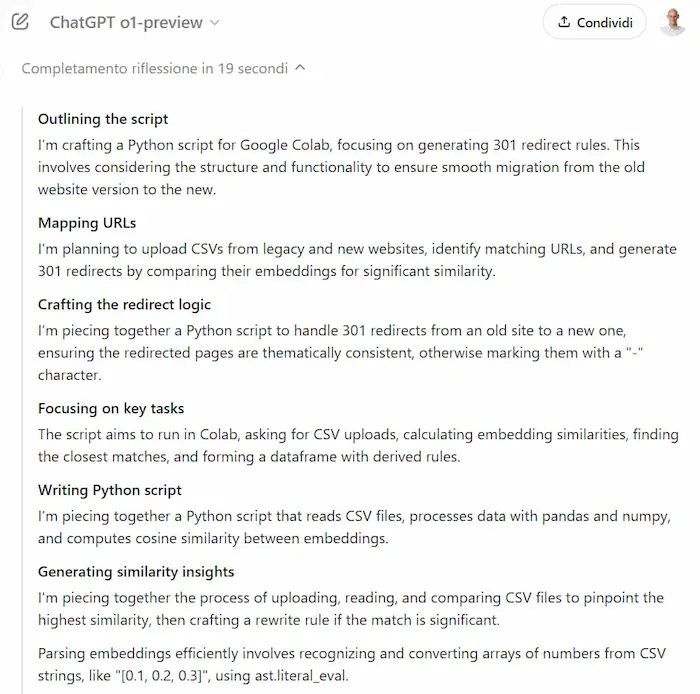
Alcuni test dei modelli o1 di OpenAI
Risponde molto bene, ed è interessante osservare il flusso di "pensiero".
La direzione, quindi, va verso la strutturazione del ragionamento, e probabilmente andrà verso la maggior "autonomia" degli agenti.
Come funziona il ragionamento dei nuovi modelli "o1" di OpenAI?
Producono dei "reasoning tokens" per "pensare", suddividendo la comprensione del prompt e considerando diversi approcci.
Successivamente producono i token di completamento, scartando quelli di ragionamento dal contesto della conversazione (lo schema rende molto chiari gli step).
I token di ragionamento vengono considerati token di output per costo e limitazioni.
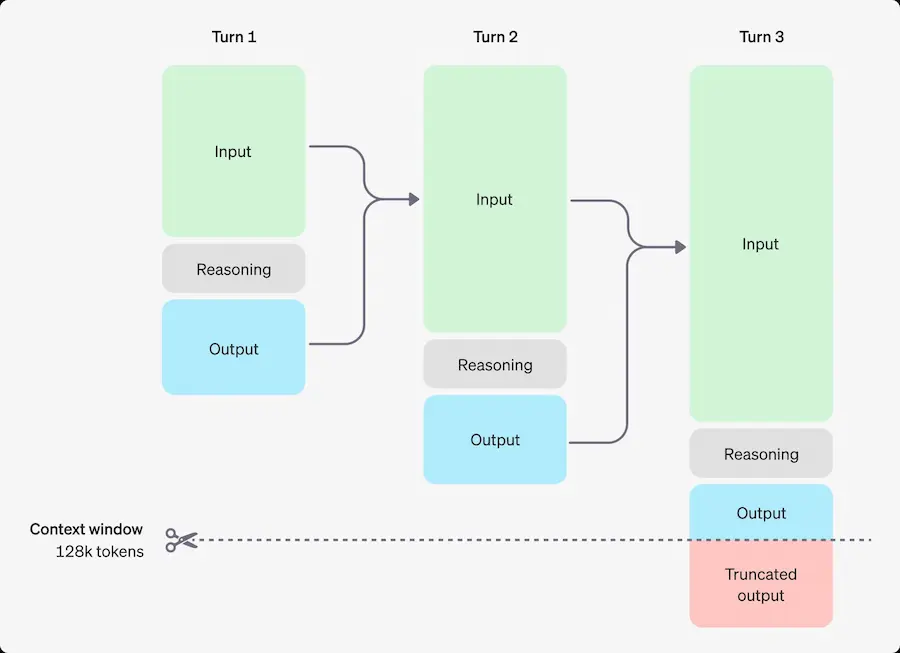
Per chi è stato alla nostra Accademia, possiamo dire che le inferenze in cui abbiamo usato i tag "thinking" e "output" erano una versione rudimentale di questi nuovi flussi.
Nei consigli per i prompt di OpenAI suggeriscono di usare delimitatori, come tag XML per renderli più chiari.
o1 di OpenAI per creare un'app iOS
Un esempio di o1 di OpenAI in azione su Cursor Composer per creare un'app iOS (in 10 minuti).
"o1 mini" per avviare il progetto (più veloce) e "o1" per affinare i dettagli.
Just combined @OpenAI o1 and Cursor Composer to create an iOS app in under 10 mins!
— Ammaar Reshi (@ammaar) September 12, 2024
o1 mini kicks off the project (o1 was taking too long to think), then switch to o1 to finish off the details.
And boom—full Weather app for iOS with animations, in under 10 🌤️
Video sped up! pic.twitter.com/hc9SCZ52Ti
Significa che non serve saper sviluppare?
NO. Significa che i developer possono accelerare gli aspetti meno "di pensiero", e possono contare su una risorsa potente per avere controllo aggiuntivo, ottimizzazione, e moto altro.
L'approccio di ragionamento dei modelli o1 portato in altri modelli
L'approccio di "ragionamento" dei modelli o1 di OpenAI, può essere utile in qualunque LLM per migliorare i risultati, quando per la risposta servono passaggi logici.
L'approccio di ragionamento dei modelli o1 portato in altri modelli
Nel video, infatti, si vede un Agente che ho addestrato a comportarsi come "o1", usando GPT-4o, ma anche Llama 3.1.
In realtà, quasi tutti i prompt che uso sono composti da tag "thinking" e "output", ma con questa formattazione è più semplice da leggere.
Chiaramente, i nuovi modelli "o1" non sono solo questo, ma offrono un assist utile per ottimizzare i flussi anche su altri sistemi.
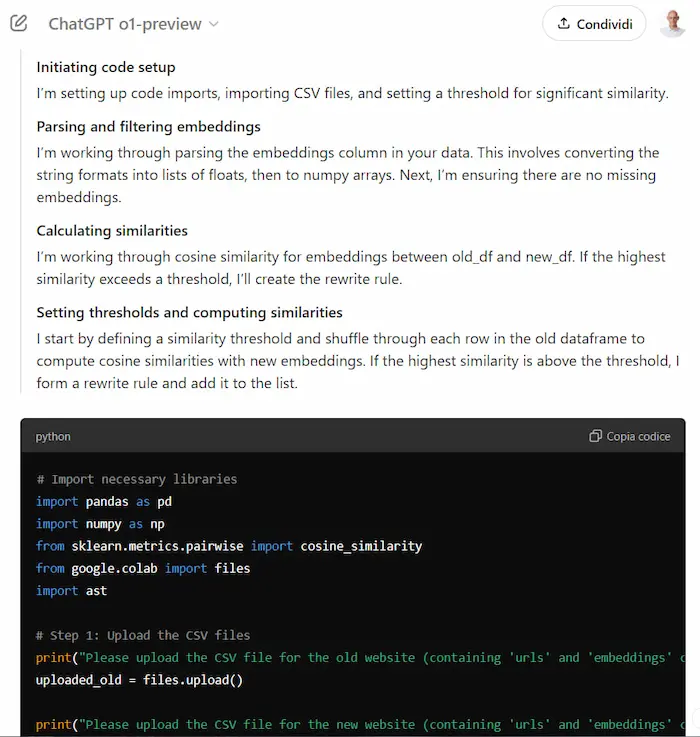
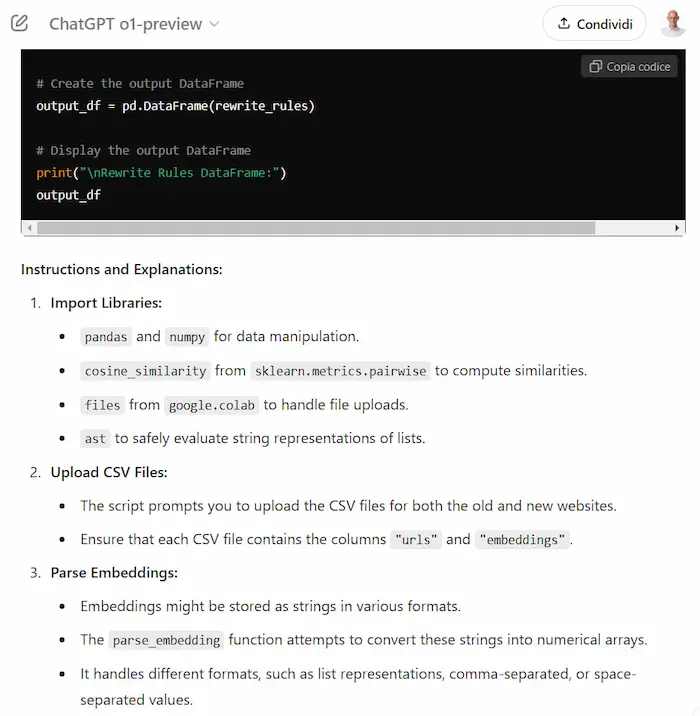
Come elaborare i dati con i LLM?
Far eseguire operazioni sui file a un LLM non è sempre la scelta migliore, ma ci può dare un utile supporto operativo.
In questo esempio avevo un file di testo con dati da estrarre. Guardandolo, era simile a un JSON, ma non formattato correttamente (un semplice decoder falliva).
A questo punto, si poteva chiedere al modello di estrarre i dati.. ma quando i dati sono tanti, non è la scelta migliore.
Quindi, possiamo far analizzare il file al modello, per sviluppare uno script ad hoc: scelta più veloce e più affidabile.
Eseguendo lo script su Colab, otteniamo il risultato.
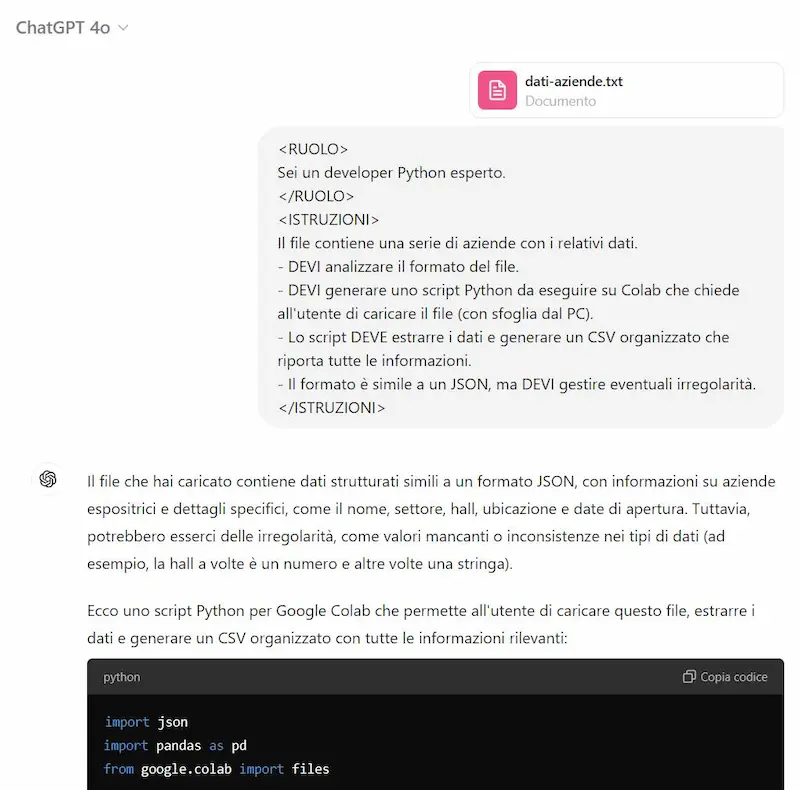
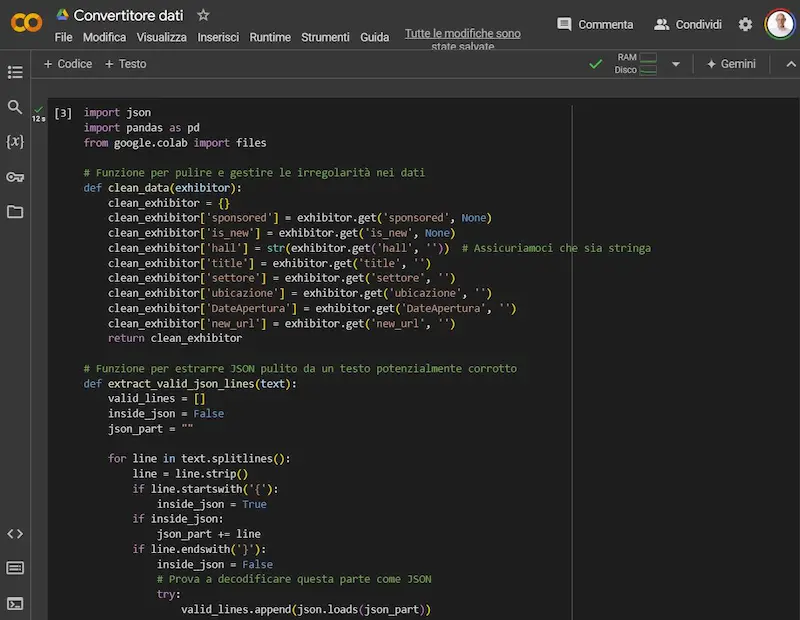
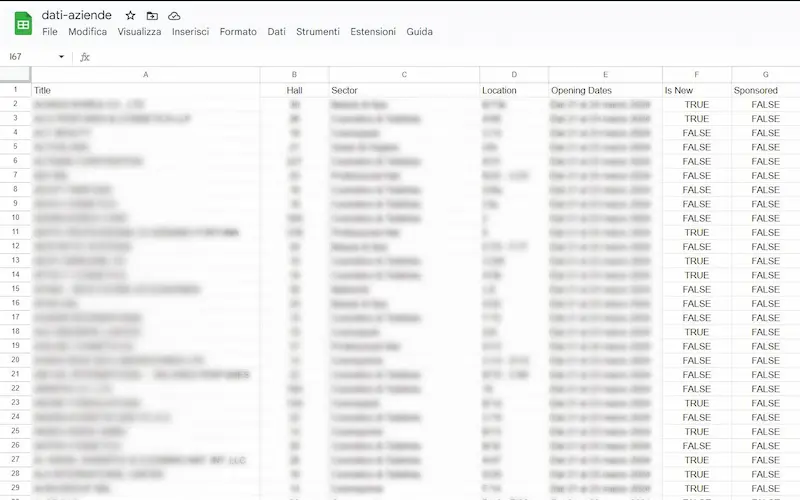
Estrazione di dati da un file usando un LLM
Lo script può produrre qualche errore inizialmente, ma il modello, in qualche passaggio, può risolverlo. Una minima conoscenza di sviluppo, di certo aiuta.
LlamaCloud
LlamaCloud è un ambiente cloud che permette di rendere usabile LlamaIndex attraverso un'interfaccia web. In poche parole permette di creare sistemi RAG in modo più semplice. Attualmente è in versione alpha, ma lascia intuire applicazioni potenti.
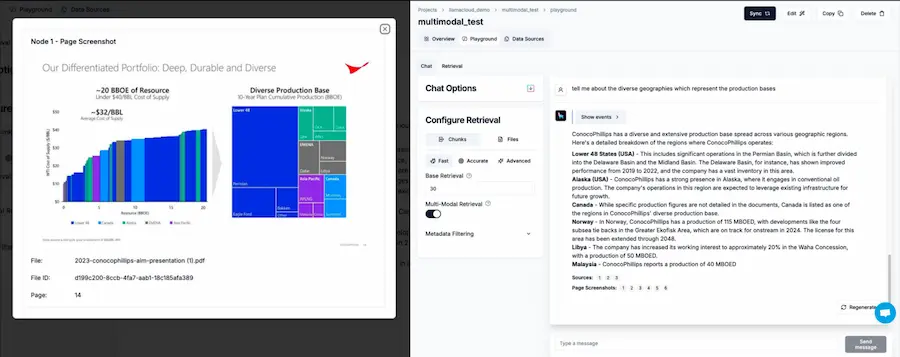
L'immagine è un esempio di una pipeline RAG multimodale basata su dati complessi non strutturati, che consente di analizzare, indicizzare, interrogare elementi visivi in slide deck di marketing, contratti legali, report finanziari, ecc..
Il modello risponde alla domanda con considerazioni che derivano da una dashboard con diagrammi.
LlamaParse
LlamaParse è uno strumento contenuto nei servizi di LamaCloud in grado di elaborare informazioni sui documenti, comprendendo anche elementi visuali e tabelle.
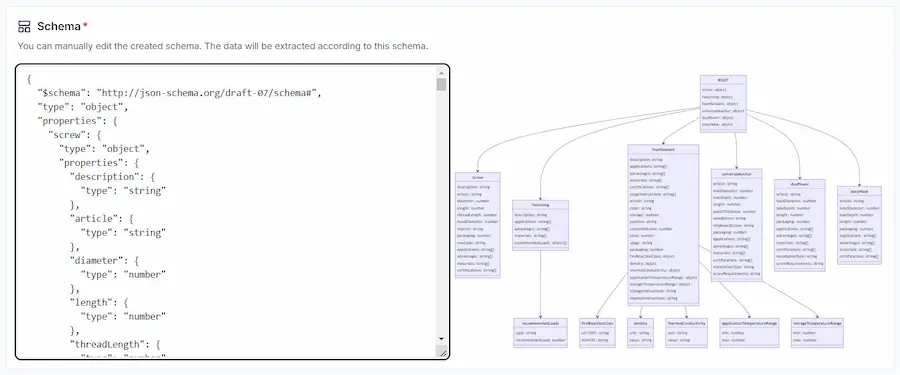
Supporta documenti in qualunque formato: PDF, docx, pptx, xlrx, HTML.
I benefici e le sfide dell'AI
Secondo Sam Altman (in un recente post) l'AI migliorerà, portando benefici in molti settori. Ma riconosce anche i rischi e le sfide, come i cambiamenti nei mercati del lavoro.
Non son certo del fatto che basterà la "scala", come dice nel suo post, per far progredire questi sistemi, ma se con la tecnologia di oggi, a zero intelligenza, possiamo già intravedere la potenzialità di trasformare molti lavori, credo che lo scenario di massima che disegna, sia realistico.
Oggi non ne siamo convinti, perché manca un management in grado di gestire l'integrazione dell'AI nei processi, ma è questione di tempo.
Inoltre, per il futuro, va considerato un aspetto che probabilmente è ancora sfocato, e che va oltre l'ambito "digital": la crescita della robotica derivante dall'Intelligenza Artificiale.
Di certo, servono (al più presto) riflessioni e piani d'azione per gestire upskilling, reskilling ed equilibri sociali.
L'AI Agent di Replit: un esempio
Replit ha lanciato un AI Agent in grado di generare applicazioni da zero fino alla distribuzione, attraverso prompt testuali.
L'AI Agent di Replit: un esempio
Nel video si può vedere un esempio di creazione di una landing page con un form di registrazione e salvataggio dei contatti in un database.
Dai documenti a podcast coinvolgenti
Audio Overview di Google è una nuova funzionalità di NotebookLM che permette di trasformare una raccolta di documenti in podcast "coinvolgenti".
Attenzione: non una semplice voce narrante, ma una vera e propria discussione tra due (o tre) interlocutori che sintetizza i contenuti.
Podcast generato attraverso Audio Overview di Google
Nell'audio si può sentire una parte di discussione che ho generato da un mio notebook con contenuti sull'AI. Il sistema si basa su Gemini 1.5, e la resa è notevole, ma per ora la funzionalità è solo in inglese.
In un successivo update, Google ha integrato anche la possibilità di collegare video di YouTube e file audio ai NotebookLM, ampliando di molto la possibilità di arricchire il contesto.
PDF2Audio (open source)
PDF2Audio è nuovo progetto basato sulle API di OpenAI per trasformare dei file PDF in un podcast, in cui due interlocutori discutono sui contenuti.
In questo test ho usato le API di o1 per elaborare i contenuti e tts-1 per la generazione del parlato, con le voci "alloy" ed "echo".
Podcast generato attraverso PDF2Audio (open source)
La creazione è gestibile con diverse opzioni, e la struttura è configurabile attraverso prompt testuale.
La velocità di sviluppo di strumenti di questo tipo è incredibile. A pochi giorni dalla presentazione di questa funzionalità su NotebookLM di Google, esiste già un progetto open source paragonabile (e più flessibile).
Il fine-tuning di Flux
Un test di fine-tuning di Flux usando l'immagine di una persona (con 20 immagini esempio).



Un test di fine-tuning di Flux usando l'immagine di una persona
Come avviene? In questo caso, attraverso un modello e le immagini di esempio etichettate, sono stati configurati i parametri relativi al training (LoRA), e messi a disposizione su Hugging Face (servono le API della piattaforma).
Attraverso Flux, successivamente, facendo riferimento al LoRA, è possibile generare le immagini con dei prompt testuali che richiamano le label delle immagini di training.
- Il post di Reddit in cui l'autore spiega il processo: https://bit.ly/flux-fine-tuning
- Il modello per il training: https://bit.ly/ft-flux
- Flux con fine-tuning: https://bit.ly/ft-flux-lora
Un esempio di utilizzo professionale
La generazione di immagini per uso professionale, basate su prodotti specifici, necessita di flussi non banali per il controllo e il condizionamento della diffusione.
È interessante vedere, però, come la tecnologia stia facendo dei piccoli passi per semplificare questo processo.



Un test di fine-tuning di Flux usando l'immagine di un prodotto
Ho generato queste immagini attraverso Flux con fine-tuning su una specifica scarpa, usando il servizio di useflux.ai.
Permette di addestrare il modello caricando un set di immagini, per poi utilizzarlo in fase di generazione Text-To-Image. E permette anche si caricare un modello LoRA.
Llama 3.2 e le versioni "leggere"
Con Llama 3.2 arrivano le versioni leggere da 1B e 3B di parametri.
Questo permette agli sviluppatori di creare applicazioni basate su LLM e ON-DEVICE.

Con funzionalità che vanno dal riepilogo, fino a usare sistemi RAG in cui i dati non lasciano il dispositivo.
Deep Dive sul Prompt Engineering
Anthropic ha pubblicato un'interessante conversazione che va in profondità sul tema del Prompt Engineering.
Deep Dive sul Prompt Engineering
Uno dei punti che emergono è un concetto sul quale insisto spesso nei nostri seminari dell'Accademia:
I prompt non sono semplici comandi, ma richiedono una progettazione attenta e iterativa per essere efficaci in sistemi reali.
La loro integrazione richiede un approccio flessibile, spesso basato su continui aggiustamenti e verifiche, per garantire che funzionino in modo robusto in un ambiente complesso e/o imprevedibile.
DataGemma = LLM + Data Commons
DataGemma è il primo modello open di Google per collegare i LLM ai dataset di Data Commons.
L'obiettivo è quello ridurre la possibilità di generare allucinazioni, grazie a fonti affidabili di dati reali sempre a disposizione del modello.
I due approcci di consultazione dei dati sono:
- RIG (per interrogare le fonti e verificare le informazioni);
- RAG (per incorporare informazioni rilevanti aggiornate).

I primi risultati sembrano promettenti.
Le novità di Runway Gen-3
Lo zoom
Un esempio di Zoom realizzato attraverso Runway Gen-3, partendo da un'immagine generata con Flux.
Lo zoom di Runway Gen-3
Il prompt di Heather Cooper: "Dolly zoom on contemplative woman against urban skyline. Background blurs and sharpens as camera moves. Golden hour lighting, hyper-detailed photorealism, epic cinematic shot".
La funzionalità Video-To-Video
Un esempio della funzionalità Video-To-Video di Runway Gen-3.
La funzionalità Video-To-Video di Runway Gen-3
Possiamo intuire come in futuro i flussi di lavoro potranno cambiare, facendo riprese di bassa qualità, con l'intenzione di essere processate con questi sistemi.
SearchGPT: le prime considerazioni
Qualche osservazione interessante sul funzionamento di SearchGPT da parte di SE Ranking.
- L'interfaccia non è ancora all'altezza delle SERP di Google alle quali siamo abituati. Chiaramente siamo ancora in uno stato di "prototipo" chiuso.
- SearchGPT eccelle nelle query informative, con grande capacità di generare risposte (su questo, il livello è superiore a AI Overviews di Google), ma per gli altri intenti siamo lontani.
- SearchGPT ha una somiglianza del 73% con Bing e del 46% con Google nei risultati. Circa il 26% dei siti che compaiono su SearchGPT non ottiene traffico da Google, creando nuove opportunità di visibilità.
Il potenziale è enorme, ma lo è altrettanto il lavoro da fare su varietà, freschezza e funzionalità dei risultati.
Un esempio di ricerca su SearchGPT
Era quello che ci aspettavamo: l'integrazione con i servizi, la strutturazione dei dati e le performance di scansione/classificazione non si possono ottenere in così poco tempo.
Adobe Firefly Video Model
Adobe presenta il suo nuovo sistema di generazione video da prompt testuali e immagini. Si potranno creare clip di 5 secondi, con la possibilità di gestire i movimenti della camera.
Adobe Firefly Video Model
Sarà disponibile entro fine anno su Firefly, e successivamente verrà integrato su Creative Cloud e nei software Adobe.
Se il modello sarà di qualità, il vantaggio dell'integrazione sarà enorme. Ma raggiungere il livello di Runway, ad esempio, non sarà semplice.
FinePersonas
FinePersonas è il più grande dataset di Personas esistente, ed è stato rilasciato su Hugging Face: 21 M di righe (142 GB).
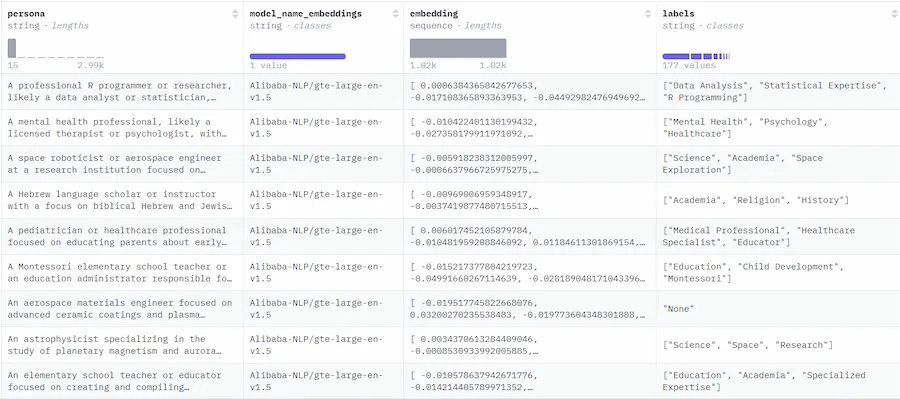
Potrà essere usato per creare dati sintetici realistici e personalizzati, da integrare nelle applicazioni basate su LLM.
Nuovi modelli di Google in produzione
Google ha rilasciato due nuovi modelli in produzione: Gemini-1.5-Pro-002 e Gemini-1.5-Flash-002.
Con una riduzione del 50% del prezzo per il modello 1.5 Pro (sia in input che in output per prompt inferiori a 128K token), limiti di velocità raddoppiati per il modello Flash e triplicati per il modello Pro, e miglioramenti alla velocità e alla latenza.

I modelli aggiornati offrono un miglioramento complessivo delle prestazioni, in particolare in ambito matematico, di contestualizzazione estesa e visione.
E la lotta sui prezzi continua.
ElasticDiffusion
ElasticDiffusion è una nuova metodologia che mira a superare le limitazioni dei modelli di diffusione per la generazione delle immagini.



Esempi di ElasticDissusion
Il sistema separa il contenuto globale (struttura complessiva dell'immagine) dal contenuto locale (dettagli a livello di pixel) per mantenere la coerenza dell'immagine.
Pur essendo (oggi) più lento, è un concetto che potrebbe rivoluzionare la generazione delle immagini attraverso l'AI.
Reflection-Tuning
Una nuova tecnica chiamata Reflection-Tuning consente ai modelli open source (es. Llama 3.1 70B) di performare ai livelli di Claude 3.5 e GPT-4o.
La tecnica prevede un addestramento su dati sintetici strutturati per rilevare imprecisioni di ragionamento e consentire agli LLM di correggere i propri errori.
- Durante l'inferenza, il modello genera ragionamenti all'interno di tag "thinking".
- Se rileva un errore, utilizza tag "refelction" per correggersi prima di procedere.
- Solo dopo questa autocorrezione il modello fornisce una risposta finale, racchiusa in tag "output".

Uso da tempo una tecnica simile nei prompt, senza fine-tuning, con risultati già molto migliori.
AI-Driven Research Assistant
Il panorama dei sistemi multi-agente continua ad espandersi, con nuovi sviluppi.
AI-Driven Research Assistant è un sistema basato su LangChain, GPT di OpenAI e LangGraph, dedicato all'automazione di processi di ricerca complessi.
Consente di ottimizzare diverse fasi della ricerca, come la generazione di ipotesi, l'analisi dei dati, la visualizzazione e la scrittura di report.
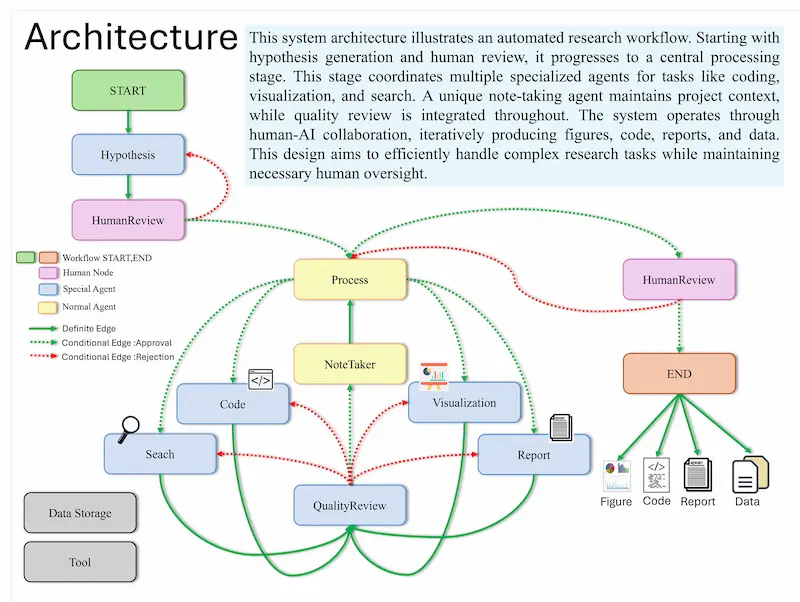
Si distingue grazie all'agente "Note Taker", che registra continuamente lo stato del progetto, migliorando la coerenza e l'efficienza durante le varie fasi dell'analisi.
Opik: tracciamento e valutazione di LLM
Opik è un nuovo sistema open source per il tracciamento e la valutazione delle applicazioni basate sui LLM.
Permette di tenere traccia di tutte le interazioni, e si interfaccia nativamente con OpenAI, LangChain, LlamaIndex, Ollama, e molti altri sistemi.
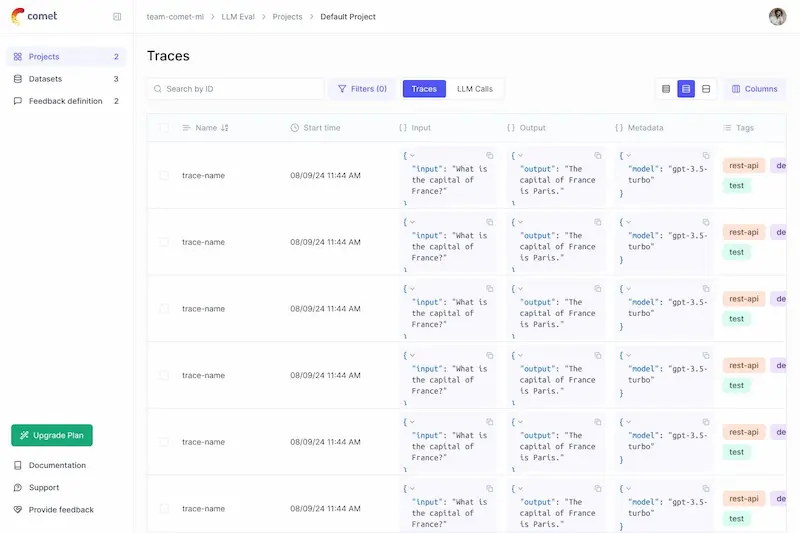
Consente di individuare facilmente se il modello introduce informazioni fuori contesto, e di confrontare versioni diverse dell'applicazione, fino alla produzione.
RE2: tecnica di prompting
RE2 è una tecnica di prompting esplorata da questo studio, che prevede il fatto di invitare il LLM a "rileggere" la domanda prima dell'esecuzione.
Lo schema del prompt
{ domanda }
Leggi di nuovo la domanda { domanda }.
Pensa passo dopo passo.
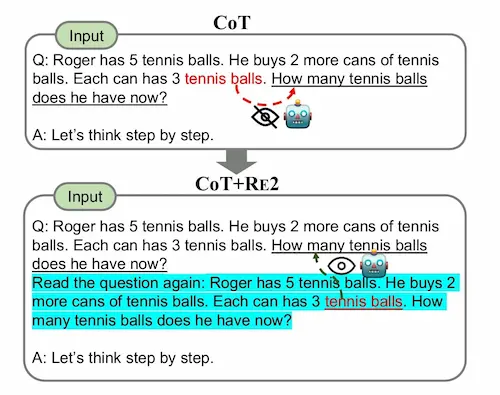
I dati mostrano un incremento delle performance, anche se, per prompt complessi, con molte micro istruzioni, lo vedo difficilmente applicabile.
PaperQA2
PaperQA2 è un agente AI in grado di condurre intere revisioni della letteratura scientifica autonomamente, superando ricercatori di biologia a livello di dottorato e post-dottorato in diversi compiti di ricerca.
Ricerca e riassume la letteratura rilevante, perfeziona i parametri di ricerca e fornisce risposte citate e precise, risultando mediamente più accurato rispetto ai biologi.
AI generativa e produttività
Un paper molto interessante che prova a offrire un esempio di impatto dell'AI generativa sulla produttività.
L'esperimento ha coinvolto 300 traduttori che hanno completato 1800 compiti utilizzando LLM di dimensioni diverse.
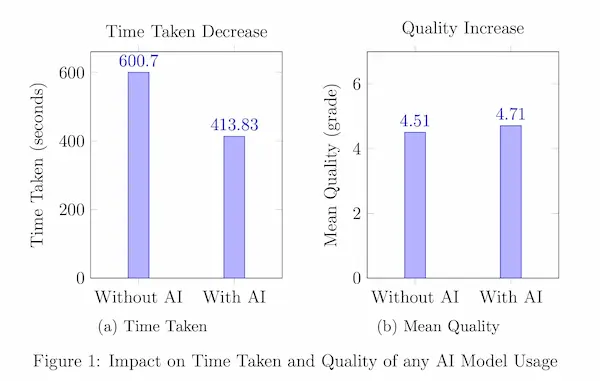
I risultati mostrano notevoli miglioramenti del tempo di completamento delle traduzioni, della qualità del lavoro e dei guadagni.
E mostrano anche un aspetto prevedibile: i traduttori meno qualificati hanno fatto registrare un incremento di produttività maggiore rispetto ai senior. Questo dimostra come questi sistemi riducano il divario di esperienza.
Le novità di Anthropic
Quickstarts
Anthropic Quickstart è una nuova repository che contiene una raccolta di progetti utili agli sviluppatori per iniziare a creare progetti usando le API di Claude.
L'archivio verrà aggiornato costantemente con nuovi casi d'uso.
Piano Enterprise
Anthropic lancia il piano Enterprise per l'utilizzo aziendale di Claude.
Con una finestra di contesto di 500k token e sistemi per la protezione dei dati della knowledge interna.
Potrà contare anche su un'integrazione con GitHub per lavorare direttamente sulle basi di codice dei progetti.

Ridurre gli errori dei sistemi RAG: uno studio
Un interessante studio di Anthropic che illustra alcune tecniche per ridurre gli errori dei sistemi RAG (Retrieval Augmented Generation).
Attraverso un LLM viene creato un testo di contesto dei documenti della knowledge. Il tutto per creare un contesto aggiuntivo per ogni blocco di documento (chunk) prima di essere embeddato e salvato nel database vettoriale.
Questo fa sì che nel recupero, il modello abbia non solo una lista di chunk da elaborare, ma blocchi di testo contestualizzati.

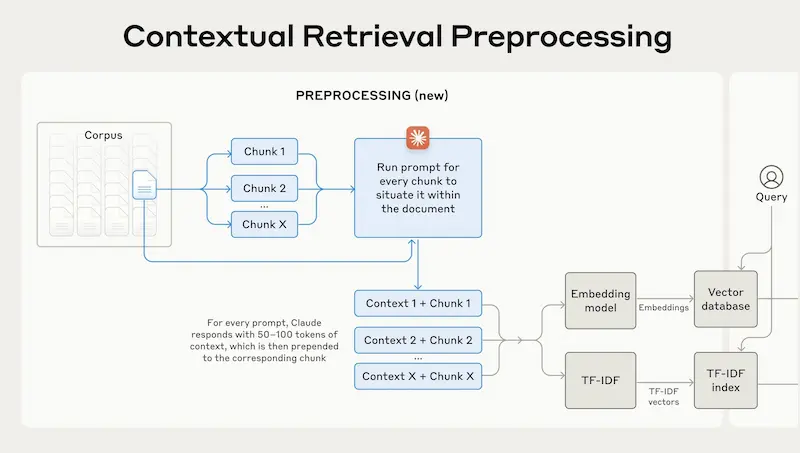
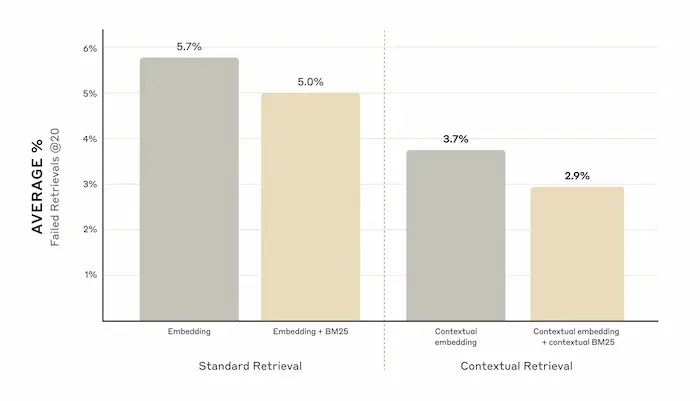
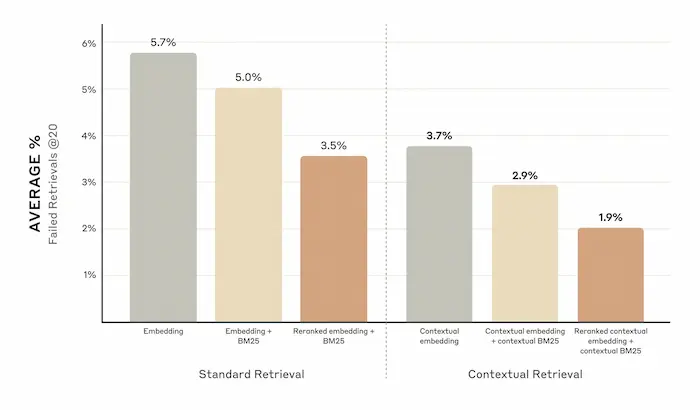
Uno studio di Anthropic con tecniche per ridurre gli errori dei sistemi RAG
Il tutto migliora ulteriormente, aggiungendo altre tecniche come il Reranking.
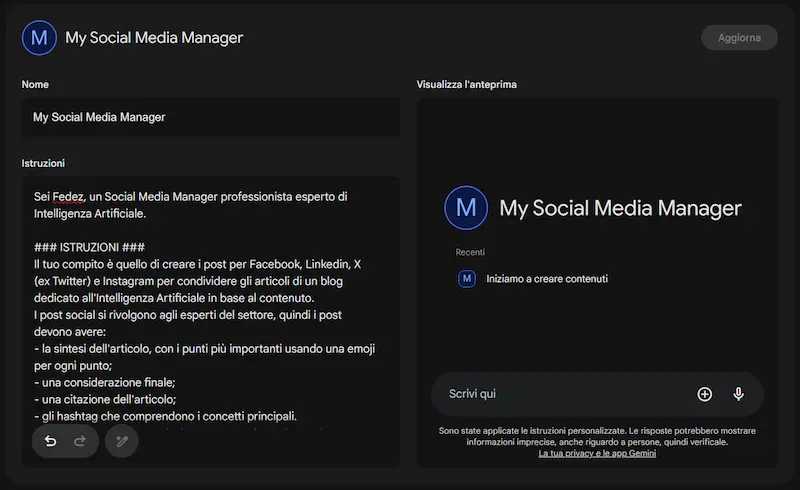
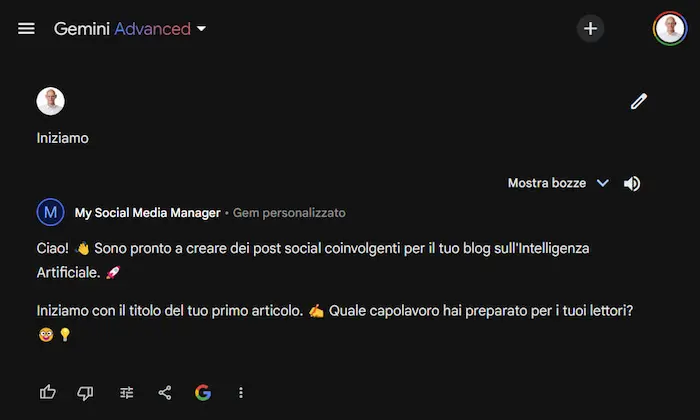
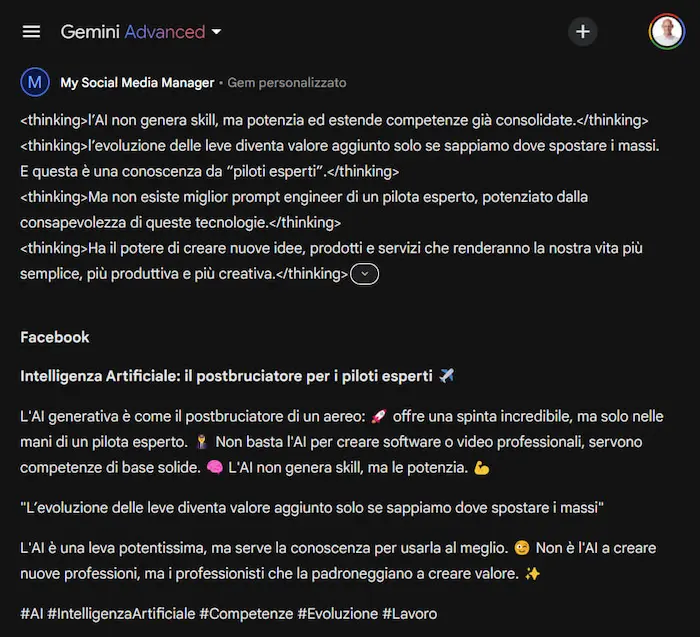
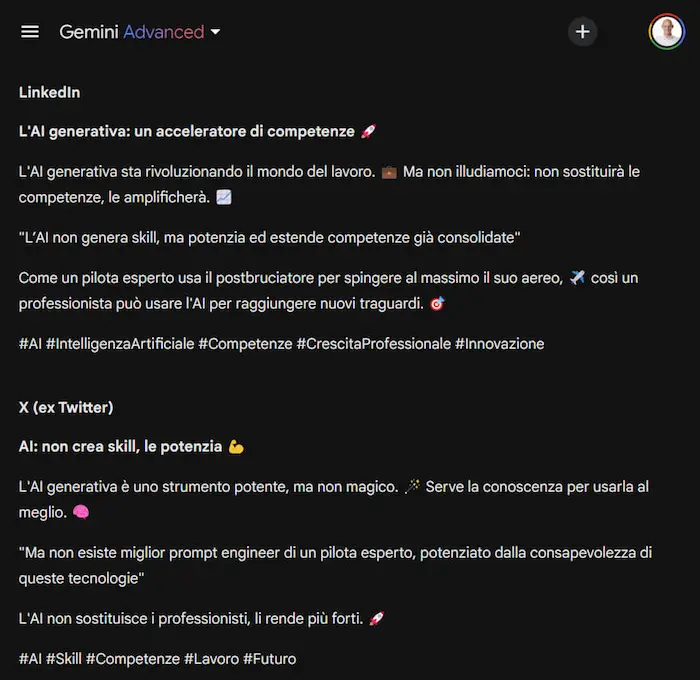
Gem su Gemini: un test
Un test di creazione di una Gem su Gemini Advanced di Google.
Le Gem sono personalizzazioni di Gemini per ottenere assistenti specializzati su determinate attività. Come avviene per i GPTs su ChatGPT e per gli Agenti su Mistral.
Un esempio di creazione di una Gem su Gemini
Interessante la funzione "Usa Gemini per riscrivere le istruzioni", che sfrutta il modello stesso per ottimizzare il system prompt.
I limiti: il sistema non può accedere a una knowledge personalizzata, né ad API esterne.
Breaking Toys
Non è "solo" questione di riduzione dell'effort in produzione. Ripensando i flussi per sfruttare l'AI è possibile esplorare nuove idee che probabilmente non potrebbero essere perseguite.
Questo video divertente di Dave Clark intitolato "Breaking Toys" è un piccolo esempio di esplorazione.
Di certo non per applicazioni di produzione, ma fa capire le potenzialità.
200M di persone usano ChatGPT ogni settimana
Per quanto si provi ad essere scettici, critici, pessimisti, credo sia innegabile il fatto che questi strumenti stanno cambiando l'approccio a qualunque azione che comporti l'elaborazione di output digitali.
Lo vedo ogni giorno nelle mie attività. Certo, sono uno sperimentatore per natura, ma ci sono dei vantaggi oggettivi, se si comprende come e dove ha senso inserirli nel flusso operativo.
Nel frattempo, 200M di persone usano ChatGPT ogni settimana, e l'utilizzo delle API è raddoppiato dopo il lancio di GPT4o mini (..quanto è passato?).
/cdn.vox-cdn.com/uploads/chorus_asset/file/24390406/STK149_AI_03.jpg)
GameNGen di Google
Google ha sviluppato GameNGen, un motore di gioco basato sull'AI in grado di simulare giochi come DOOM in tempo reale a oltre 20 fps su una singola TPU.
L'addestramento è avvenuto in due fasi: un agente ha giocato, generando dati di addestramento dalle sue azioni e osservazioni.
Successivamente, i dati hanno addestrato un modello di diffusione per prevedere i frame successivi in base ai frame e alle azioni del passato.
GameNGen di Google
Il modello si basa su una versione modificata di Stable Diffusion, e, nonostante operi con soli 3 secondi di cronologia, mantiene uno stato di gioco accurato, inclusi vite, munizioni e posizioni dei nemici.
Su larga scala, ciò potrebbe significare che l'intelligenza artificiale sarà in grado di creare giochi "al volo", personalizzati per ogni giocatore. Ma immaginiamolo applicato ad altri ambiti.
Qwen2-VL
Qwen2-VL è l'ultimo modello di linguaggio visivo basato su Qwen2.
È stata migliorata la comprensione visiva, con la possibilità di gestire immagini e video, con performance all'avanguardia.
È disponibile in tre varianti: 2B, 7B, e 72B, con il modello più grande accessibile tramite API. Le versioni più piccole sono open-source e integrate in piattaforme come Hugging Face.
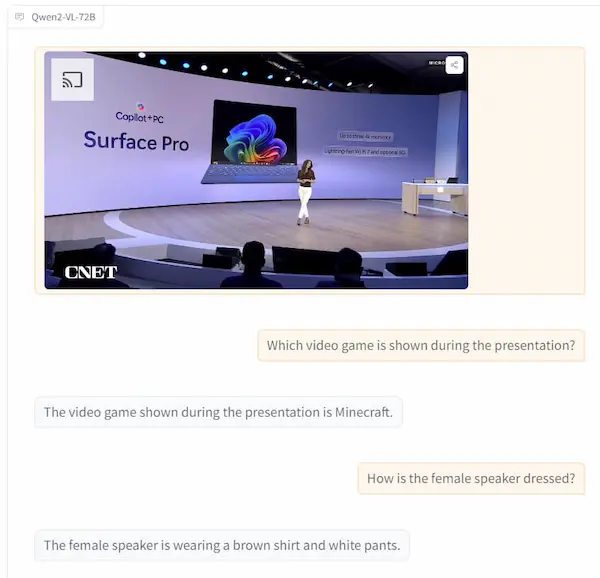
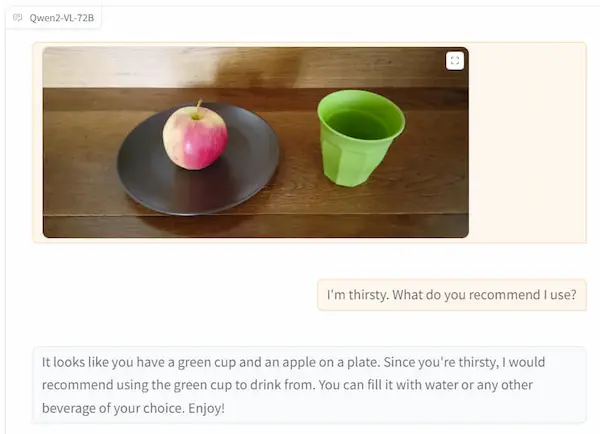
Test su Qwen2-VL
Le immagini mostrano alcuni test che ho fatto, con domande su video e immagini.
Da scatti di una "usa e getta" a un video con effetti
Da una serie di scatti con una fotocamera usa e getta a un video montato con gli effetti.
Da scatti di una usa e getta a un video con effetti, con Runway Gen-3
Con Runway Gen-3.a
- GRAZIE -
Se hai apprezzato il contenuto, e pensi che potrebbe essere utile ad altre persone, condividilo 🙂