Generative AI: novità e riflessioni - #7 / 2024
Un nuovo appuntamento per aggiornarsi e riflettere sulle tematiche che riguardano l'intelligenza artificiale e la Generative AI. Da SearchGPT a Llama 3.1, da Stable Video 4D a Mistral Large 2, GPT-4o mini, e molto altro.


Buon aggiornamento, e buone riflessioni..
OpenAI ha presentato un prototipo di SearchGPT
OpenAI ha annunciato SearchGPT: un prototipo di ricerca che estrae le informazioni dal web per produrre risposte per gli utenti.
I risultati sono arricchiti con immagini, video diagrammi, tabelle, e altri output, il tutto indicando le fonti.
SearchGPT di OpenAI
Si apre una parentesi importante.
Se già la web search di ChatGPT funziona meglio di AI Overviews di Google (perché il modello funziona meglio!).. se il motore di ricerca alla base di SearchGPT sarà adeguato, saranno tempi duri per Google.
Quello che segue è il crawler del nuovo servizio, visualizzabile (insieme alla lista completa dei crawler di OpenAI) cliccando qui.
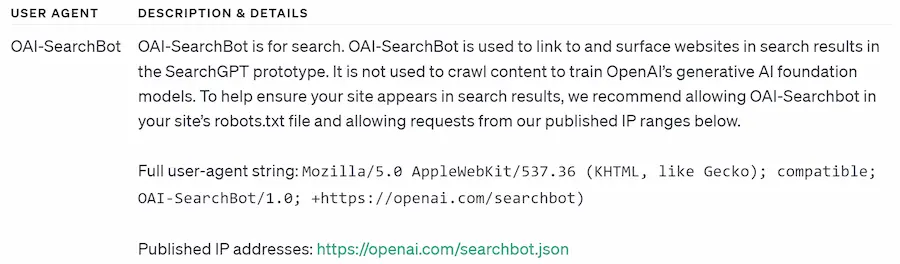
Sono davvero curioso di vedere chi bloccherà il bot di OpenAI adesso :)
Funzionerà come Perplexity?
I sistemi come Perplexity usano un motore di ricerca per estrarre i contenuti dai risultati derivanti dalle query che vengono prodotte in base alla richiesta degli utenti (il ranking viene demandato al motore). Questi contenuti diventano il contesto per un LLM, che li trasforma in una risposta.
Nel caso di SearchGPT, il sistema userà un crawler, e gestirà direttamente i contenuti per stabilire le informazioni più aderenti alla richiesta. Molti dicono: "useranno la ricerca vettoriale su tutti i contenuti scansionati ed embeddati". Non è così semplice! Comunque servirà la capacità di attribuire una sorta di indice di affidabilità. E serviranno altri parametri di affinamento.
Altro tema interessante: come verranno trattati gli editori che stanno stringendo accordi con OpenAI?
Stable Video 4D
Stability AI ha rilasciato Stable Video 4D: un modello che riceve in input un video e può generare un "oggetto" con nuove visualizzazioni, in 8 angolazioni diverse.
Stable Video 4D di Stability AI
Gli utenti possono anche specificare le angolazioni della telecamera per ottenere una maggior personalizzazione.
Potenziare l'e-commerce con l'AI Generativa
L'AI generativa può essere un mezzo interessante per potenziare l'internal linking in un e-commerce.
Ho provato a farlo in due modalità:
- attraverso la similarità degli embeddings delle pagine;
- attraverso l'analisi dei contenuti, identificando automaticamente i concetti sui quali direzionare il page rank.
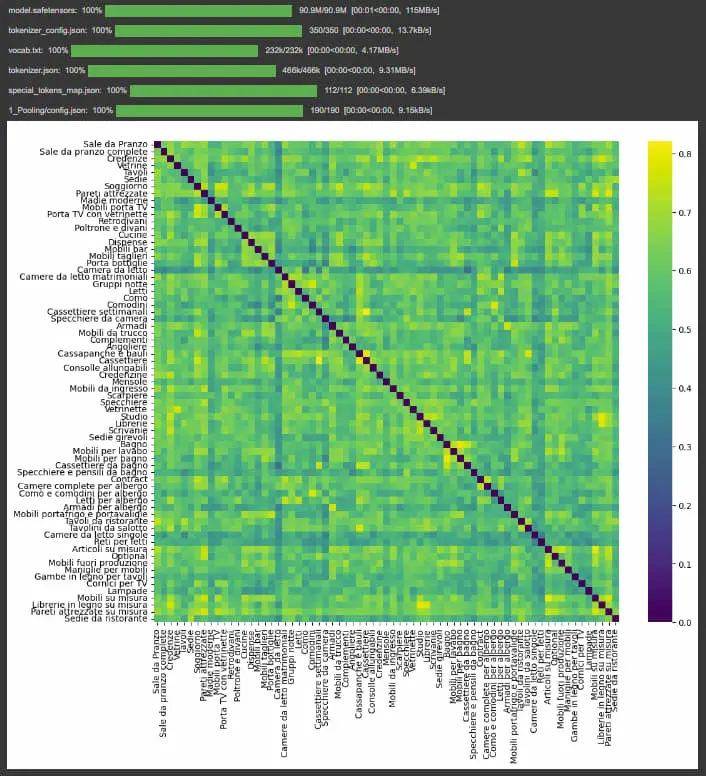
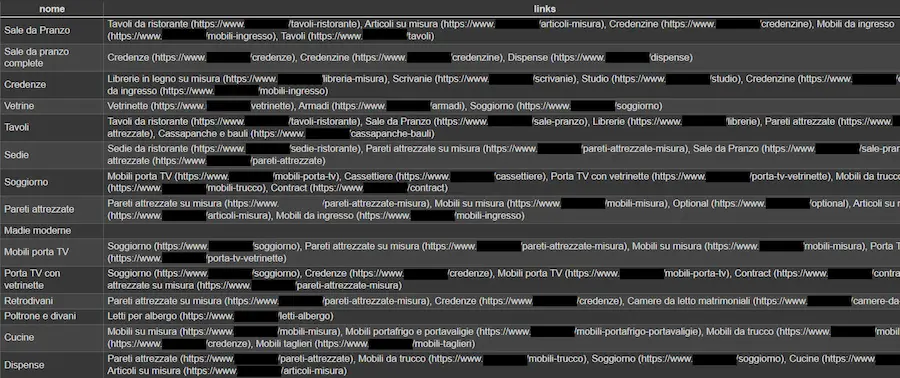
Un esempio di generazione automatica dei link interni
I risultati sono ottimi, e puoi scoprirli nel nostro seminario dell'Accademia dal titolo "AI per la SEO nell'e-commerce".


[TEST] Llama 3.1 405B
Meta ha rilasciato il suo modello più grande (405 miliardi di parametri) e performante.
Le performance sui benchmark più noti, mostrano punteggi paragonabili a modelli come GPT-4, GPT-4o e Claude 3 Sonnet.. ma Llama è open source.
L'ho provato con la mia collezione di prompt, con i quali confronto i modelli su istruzioni dettagliate, mirando a produrre output precisi.

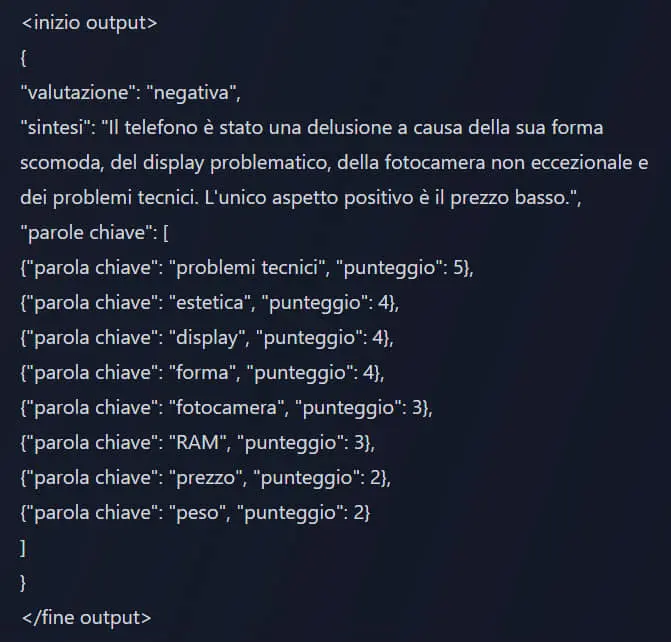
Test di Llama 3.1 405B di Meta
Risultato: il modello, come da specifiche, è molto preciso nel rispettare le istruzioni del prompt. Gli output che ho prodotto, sono assolutamente paragonabili a GPT-4.
[TEST] Mistral Large 2
Anche Mistral ha rilasciato il suo modello più grande (123 miliardi di parametri) ed efficiente.
La finestra di contesto è di 128k token, supporta decine di lingue e oltre 80 linguaggi di programmazione.
Secondo i dati di rilascio, il modello è in linea con GPT-4o, Claude 3 e Llama 3.1.
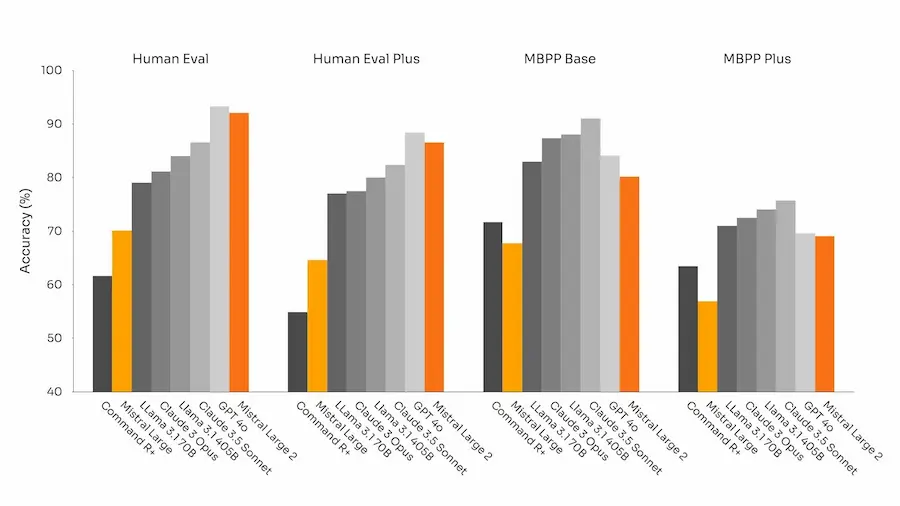

Test di Mistral Large 2
Anche i miei test mi portano a pensare che si tratti di un modello che ha ottime performance, ma non al livello di precisione di GPT-4 nell'esecuzione delle richieste.
GPT-4o mini
OpenAI ha rilasciato GPT-4o mini, un modello che supera GPT-4 su alcuni benchmark, ma che ha costi molto inferiori: 0,15$/M di token in input e 0,60$/M in output (circa 2.500 pagine di un libro).
- Usabile via API con Vision, con 128k token di finestra di input e 16k token in output.
- Con un training fino a ottobre 2023 e tokenizzatore migliorato anche per testo non in inglese.
Probabilmente è il modello che manderà in pensione GPT-3.5 Turbo.
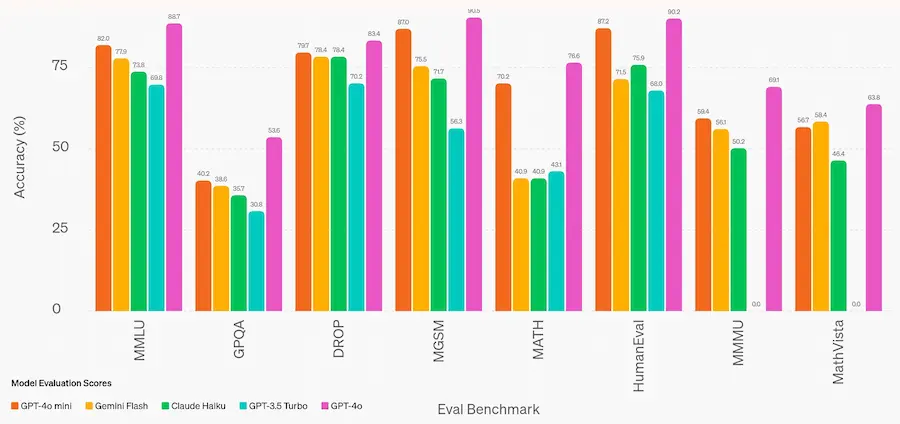
Ottimizzazione, e riduzione dei costi. Ma nulla che supera le performance dei modelli già in produzione all'orizzonte.
Test
Ho fatto diversi test mettendo a confronto GPT-4, GPT-4o e la versione "mini".
I prompt di test hanno una caratteristica in comune: sono molto dettagliati, ampi e mirano a produrre un output breve e preciso. Perché è in queste condizioni che si comprendono le capacità.
Non ho richiesto operazioni, né ragionamento: solo elaborazione del contesto.


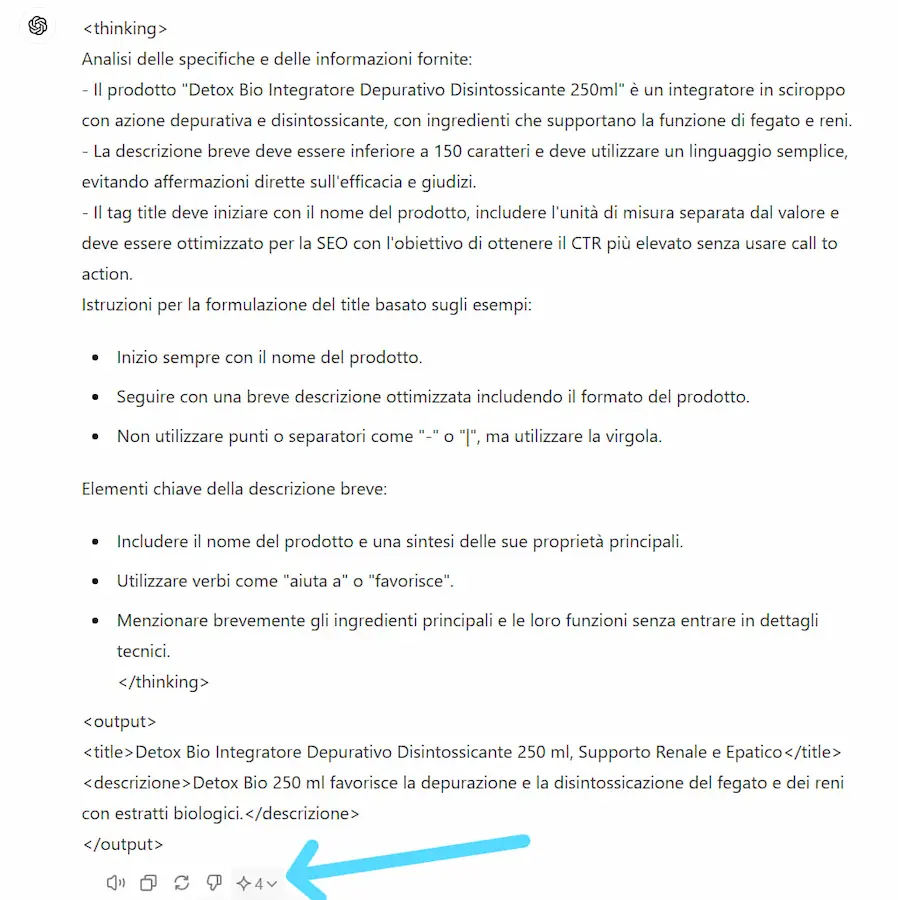
GPT-4 è il più preciso nel rispettare ogni richiesta. Gli altri due producono output simili. Quindi stiamo attenti a cosa vogliamo ottenere quando scegliamo il modello da usare.
Una rivoluzione per l'EDA (Exploratory Data Analysis)?
Un piccolo esempio di EDA (Exploratory Data Analysis) usando un prompt molto semplice su ChatGPT.
Con tutte le attenzioni del caso, non possiamo ignorare il potenziale di un approccio come questo: a zero effort e con un enorme ventaglio di osservazioni.
Una rivoluzione per l'EDA (Exploratory Data Analysis)?
Tutto questo con un modello generico. Immaginiamolo specializzato e integrato su un foglio di calcolo, o su sistemi di BI.
[STUDIO + TEST] La similarità del coseno è sempre la scelta migliore per lavorare con gli embeddings?
Un interessante studio di Netflix dimostra come la similarità del coseno può non essere sempre la scelta migliore per stabilire la vicinanza tra embeddings.
Il motivo: la similarità del coseno considera l'angolo tra due vettori e non la loro lunghezza (magnitude).
Questo può influire sulla qualità di sistemi RAG, di sistemi di raccomandazione, o di applicazioni personalizzate.
Ho fatto alcuni test con embeddings creati attraverso i modelli di OpenAI, usando diversi metodi di calcolo della similarità: il migliore risulta essere la similarità del coseno.

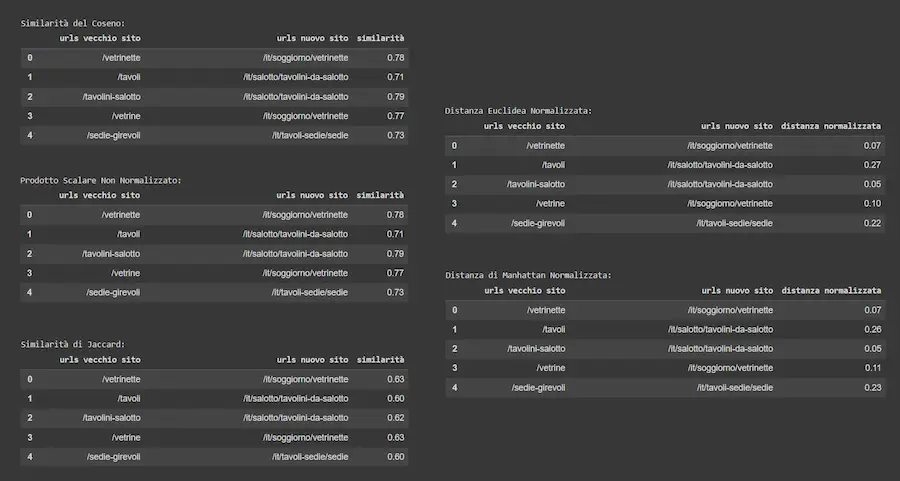
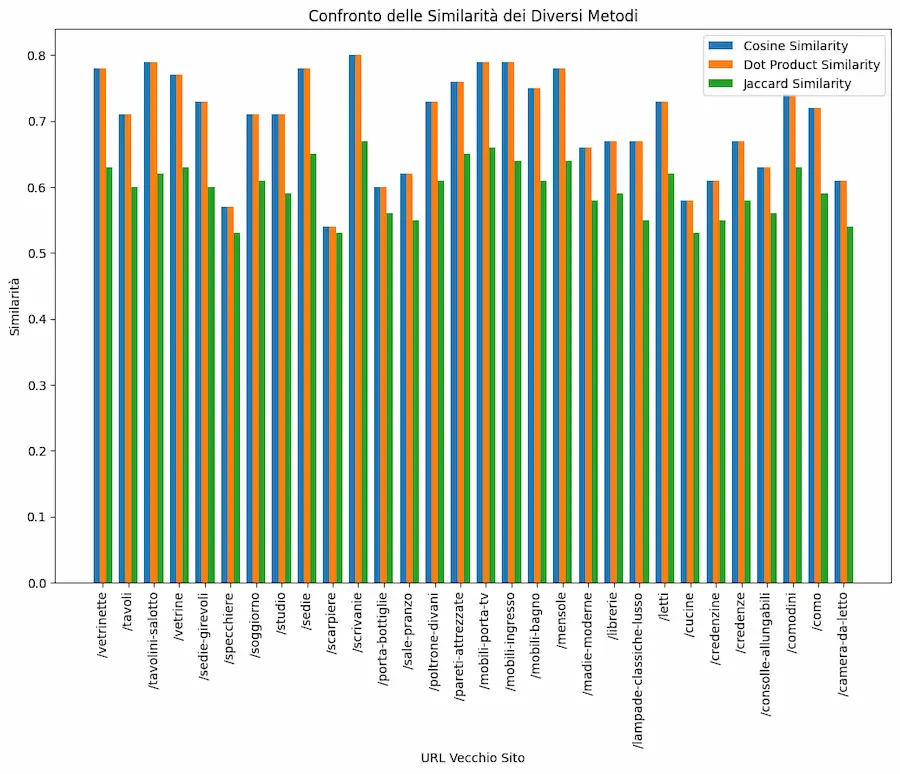
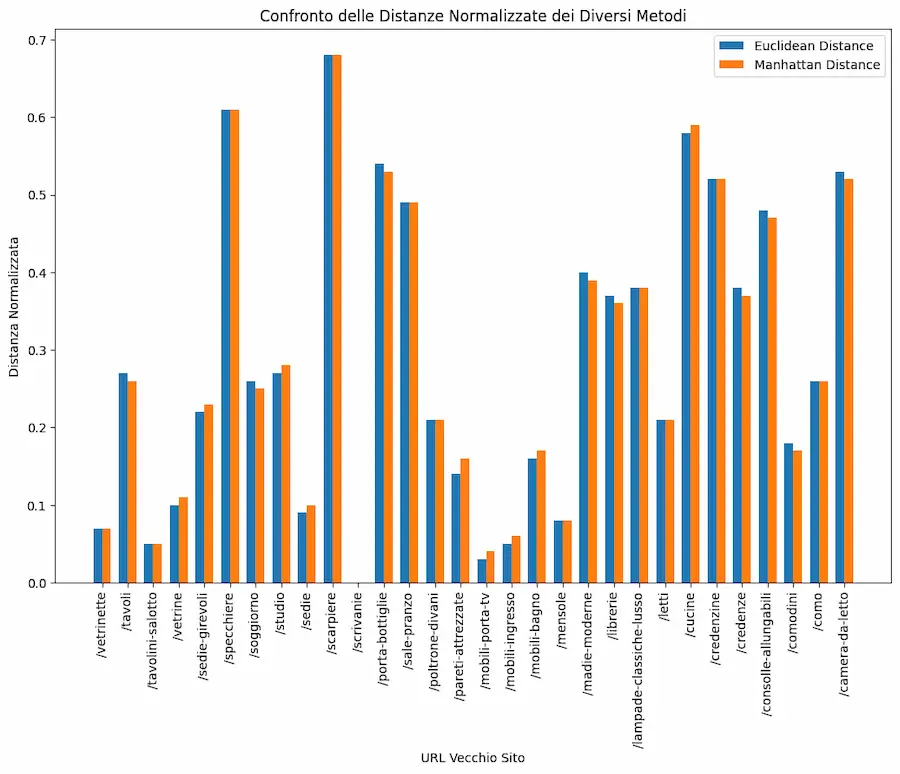
[STUDIO + TEST] La similarità degli embeddings
Attenzione, però...
Questo dipende da come vengono creati gli embeddings!
Gli embeddings di OpenAI sono normalizzati alla lunghezza "1". Ecco perché il prodotto scalare dà similarità identiche al coseno. Ed ecco perché la distanza euclidea dà la stessa "classifica" del coseno.
La documentazione di OpenAI consiglia di usare la similarità del coseno.
Il suggerimento: è sempre utile usare metodi diversi e confrontarli con ispezioni manuali, ma con la consapevolezza di come vengono creati i vettori.
La "CONSAPEVOLEZZA" è l'elemento chiave per
usare queste tecnologie in modo davvero utile.
Un'integrazione tra LangChain e BigQuery
Per costruire un RAG con i dati su BigQuery esiste un'integrazione direttamente con LangChain.
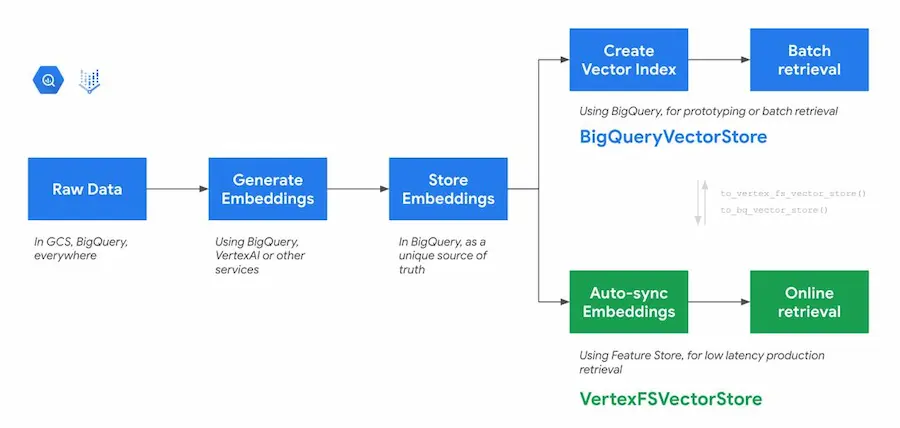
Il sistema permette di gestire la vettorializzazione, il salvataggio degli embeddings e la ricerca vettoriale usando query SQL su Big Query.
Il post del blog di Google che ne parla è interessante perché spiega il processo, ma è utile anche a chi vuole capire meglio come funzionano i sistemi RAG.
Runway Gen-3 per la generazione di uno spot commerciale
Un test di Runway Gen-3 Alpha per la generazione di uno spot commerciale (non ufficiale).
È stato realizzato in modalità Text-To-Video usando il modello, e ritoccato attraverso After Effects (il logo e la targa sono state applicate in editing).
In quanto tempo? In meno di 24 ore, comprensive di generazione, editing e sound design.
Direi che con questa versione, Runway impressiona per la qualità degli output, e ci si può spingere ad immaginare un utilizzo al supporto della produzione nel prossimo futuro.
Rufus di Amazon diventa disponibile negli USA
Rufus, l'assistente conversazione per lo shopping di Amazon diventa disponibile a tutti gli utenti negli USA.
Rufus di Amazon diventa disponibile negli USA
Ho visto e realizzato assistenti virtuali di ogni tipo, ma su un e-commerce come Amazon, dove le schede prodotto sono (MOLTO) dense di informazioni, può fare la differenza.
Immaginiamo solo l'utilità della ricerca di caratteristiche specifiche anche all'interno delle recensioni.
Gen AI: costi e benefici
La ricerca di Goldman Sachs sostiene che l'AI generativa richiede troppo investimento per ottenere risultati profittevoli a breve termine.
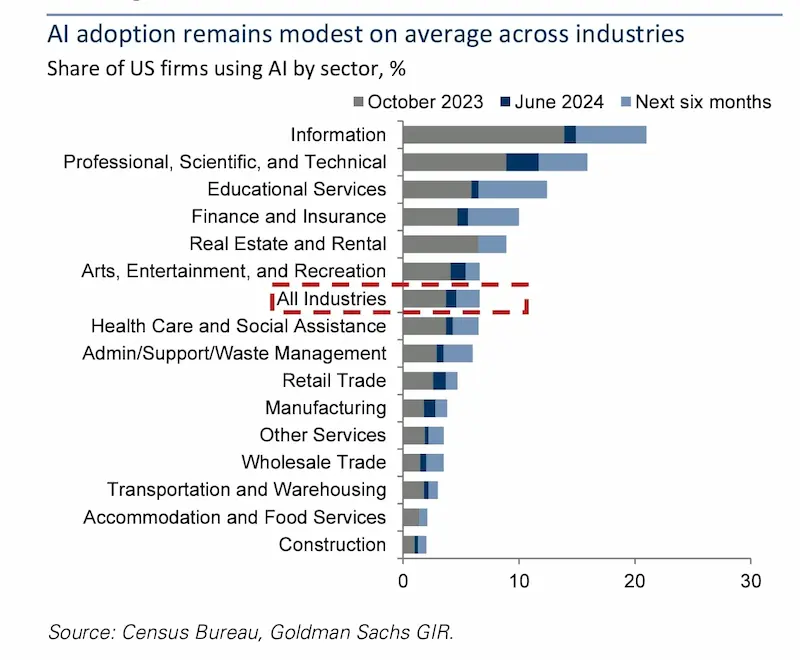
Acemoglu (MIT) e Covello (Goldman Sachs) stimano che l'AI automatizzerà meno del 5% delle attività nel prossimo decennio, contribuendo solo allo 0,9% della crescita del PIL.
Covello afferma che la tecnologia AI attuale non è sufficientemente avanzata per risolvere problemi complessi in modo economico.
Prevede che l'entusiasmo per l'AI potrebbe durare altri 18 mesi prima che gli investitori perdano interesse.
Attenzione, però...
- L'AI è ancora nella fase di costruzione dell'infrastruttura, e ci vorrà tempo prima che le applicazioni commerciali e consumer portino a una produttività e a opportunità commerciali di alto livello.
- Le stime attuali si basano sulle capacità attuali dell'AI, che miglioreranno nel tempo.
I processi aziendali dovranno evolversi per sfruttare queste nuove capacità.
Meta rilascerà i futuri modelli multimodali in UE?
Sembra che Meta non rilascerà il suo prossimo modello multimodale (e successivi, anche open) in Europa. Secondo l'interpretazione di Axios, questo deriva da una mancanza di chiarezza da parte dei regolatori locali.
Dopo Apple, quindi, anche Meta
potrebbe procedere escludendo l'UE.
Io credo che non sia, in generale (da una parte e dall'altra), un buon modo di gestire questi aspetti.

Dovremmo cooperare a livello mondiale per gestire al meglio il potenziale che abbiamo a disposizione, aprendo tavoli multidisciplinari.
Non so se è chiaro.. ma l'AI, come molti altri aspetti di cui dovremmo discutere, o si gestisce a livello globale, o sarà un'occasione sprecata.
[RISORSA] Jina Reader: un web scraper ideale per i LLM
Un web scraper da usare nelle applicazioni LLM veloce, gratuito e soprattutto iper semplice?
Jina Reader è da provare: basta un browser e qualche secondo.
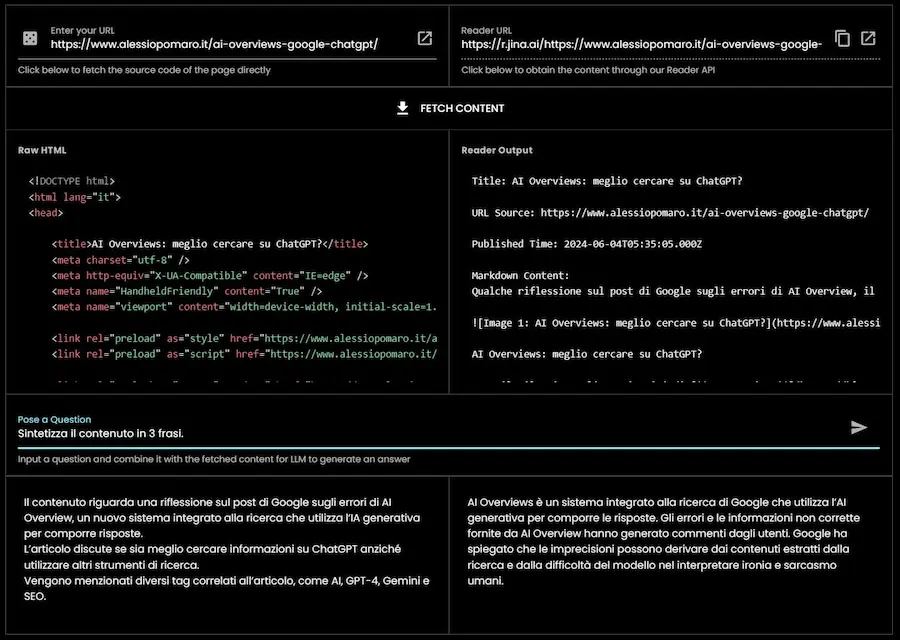
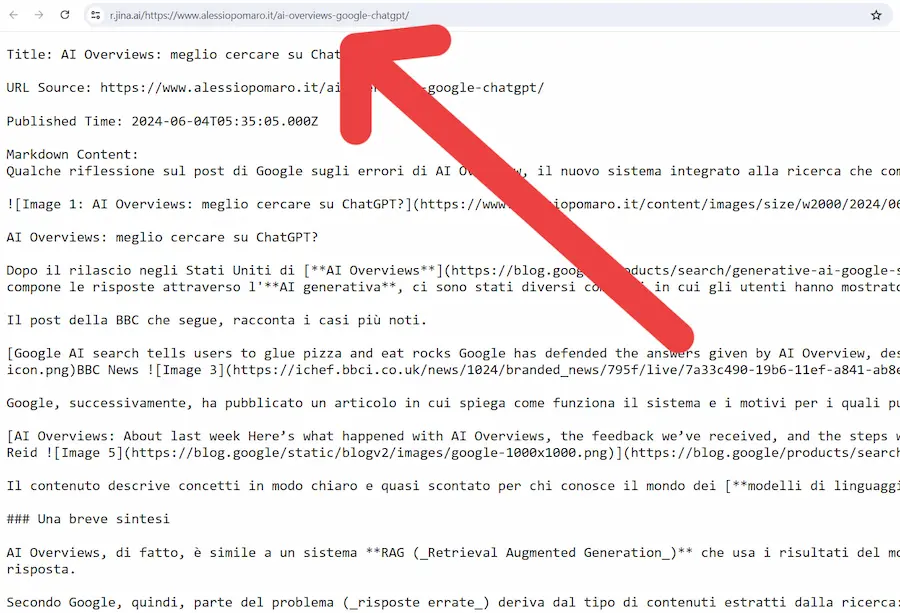
Un test di Jina Reader: un web scraper ideale per i LLM
Restituisce i dati in markdown, e preleva i informazioni anche dalle immagini e dai PDF.
Il funzionamento di base prevede l'inserimento dell'URL da analizzare, ma permette anche di specificare direttamente una query: il sistema esegue la ricerca e restituisce i dati dei risultati.
SpreadsheetLLM di Microsoft
SpreadsheetLLM di Microsoft mira a risolvere un limite nel lavoro con i LLM: i task sui fogli di calcolo.
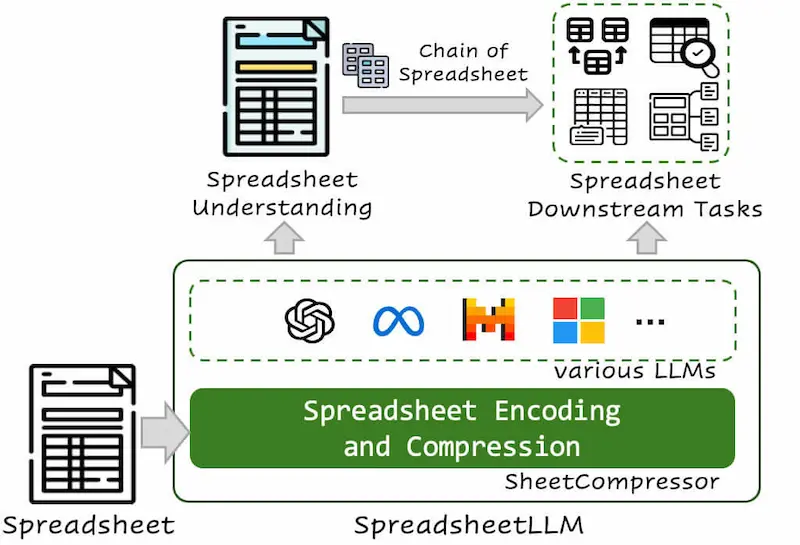
Ma non avevamo già Code Interpreter, ad esempio? NO. In quel caso viene usato un LLM per sviluppare ed eseguire uno script Python che legge i dati da un foglio e li può elaborare.
In questo caso, il modello permette di usare un LLM per interagire direttamente con i dati nel foglio.
Anthropic: la valutazione dei prompt
Anthropic ha introdotto una serie di funzionalità molto interessanti in ambito di prompt engineering.
- Genera automaticamente prompt molto dettagliati, partendo da una semplice descrizione di un task.
- Permette di produrre dati sintetici per testare i prompt (questo è fantastico!).
- Viene aggiunta una suite di valutazione, con la possibilità di confrontare diverse versioni del prompt.
Anthropic: la valutazione dei prompt
Tutto questo fa di risparmiare tanto tempo in quello che spesso definisco "ciclo di generazione, feedback e ottimizzazione dei prompt", anche se preferisco creare manualmente il prompt iniziale, per avere il controllo totale.
Voice Isolator di ElevenLabs
Un esempio del nuovo voice isolator di ElevenLabs.
Viene sfruttato un modello di AI per isolare la voce nel file di input.
Voice Isolator di ElevenLabs
Non si tratta di grandi novità: esistono già moltissimi sistemi che offrono questa funzionalità. Tuttavia diventano sempre più semplici e "di serie" ovunque.
La previsione multi-token di Meta
Meta ha reso disponibili dei modelli che utilizzano la previsione multi-token, un nuovo approccio per addestrare i LLM.
Con questa tecnica si istruisce il modello a prevedere più token futuri contemporaneamente, migliorando l'efficienza.
I benefici aumentano con la dimensione del modello. Un modello da 13 miliardi di parametri, ad esempio, mostra una capacità maggiore del 15% di gestire problematiche di sviluppo.
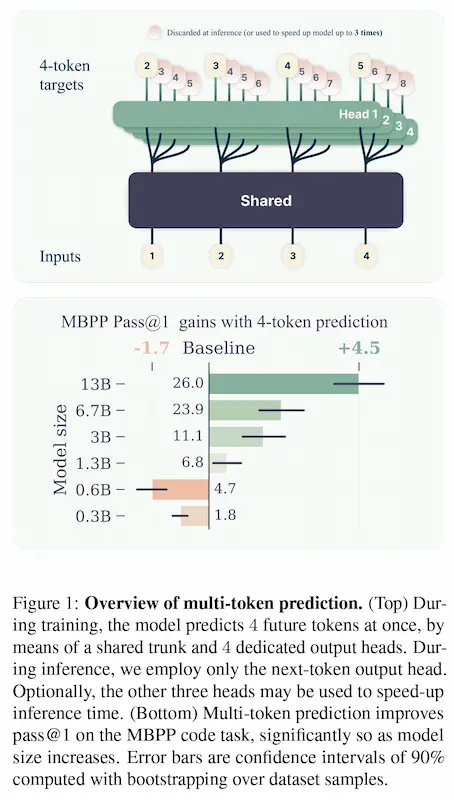
In pratica è una tecnica che migliora l'efficienza e le performance dei modelli, rendendoli anche più veloci.
L'interazione uomo-robot con Gemini 1.5 Pro
Nel video vediamo l'evoluzione dell'interazione uomo-robot basata su Gemini 1.5 Pro, in grado di processare un contesto di 1M di token.
- Il robot può orientarsi in uno spazio, basandosi su istruzioni umane, video tour e ragionamento.
- Il sistema raccoglie gli input e crea una rappresentazione semplificata dello spazio.
- Successivamente, il robot può compiere azioni eseguendo input multimodali (istruzioni audio, schizzi di mappe su una lavagna, segnali visivi, ecc.).
L'interazione uomo-robot guidata da Gemini 1.5 Pro
In futuro, un robot potrebbe essere in grado di orientarsi in un ambiente attraverso semplici video registrati con lo smartphone.
I 5 livelli nel percorso verso l'intelligenza artificiale generale (AGI)
Bene. Finalmente si sta ridimensionando la questione AGI.
OpenAI annuncia gli step del percorso, il loro significato e lo stato attuale.
Io credo che i LLM non possano condurre all'AGI da soli. Servirà un avanzamento architetturale.
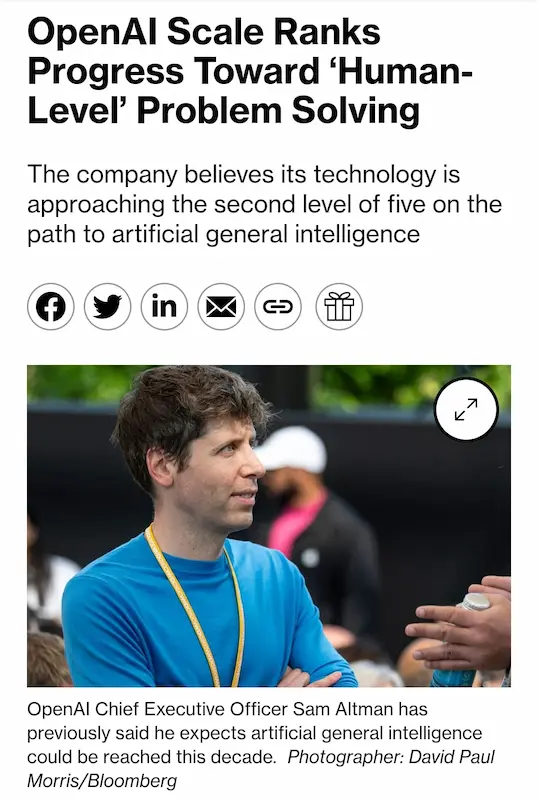
- Infatti, i modelli oggi migliorano lentamente dopo il boost di GPT-4.
- E Mira Murati (CTO di OpenAI), recentemente ha affermato che attualmente non esistono modelli molto più evoluti di quelli già a disposizione.
Slow motion e bullet time realizzati con Luma
Un esempio di "slow motion" e "bullet time" realizzati attraverso Luma.
Slow motion e bullet time realizzati con Luma
Il modello viene usato su alcuni frame del video per generare l'effetto.
L'idea è geniale.
Il 3D come driver per un'animazione AI
Un esempio di utilizzo di un modello 3D come "driver" per un'animazione AI.
L'autore ha usato: il modello 3D per creare keyframe + upscale con Magnific + animazione con Luma.
Questo permette di mantenere una coerenza elevata.
Here's a look behind the scenes of how I used a 3d model, generated from an image, as a "driver" for ai animation. In the near future we'll see more 3d tools that support these types of workflows, with much more emphasis on enhancing user input instead of just letting the ai do… pic.twitter.com/Gezwm3QqIg
— Martin Nebelong (@MartinNebelong) July 19, 2024
In futuro, probabilmente, gli strumenti per il 3D che supporteranno nativamente questo tipo di flusso.
Un fork di Jupyter Notebooks con AI generativa
L'integrazione dell'AI generativa su piattaforme di sviluppo, è ormai considerata "normale".
Dopo aver visto Gemini su Colab, ecco un fork di Jupyter Notebooks che integra la generazione di codice attraverso Codestral (Mistral) e GPT-4o.
Nella demo è impressionante la rapidità di generazione, il sistema di spiegazione del codice, ma soprattutto la correzione dei bug.
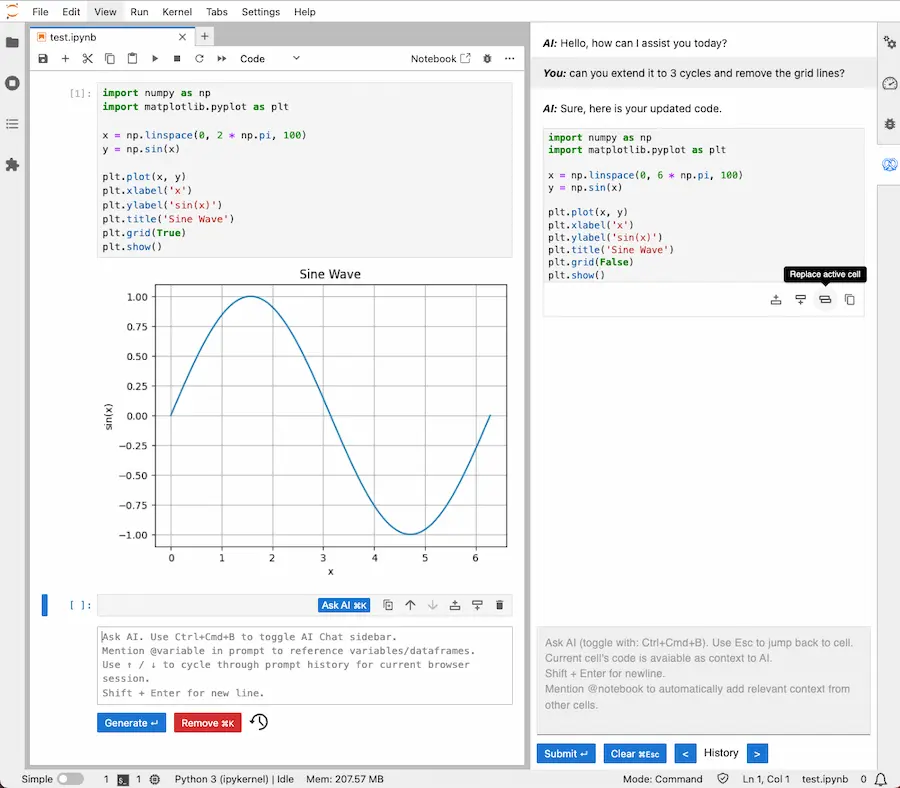
Sarà possibile pensare di sviluppare senza supporti di questo tipo in futuro? Forse NO, ma il tema è sempre lo stesso: chi possiede le hard skill saprà cosa chiedere e come sfruttare al meglio questi sistemi.
Tim Fu: SORA Showcase
Il video è stato generato con SORA di OpenAI. Ha difetti? Sì, ne ha.
Ma quello che afferma il creator (un architetto) fa capire dov'è la vera innovazione in questo momento che precede video perfetti.
Tim Fu: Sora Showcase
"Oltre le immagini e i video, la visualizzazione generativa serve come processo di progettazione. La qualità spaziale e la materialità possono essere esplorate a velocità senza precedenti, permettendo ad architetti e designer di concentrarsi sui valori fondamentali del design invece che sulla produzione di elementi visivi."
- Tim Fu
L'architettura MoA (Mixture of Agents)
Un esempio di implementazione di architettura MoA (Mixture of Agents) con 50 righe di codice.
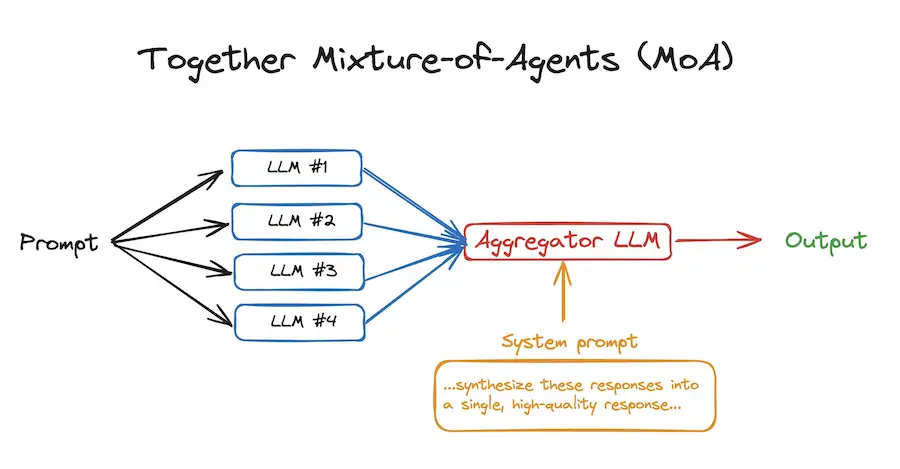
Il sistema usa 4 LLM open source che elaborano il prompt e un LLM "aggregatore" che combina gli output con l'obiettivo di produrre la miglior risposta.
I tempi di inferenza aumentano, ma le performance migliorano notevolmente.
Together.ai mette a disposizione tutto questo via API, con notevoli vantaggi.
Runway Gen-3 per la progettazione
Un esempio di utilizzo di Runway Gen-3 per una progettazione che successivamente continua in altri ambiti, ad esempio Cinema 4D.
L'autore ha usato il modello per dare vita a un'idea (che avrebbe richiesto settimane di lavoro), e successivamente ha tracciato il movimento 3D per poi inserirlo in Cinema 4D.
Runway Gen-3 per la progettazione
Racconta come l'output non sia perfetto, e che tutto va rifinito.. ma che comunque il potenziale è "folle".
L'AI non genera skill, ma estende e
potenzia competenze consolidate.
The Uneven Impact of Generative AI on Entrepreneurial Performance
In questo studio, pubblicato da Harvard Business School, si vede come, mettendo a disposizione un AI business mentor (basato su GPT-4) a un gruppo di imprenditori, non sono riusciti ad ottenere subito impatti tangibili.

Se non si conosce come funzionano questi sistemi, e non si hanno strategie e obiettivi chiari (derivanti ha hard skill consolidate), non si otterranno risultati.
Un documentario multilingua usando ChatGPT e SORA
Creare un documentario multilingua usando ChatGPT, SORA e il Voice Engine di OpenAI?
Durante l'AI Engineer World's Fair, Romain Huet ha mostrato una demo davvero notevole.
Un documentario multilingua usando ChatGPT e SORA
Nella realtà, questo avverrà? No, ma la vera potenzialità di questi sistemi, è l'integrazione nei flussi di lavoro come supporto e potenziamento.
Moshi: un modello multimodale open source
Moshi è un modello multimodale open source, che sembra avere performance simili a GPT-4o.
È un progetto di Kyutai Labs, che ha ricevuto 300M di investimenti per lo sviluppo.
Moshi: un modello multimodale open source
Dimostrazioni come queste fanno fatica a stupire oggi, ma fanno capire il livello di interazione che si sta raggiungendo.
LangChain lancia LangGraph Cloud
Un sistema che permette di creare applicazioni LLM multi agente attraverso un'interfaccia grafica, in una piattaforma cloud.
LangGraph Cloud
GraphRAG: da documenti a knowledge graph
GraphRAG diventa disponibile su GitHub, anche con un'area dedicata agli esempi.
Si tratta di una libreria di Microsoft in grado di trasformare dati e documenti in un knowledge graph dettagliato.
Tale struttura, viene usata successivamente per determinare risposte migliori e più affidabili.
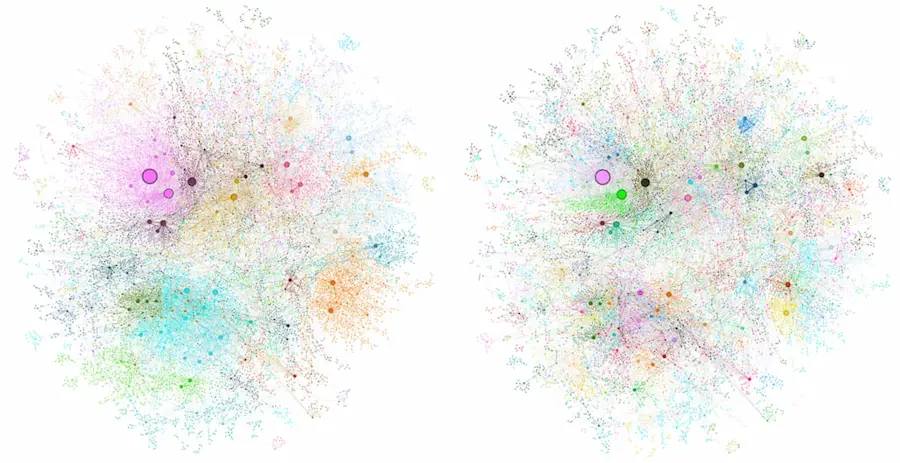
Le performance dimostrano che la combinazione tra LLM e knowledge graph può essere una soluzione vincente per i sistemi RAG.
Meta 3D Gen: da prompt testuale a 3D
L'evoluzione dei modelli 3D continua. Meta 3D Gen è un sistema i grado di generare 3D da prompt testuale in meno di 1 minuto.
I 3D sembrano di alta qualità, con texture ad alta risoluzione.
Meta 3D Gen: da prompt testuale a 3D
Questi progressi contribuiranno a ridurre effort in modo significativo in diversi ambiti del digital, come il mondo e-commerce.
È possibile che un modello superi il livello dei dati di training?
Questo studio dimostra come un modello generativo, addestrato su trascrizioni di partite di scacchi di giocatori di un determinato livello, sia in grado di avere un livello superiore.
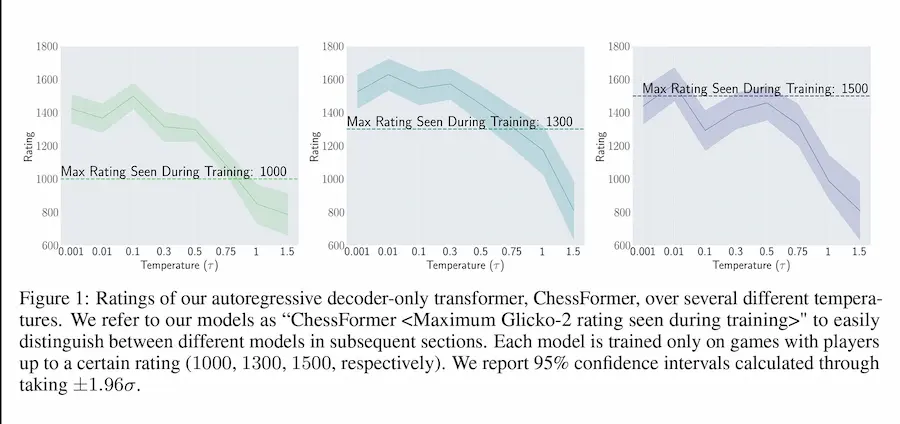
La capacità deriva da una tecnica definita "campionamento a bassa temperatura": l'assegnazione di probabilità più alte alle mosse migliori, riducendo la probabilità di errori umani presenti nei dati di addestramento.
- GRAZIE -
Se hai apprezzato il contenuto, e pensi che potrebbe essere utile ad altre persone, condividilo 🙂