Generative AI: novità e riflessioni - #8 / 2024
Come si usa FLUX? + un ampio focus sul modello. Risorse e corsi gratuiti. Le novità di Mistral, OpenAI, Google e Anthropic. L'automazione della ricerca scientifica, l'AI per il cambiamento climatico.. e molto altro.


Buon aggiornamento, e buone riflessioni..
[corso gratuito] Generative AI For beginners
Microsoft ha pubblicato una nuova versione del suo corso "Generative AI For beginners" su YouTube (4 ore e 20 minuti di seminari).
Dalle basi al prompt engineering. Dalle applicazioni chat, fino al fine-tuning, alla vettorializzazione (embeddings) e ai sistemi RAG (Retrieval Augmented Generation).
Generative AI For beginners - Microsoft
Uno dei contributi più interessanti disponibili online gratuitamente.
[risorsa gratuita] Trascrizione video multilingua
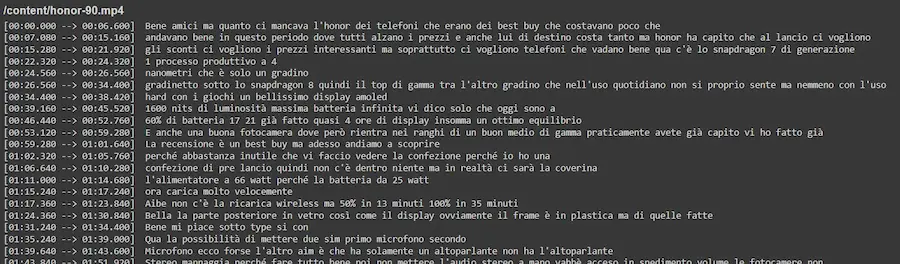
Grazie a questo Colab è possibile usare Whisper per trascrivere qualunque video (presente su YouTube o caricato su Drive), in qualunque lingua.
È semplicissimo da usare: non serve modificare il codice perché è tutto configurabile attraverso un'interfaccia su Colab.
Nell'immagine si può vedere un esempio di trascrizione con il timestamp.
Con sistemi come questo, creare delle automazioni diventa molto più semplice.
Uno spot pubblicitario completamente generato con modelli di AI
Un esperimento di generazione di uno spot pubblicitario usando Flux per la generazione delle immagini (segue un approfondimento), Runway Gen-3 per animarle, Udio per la componente sonora e ElevenLabs per la voce narrante.
Uno spot pubblicitario generato con Flux + Runway + Udio + ElevenLabs
L'editing video è stato eseguito con CapCut. Il tutto in 2 ore circa.



Alcune delle immagini generate con Flux
È solo un esempio, ma abbastanza significativo. Se non per creare uno spot completo, per capire le potenzialità di questi supporti in fase di produzione. E miglioreranno.
Flux: test e come usarlo
Alcuni test di Flux, una nuova famiglia di modelli Text-To-Image sviluppata dagli stessi creatori di Stable Diffusion.
I modelli sembrano rappresentare un notevole passo in avanti nella generazione delle immagini, per qualità e aderenza al prompt.
Sono state rilasciate 3 versioni: pro (alte performance), dev (modello open per applicazioni non commerciali) e schnell (il più veloce, pensato per applicazioni in locale).



Test di Flux
Le performance sono altissime, come si vede dalle immagini.
I modelli sono stati, inoltre, ottimizzati in alcune varianti, ad esempio Flux Realism LoRA. Le immagini che seguono rappresentano alcuni test: sono state generate attraverso un prompt testuale, e up-scalate con Magnific AI.



Flux Realism LoRA + Magnific AI
Per quanto ormai sia dato per scontato, trovo sempre il processo tecnicamente sorprendente!

Come provare Flux
5 modi per provare Flux in modo semplice: su Replicate(via browser), su FAL(via browser), su Krea.ai(via browser), su Freepik(via browser), su Colab(duplicando il notebook e modificando il prompt). Su FAL, è possibile provare anche Flux Realism LoRA e addestrare il modello su specifiche immagini, in modo da ottenere risultati specifici (Train Flux LoRA).
Midjourney + Runway Gen-3
Immagini generate attraverso Midjourney, animate attraverso Runway Gen-3, per una dimostrazione della cura dei dettagli del modello.
Midjourney + Runway Gen-3
Direi che il livello è sempre più alto, anche in modalità Image-To-Video.
Midjourney 6.1 + nuovo editor
Midjourney, nel frattempo ha rilasciato la versione 6.1 del suo modello generativo.
- Migliora la qualità dell'immagine, la coerenza e il testo.
- Include nuovi sistemi di upscaling e personalizzazione.
- È più veloce del 25% nella generazione di immagini standard.
È stata rilasciata, inoltre, la nuova interfaccia web per la generazione e la modifica delle immagini, aperta a tutti gli utenti.
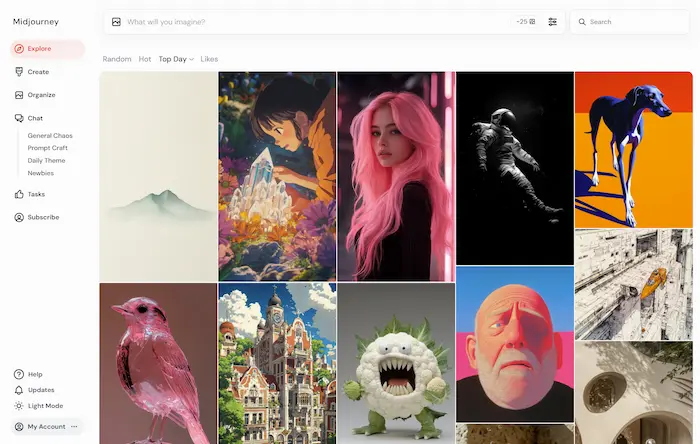

La nuova interfaccia web di Midjourney
Ci avviciniamo a un'interazione semplice anche con il modello che probabilmente è ancora il più potente.
Quello che segue è un esempio di video generato che sfrutta la qualità delle immagini di Midjourney v. 6.1, che vengono animate da Runway Gen-3. La componente audio deriva da Udio v 1.5.
Video generato usando Midjourney 6.1, Runway Gen-3 e Udio
Come sempre, si può discutere sui dettagli, ma credo che sia sempre più chiaro il livello che si sta raggiungendo.
Gli agenti autonomi di Mistral
Mistral rilascia la possibilità di creare agenti autonomi basati su LLM per interazioni e funzionalità complesse.
È possibile creare gli agenti attraverso un'interfaccia web o via API.
Gli agenti, successivamente, possono essere usati e possono interagire tra di loro attraverso la Chat di Mistral o via API.
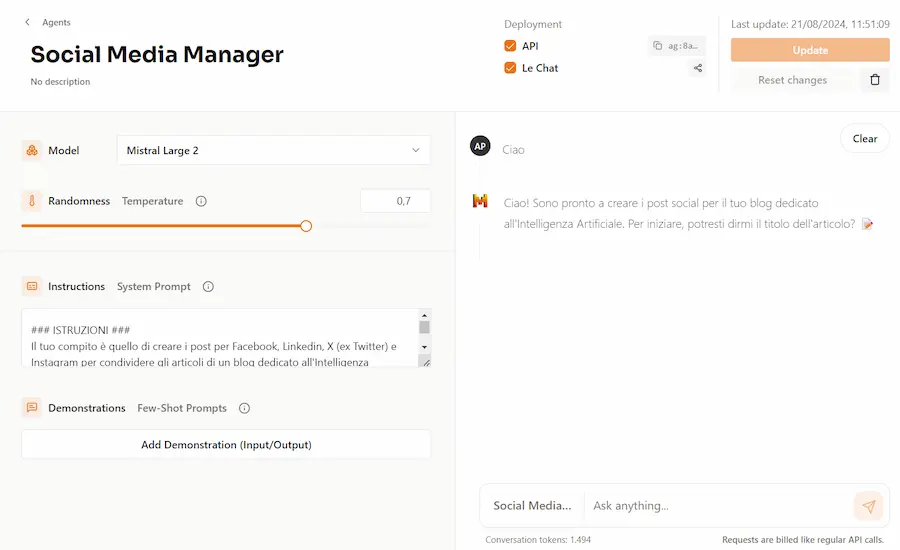
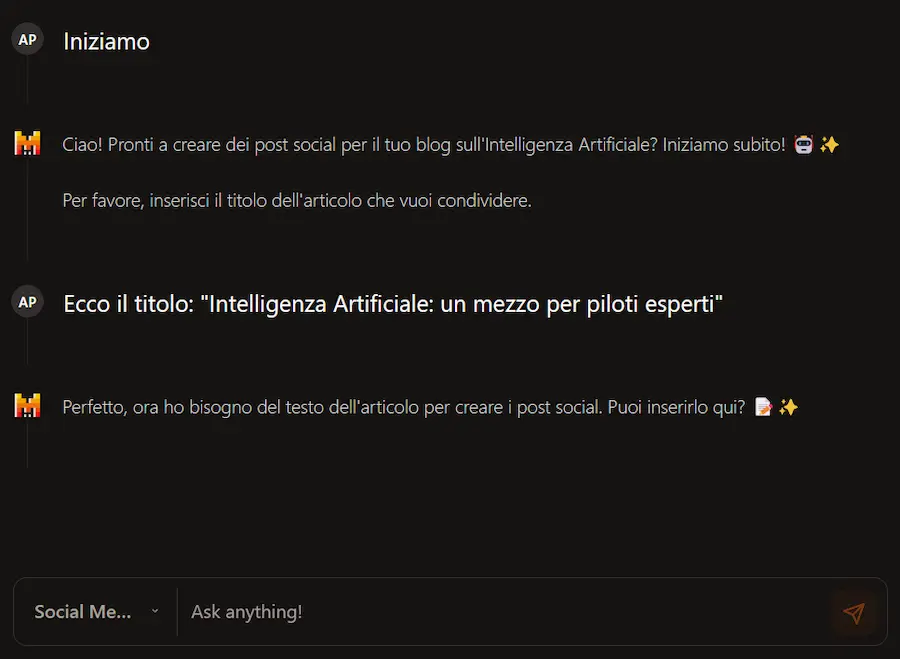
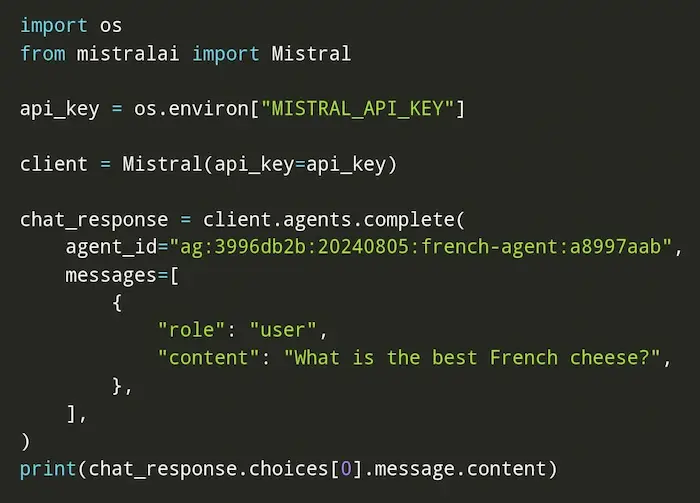
Gli agenti autonomi di Mistral
Possiamo dire che è un interessante mix tra GPTs e API Assistant di OpenAI. Con un grande vantaggio: l'entità dell'agente rimane unica, e può essere usata nella chat e via API.
Gemini Live: ottime intenzioni con qualche contrattempo
Sulla scia della modalità conversazionale di OpenAI, anche Google rilascia Gemini Live.
Anche in questo caso, si tratterà di una conversazione senza turni prestabiliti: sarà possibile interrompere l'assistente in ogni momento, semplicemente.. parlando.
Avrà 10 nuove voci, potrà interagire con la fotocamera dello smartphone e con le applicazioni Google.
Per ora sarà solo in lingua inglese e su Android.

Sembra che gli assistenti che avremmo voluto ai tempi di Alexa e Google Assistant stiano arrivando.
La demo durante il Made by Google è stata d'effetto, anche se non è mancato il momento di imbarazzo con i tentativi falliti nell'interazione multimodale.
Gemini Live nella presentazione del #MadeByGoogle.. con qualche momento di imbarazzo
Anche se c'è il vantaggio dell'integrazione con le applicazioni di Google, siamo ancora indietro rispetto a ChatGPT.
La cache per i prompt di Claude
Anthropic rilascia la cache per i prompt su Claude.
- Permette di ridurre i costi del 90%, e la latenza dell'85%.
- La scrittura di token nella cache è più costosa del 25% rispetto a un normale input.
- L'uso di un input già in cache costa il 10% di un input di base.
L'utilizzo, via API, avviene semplicemente aggiungendo un parametro alla chiamata e all'header.

Queste funzionalità permettono di ottimizzare moltissimo le applicazioni. Mentre la lotta dei prezzi continua.
Le performance di Gemini 1.5 Pro
L'ultima release di Gemini 1.5 Pro è stata (per un breve periodo, fino al rilascio di agosto di OpenAI) in prima posizione nella Chatbot Arena Leaderboard.
Ho fatto qualche test, perché fino a questo momento il modello di Google non mi aveva mai convinto.
Devo dire che i risultati mi hanno stupito: finalmente ho trovato la precisione nel rispettare i prompt e nel generare output.
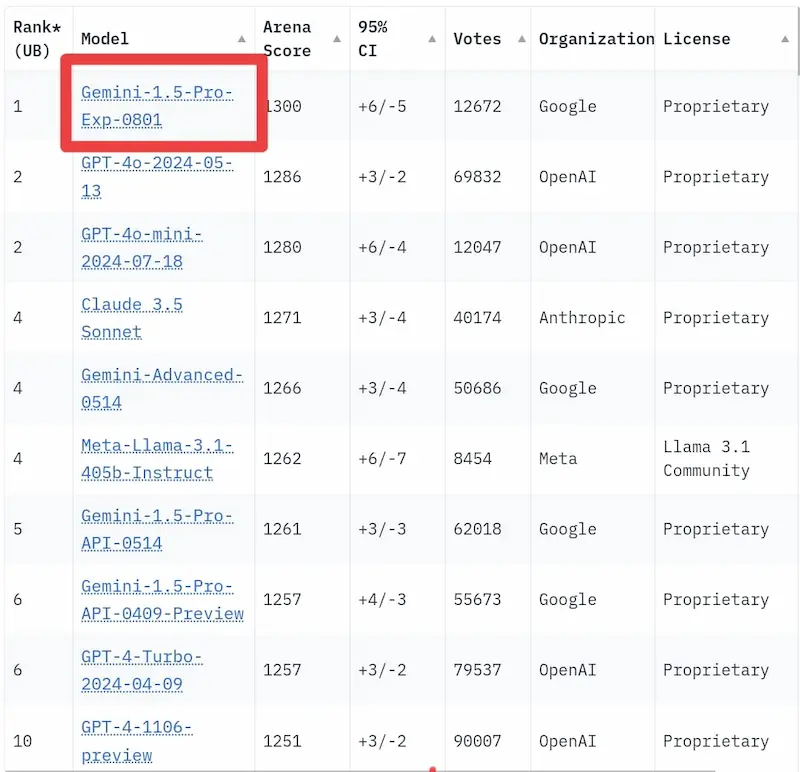
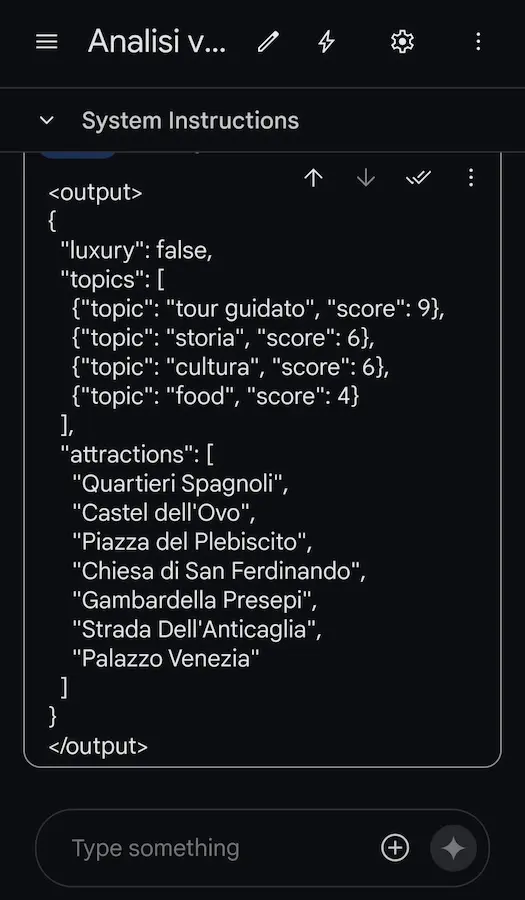
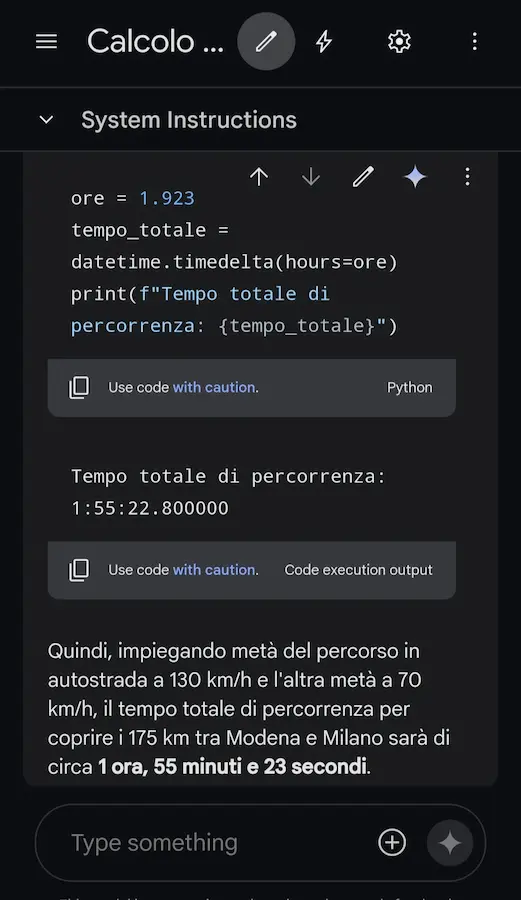
Test su Gemini 1.5 Pro
È stata aggiunta anche la possibilità di sviluppo ed esecuzione di codice per usare calcoli precisi nelle risposte (segue un esempio).
Gemini 1.5 Flash
Google prova ad aggredire il mercato degli LLM, con prezzi bassi e funzionalità per Gemini 1.5 Flash.
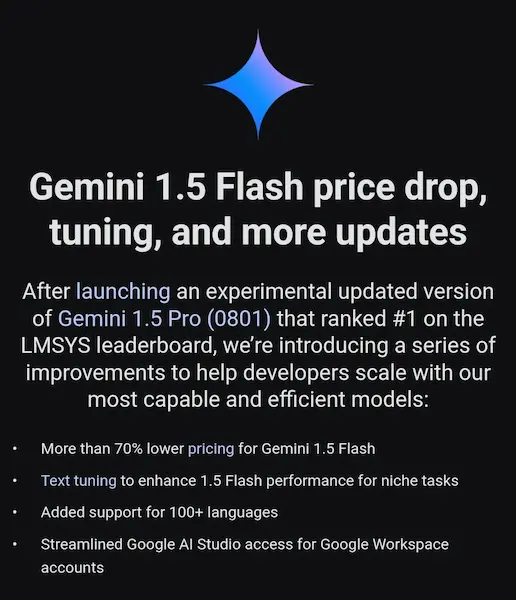
In effetti i prezzi sono più bassi di GPT-4o mini.
Ma le performance?
Da ricordare, inoltre, che OpenAI ha la funzione "batch".
I rilasci di fine agosto di Gemini
Ad integrazione dei punti precedenti, Google, a fine agosto, ha rilasciato 3 nuovi modelli sperimentali, tra i quali un nuovo upgrade di Gemini 1.5 Pro.
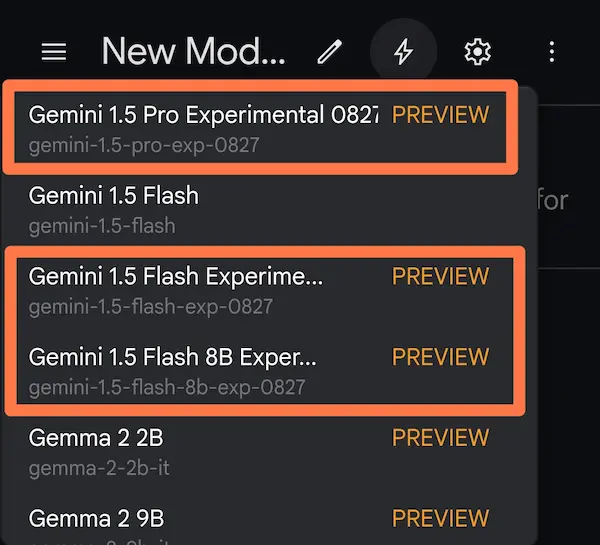
I primi test sul mio benchmark di riferimento (anche usando la JSON mode e l'esecuzione del codice) hanno dato risultati ottimi.
L'analisi dei dati di Gemini
Gemini (versione chatbot), con gli ultimi aggiornamenti, è migliorato notevolmente, introducendo, come visto in precedenza, qualcosa di molto simile a Code Interpreter di ChatGPT. I diagrammi che si vedono nell'esempio che segue, sono interattivi, modificabili e scaricabili.
L'analisi dei dati di Gemini
Siamo al livello dell'ambiente OpenAI?
NO. Gemini è più molto più lento (nel video ci sono dei tagli sui loading) e non è sempre perfettamente aderente al prompt.
Quello che su ChatGPT è normale da mesi, sul chatbot di Google non dà ancora fiducia.
Runway Gen-3 "Turbo"
La generazione video migliora le performance, non solo per la qualità, ma anche per il consumo di risorse.
Runway ha addestrato una versione di Gen-3 "Turbo" che genera video 7 volte più velocemente mantenendo la qualità.
Runway Gen-3 "Turbo"
Il modello sarà disponibile per gli utenti a un prezzo più basso.
Vediamo dietro l'angolo la generazione in real-time?
Gli effetti video di Runway
Alcuni esempi di GVFX di Runway.
La funzionalità permette di aggiungere effetti a qualunque video attraverso l'AI generativa.
Gli effetti video di Runway
Queste funzionalità, nel prossimo futuro, verranno integrate in qualunque editor video e permetteranno di testare modifiche a bassissimo effort.
Freepik integra Flux
Freepik integra i modelli Flux nella generazione delle immagini, compreso il modello dedicato alle immagini realistiche.
Ancora una volta vediamo il potere dell'integrazione in piattaforma.
Generare immagini generiche di qualità dedicate alla grafica diventa semplicissimo.
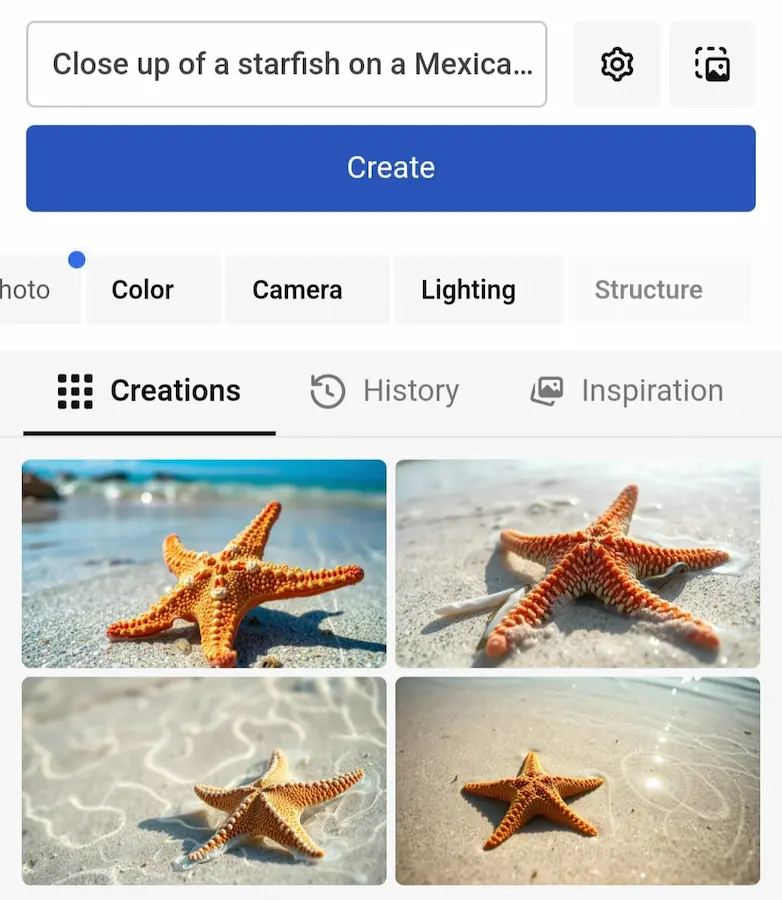
Freepik integra Flux
Se aggiungiamo l'animazione con Runway Gen-3 o simili passiamo dall'idea alla scena in pochi minuti.
Output strutturati per le API di OpenAI
Molto spesso, vengono usati i prompt per ottenere JSON strutturati come output dai LLM.
Personalmente, con istruzioni ed esempi strutturati, ho sempre ottenuto output precisi.
OpenAI, però, ha introdotto nuovi parametri nelle chiamate API per rendere i modelli estremamente fedeli allo schema fornito.
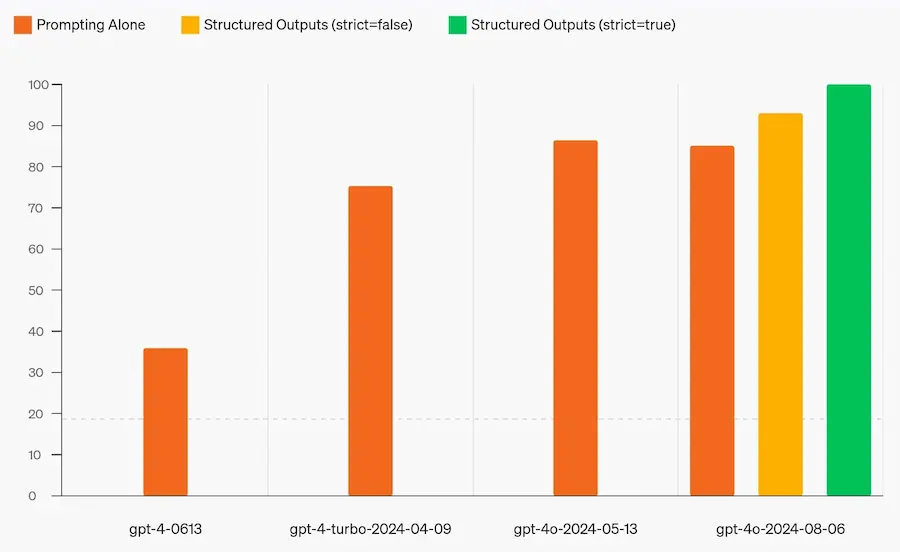

Output strutturati per le API di OpenAI
Si usa "response_format", con type "json_schema" e "strict" impostato a true.
In questo modo possiamo usare il LLM come un'API personalizzata e affidabile che restituisce dati pronti all'uso per qualsiasi utilizzo.
AgentInstruct di Microsoft
In questa fase dei LLM è più importante la quantità o la qualità dei dati di training per progredire?
AgentInstruct è un framework avanzato sviluppato da Microsoft per generare grandi quantità di dati sintetici di alta qualità e diversità, utili per l'addestramento di affinamento dei modelli.
Questo approccio, chiamato "Generative Teaching", permette di "insegnare" nuove abilità ai LLM usando dati generati automaticamente da fonti grezze come documenti di testo e file di codice.
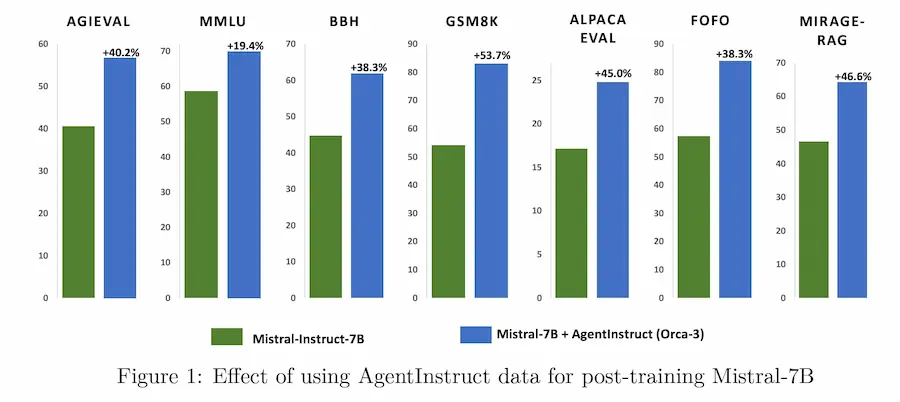
I test hanno dimostrato che i modelli addestrati con AgentInstruct, come Orca-3, superano significativamente altri modelli come GPT-3.5-turbo e Llama-8B-instruct in diversi benchmark.
Nvidia e l'ottimizzazione dei modelli
Nvidia sta lavorando a processi per ridurre le dimensioni dei modelli, facendo test su Llama 3.1 8B. Quelle che seguono sono alcune delle dinamiche sulle quali sta lavorando.
- Pruning: riduzione del modello rimuovendo strati e canali di attenzione.
- Distillazione: trasferimento della conoscenza da un modello più grande a uno più piccolo per crearne uno più efficiente che mantiene gran parte della potenza predittiva.
Risultati
- Aumento del 16% dei punteggi MMLU rispetto al training da zero.
- Costi di calcolo di 1,8 volte inferiori.

Da questo lavoro è nato Llama-3.1 Minitron 4B, che ottiene ottime performance confrontato con modelli di pari dimensioni.
Nuova funzionalità per Pinecone
Pinecone introduce una nuova funzionalità definita "reranking", per migliorare i risultati delle query vettoriali.
Può essere usata dopo il classico "retrieval", attraverso il quale vengono estratti i documenti di una knowledge più simili alla query.
A questo punto, il modello di "reranking" attribuisce un punteggio di rilevanza ai documenti estratti. Si tratta di un'azione più sofisticata (e lenta) del recupero, e può considerare più fattori, come la comprensione del contesto e delle sfumature semantiche.

Grazie a sistemi come questo, migliorano le risposte che i sistemi restituiscono all'utente.
L'automazione della ricerca scientifica
Sakana AI, in collaborazione l'Università di Oxford e della British Columbia, ha sviluppato "The AI Scientist", un sistema rivoluzionario che automatizza l'intero processo di ricerca scientifica.
Dalla generazione di idee alla scrittura di articoli scientifici completi.
Il sistema, che sfrutta LLM avanzati, è in grado di condurre esperimenti, analizzare risultati ed effettuare la revisione dei propri lavori, tutto in modo autonomo.
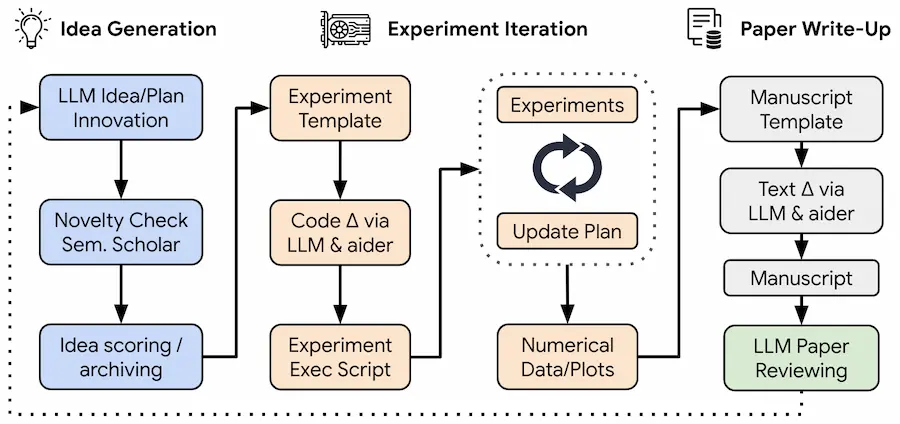
Un cambiamento significativo nel modo in cui viene condotta la ricerca scientifica, sollevando questioni etiche e sfide per il bilanciamento dell'efficienza dell'AI con l'intuizione e il giudizio umano.
Diagnosi medica attraverso i "suoni" del corpo
Health Acoustic Representations (HeAR) è un modello di AI di Google in grado di rilevare malattie attraverso i suoni prodotti dal corpo umano, come la tosse.
Health Acoustic Representations (HeAR)
In India, ad esempio, questa tecnologia viene usata per diagnosticare la tubercolosi rendendo l'assistenza sanitaria più accessibile e conveniente.
Tre anni fa, parlavo di questi sistemi con il professor Giovanni Saggio, con risultati già sbalorditivi.
 Alessio Pomaro
Alessio Pomaro
Demis Hassabis sull'AGI (Artificial General Intelligence)
Un'interessante intervista a Demis Hassabis, CEO di Google DeepMind.
Ancora una volta emerge un futuro di enormi benefici portati dall'AGI.
Ma un futuro che richiede una pianificazione meticolosa, una cooperazione globale e un'attenta gestione dei rischi, compresa una riflessione seria su come la tecnologia dovrebbe essere sviluppata e distribuita.
Demis Hassabis sull'AGI (Artificial General Intelligence)
Troppo tecno-ottimismo sul raggiungimento di stadi avanzati di AGI? Probabilmente sì, ma lo scopriremo a breve.
Necessità troppo evolute per essere gestire da questa società? Di certo sì.
AI e cambiamento climatico
Google e Nvidia hanno presentato due progetti estremamente interessanti ed evoluti per supportare la scienza nello studio del cambiamento climatico.
NeuralGCM di Google
NeuralGCM è un nuovo modello di Google che combina simulazioni basate sulla fisica e AI per migliorare la precisione delle previsioni climatiche.
A differenza dei modelli tradizionali, NeuralGCM è in grado di analizzare grandi quantità di dati e di correggere gli errori, permettendo simulazioni rapide e dettagliate anche su computer meno potenti.
Questo strumento OPEN SOURCE potrebbe essere cruciale per prevedere meglio i cambiamenti climatici e sviluppare politiche di adattamento e mitigazione più efficaci.
StormCast di Nvidia
Nvidia ha presentato StormCast, un nuovo modello di AI generativa, progettato per migliorare la previsione meteorologica.
Collaborando con il Lawrence Berkeley National Laboratory e l'Università di Washington, questo modello è in grado di fornire previsioni più accurate e a risoluzione elevata, utilizzando una frazione dell'energia rispetto ai metodi tradizionali.

StormCast è parte della piattaforma Earth2, che combina AI, simulazioni fisiche e grafica, per simulare il clima globale con una precisione senza precedenti.
Questa innovazione promette di rivoluzionare la ricerca climatica e migliorare la sicurezza delle comunità esposte a eventi meteorologici estremi.
Figure 02
Figure 02 è uno dei robot umanoidi più evoluti esistenti, che conta già delle collaborazioni importanti per le applicazioni in azienda.
Figure 02: il lancio del robot umanoide
Il funzionamento è basato su un VLM di OpenAI che elabora richieste testuali (ottenute convertendo l'audio) e immagini per valutare le azioni da compiere. Questo permette al robot di rispondere e di generare movimenti.
I dati e le correzioni si trasformano in nuovo training, e questo fa sì che le azioni migliorino costantemente.
I principi sono gli stessi che abbiamo già visto recentemente nel robot (non umanoide) di Google DeepMind basato su Gemini.
Il miglioramento del LLM, e l'uso di sistemi neuro-simbolici renderà questi robot sempre più performanti e affidabili, e chiaramente, ci saranno importanti discussioni da affrontare.
Come funzionano i Transformer?
Una bellissima interazione che spiega il funzionamento dei Transformer nel prevedere la parola successiva nel completamento.
Come funzionano i Transformer?
Scrivendo una frase nel campo e variando la "temperatura" è possibile capire ciò che il modello prevede.
Le potenzialità dell'AI
Nel 1882, l'elettricità era la nuova promessa tecnologica destinata a rivoluzionare l'industria manifatturiera.
Tuttavia, il vero cambiamento arrivò solo quando le fabbriche furono ripensate da zero, mettendo l'elettricità al centro.
Oggi, ci troviamo in una fase simile con l'intelligenza artificiale (AI), e molti sviluppatori stanno semplicemente aggiungendo AI ai prodotti esistenti senza sfruttarne appieno le potenzialità uniche.
Questa è la premessa dell'intervento di Alex Albert di Anthropic all'AI Engineer World's Fair.
Alex Albert di Anthropic all'AI Engineer World's Fair
È forse un parallelo esagerato (di certo scontato)? Forse sì, ma il concetto è assolutamente interessante.
SAM (Segment Anything Model) 2 di Meta
Meta ha introdotto SAM (Segment Anything Model) 2: un modello in grado di segmentare in real-time qualunque oggetto presente su immagini e video.
Si tratta di un sistema aperto, del quale verrà condiviso il codice, i pesi e un ampio dataset video.
SAM (Segment Anything Model) 2 di Meta
Immaginiamoci sistemi come questo applicati alla generazione/editing video, all'etichettatura dei video, alla visione artificiale e all'AR.
Model Playground di GitHub
GitHub lancia un "model playground" per testare e sviluppare applicazioni basate su LLM.
 Thomas Dohmke
Thomas Dohmke
Il sistema permette agli utenti di:
- testare tutti i modelli (Llama, GPT-4, GPT-4o, Phi, Mistral, ecc.) gratuitamente;
- portare il codice direttamente sull'editor;
- creare l'ambiente di produzione su Azure.
Torchchat di PyTorch
Torchchat è una libreria sviluppata da PyTorch che permette di eseguire in locale modelli di linguaggio di grandi dimensioni (LLM), come Llama 3 e 3.1, su diversi dispositivi, inclusi laptop, desktop e dispositivi mobili.
Chiaramente sfrutta delle tecniche di ottimizzazione, come la quantizzazione, la compilazione avanzata e l'esecuzione Eager.

Le performance
- Su MacBook Pro M1 Max: oltre 17 T/s
- Linux con GPU A100 (CUDA): oltre 135 T/s
- Smartphone (quantizzazione a 4 bit): 8 T/s
Le novità da OpenAI
3 novità di OpenAI, rilasciate abbastanza silenziosamente.
- ChatGPT (GPT-40) ha ricevuto un recente upgrade di modello, con correzioni e ottimizzazioni. Se si nota, ad esempio, le risposte su task complessi tendono a sviluppare step di "pensiero" più interessanti.
- Esiste una nuova versione sperimentale di GPT-4o con un output che può raggiungere i 64k token. Diciamo che stiamo parlando di output paragonabili a 300 pagine di un libro.
- È stato annunciato il lancio del fine-tuning per GPT-4o. Ora è possibile personalizzare il modello GPT-4o per migliorare le prestazioni e l'accuratezza nelle applicazioni specifiche.
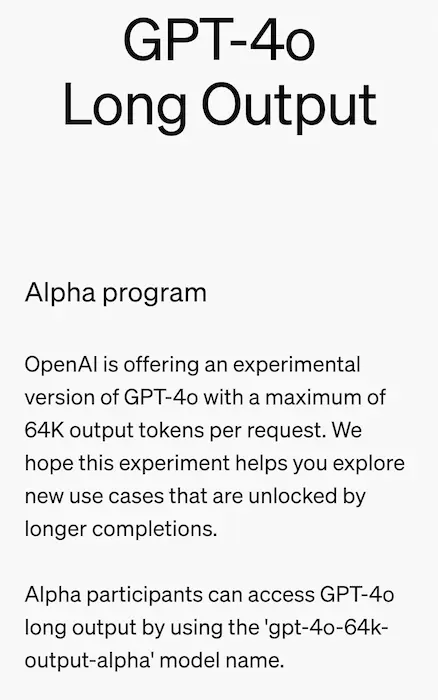
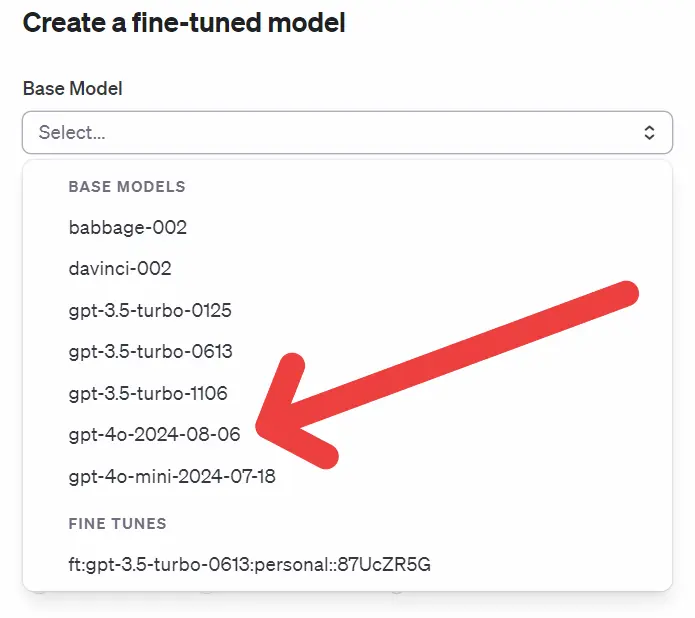

Le novità di OpenAI
La partnership tra OpenAI e Condé Nast
Il passo da "blocchiamo il crawler di OpenAI per evitare che ci rubi i contenuti" a una gara per stringere accordi ed essere tra i risultati di SearchGPT è brevissimo..
Anche Condé Nast firma una partnership, e metterà a disposizione contenuti di testate come Vogue, The New Yorker, Wired, GQ, e Vanity Fair.

SearchGPT e Perplexity
Esistono differenze tecniche sostanziali tra sistemi come Perplexity e ciò che sta costruendo OpenAI con SearchGPT.
- I primi usano un motore di ricerca per estrarre i contenuti dai risultati derivanti dalle query che il sistema produce in base alla richiesta degli utenti (il ranking viene demandato al motore). Questi contenuti diventano il contesto per un LLM, che li trasforma in una risposta.
- SearchGPT avrà un crawler, e il sistema gestirà direttamente i contenuti per stabilire le informazioni più aderenti alla richiesta.

Molti affermano: "useranno la ricerca vettoriale su tutti i contenuti scansionati ed embeddati". Non è così semplice.. comunque servirà la capacità di attribuire una sorta di indice di affidabilità. E serviranno altri parametri di affinamento.
Altro tema interessante..
come verranno trattati gli editori che stanno stringendo accordi con OpenAI?
Intelligenza Artificiale e produttività
Uno studio dell'Upwork Research Institute riporta..
La metà (47%) dei dipendenti che utilizzano l'intelligenza artificiale afferma di non avere idea di come ottenere gli incrementi di produttività che i propri datori di lavoro si aspettano, e il 77% afferma che questi strumenti hanno in realtà ridotto la loro produttività e aumentato il loro carico di lavoro.
È un chiaro segnale del fatto che non possiamo pensare che sia tutto automatico: non basta dare ChatGPT alle persone, e pensare che il processo sia finito.
Serve studio, sperimentazione e formazione, se si vogliono generare risultati.
- GRAZIE -
Se hai apprezzato il contenuto, e pensi che potrebbe essere utile ad altre persone, condividilo 🙂