Generative AI: novità e riflessioni - #6 / 2024
Un nuovo appuntamento per aggiornarsi e riflettere sulle tematiche che riguardano l'intelligenza artificiale e la Generative AI.


Una rubrica che racconta le novità più rilevanti che riguardano l'Intelligenza Artificiale, con qualche riflessione.
Buon aggiornamento,
e buone riflessioni..
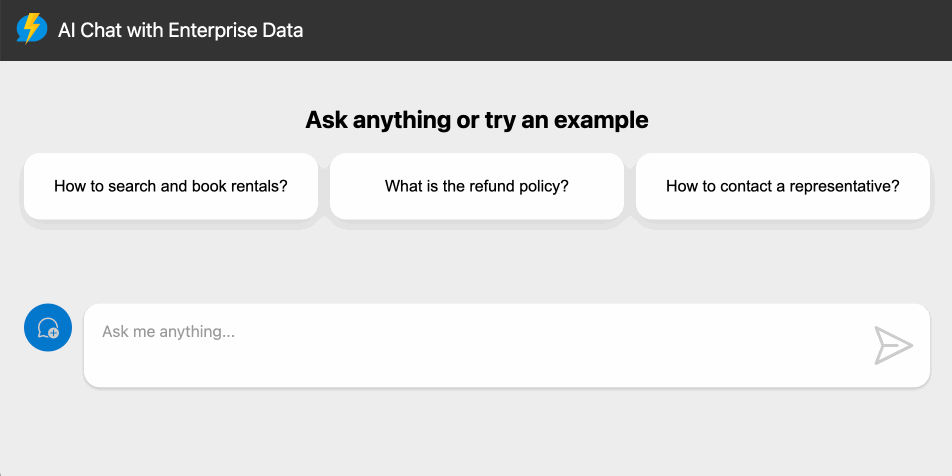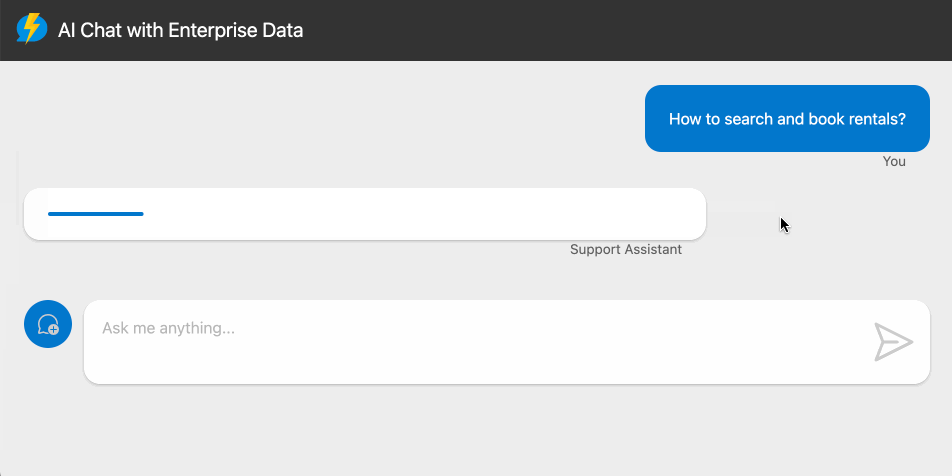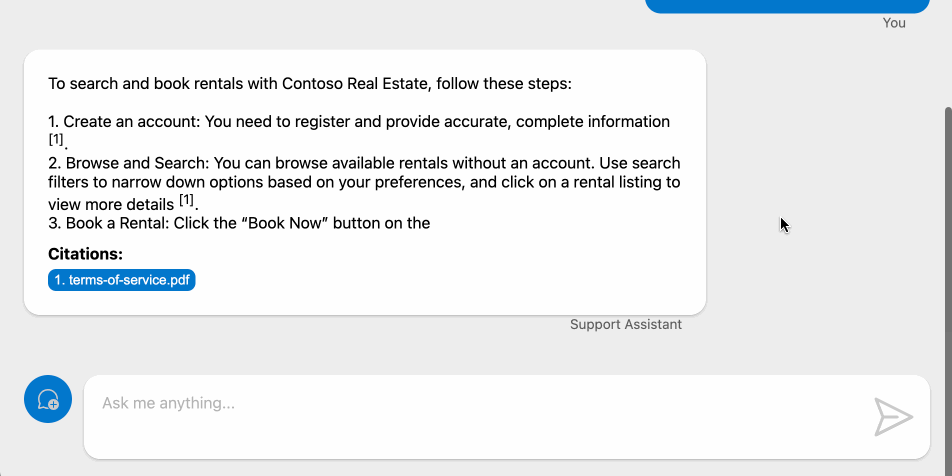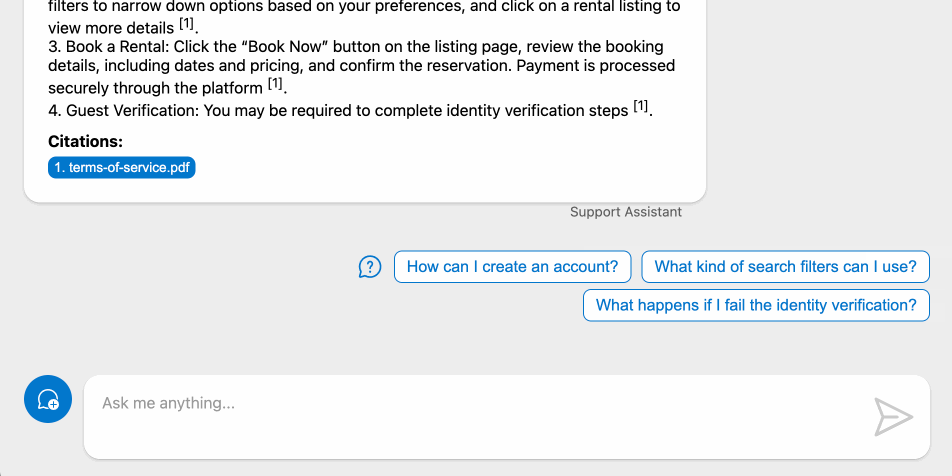
AI per la SEO nell'e-commerce [anticipazione]

Un nuovo percorso della nostra Accademia dedicato all'utilizzo dell'AI nei flussi operativi dedicati alla SEO nei progetti di e-commerce.
Alcune anticipazioni di quello che vedremo
- Prompt Design / Prompt Engineering: le basi
- Generazione, ottimizzazione ed estensione delle schede prodotto
- L'automazione nella creazione delle schede prodotto usando anche uno scraper basato su LLM
- Creazione dei testi di categoria "data driven"
- Ottimizzazione delle pagine delle entità più importanti dell'e-commerce (anche su Big Query)
- Ottimizzazione dell'internal linking
- Redirection automatizzata in fase di migrazione basata sull'analisi semantica
- Come sfruttare (veramente) le nuove funzionalità di Screaming Frog dedicate all'AI Generativa
- Analisi delle recensioni (embeddings + clustering + LLM)
- La creazione di una sezione video per il portale
- Non solo AI Generativa: esempi di utilizzo di uso di Big Query LM
- Come possiamo creare script per l'automazione basata sull'AI?
E molto altro..
Videoregistrazioni, Collezione dei Prompt, Colab e materiale aggiuntivo, verranno condivisi con i partecipanti.
AI Overviews: meglio cercare su ChatGPT?
Ho scritto alcune riflessioni sugli errori generati da AI Overviews (ex SGE), e sul post che ha pubblicato Google per dare delle spiegazioni in merito.
Non solo riflessioni, ma anche test che portano alla provocazione..
..meglio cercare su ChatGPT?
 Alessio Pomaro
Alessio Pomaro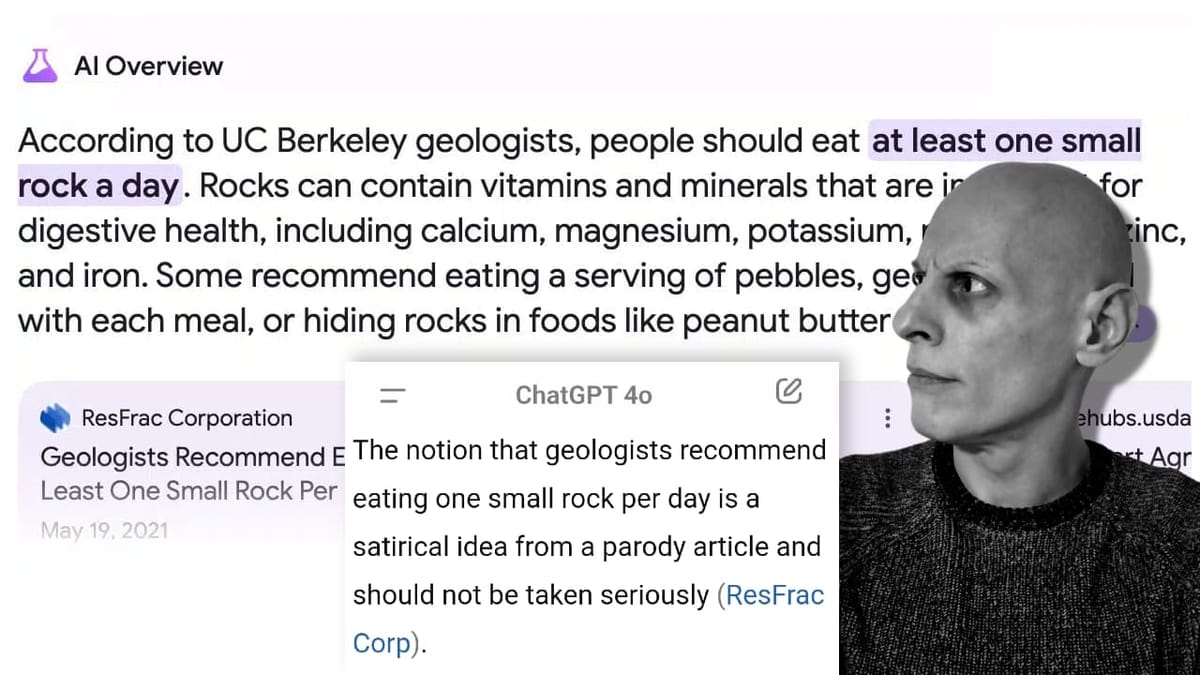
Intelligenza Artificiale: un mezzo per piloti esperti
L'AI è un mezzo per piloti esperti. Lo racconto in questo breve viaggio nell'intersezione tra la Generative AI, le attività in azienda e le competenze delle persone.
Alessio Pomaro
L'evoluzione delle leve diventa valore aggiunto solo se sappiamo dove spostare i massi. E questa è una conoscenza da piloti esperti
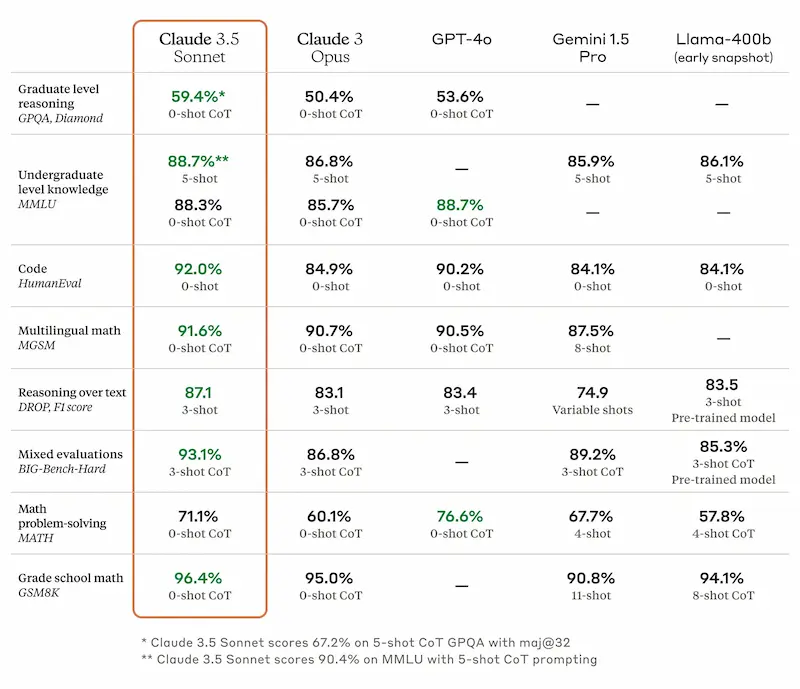
Claude 3.5 Sonnet
Claude 3.5 Sonnet è la prima versione della nuova famiglia di modelli di Anthropic.
Migliorano le performance e la velocità (x2 rispetto a Claude 3 Opus), e diminuisce il costo.
Su Claude.ai è a disposizione anche "Artifacts" una nuova funzionalità beta che apre una finestra laterale alla chat dedicata al codice e all'interattività.
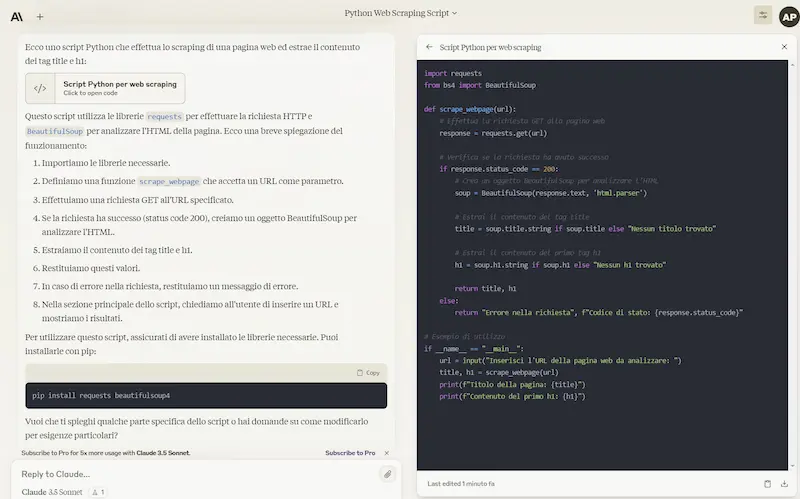
Claude 3.5 Sonnet
L'ho provato su diversi prompt: prime impressioni molto positive!
Una piccola demo di Artifacts
Non siamo al livello di Code Interpreter di ChatGPT, ma la nuova funzionalità di Claude 3.5 Sonnet merita attenzioni.
In questo caso, carico un piccolo dataset e chiedo di sviluppare dei diagrammi che lo esplorano.
Una demo di Artifacts - Claude 3.5 Sonnet
Il sistema sviluppa un blocco di codice e mostra una dashboard interattiva che presenta i dati.
Runway Gen-3 Alpha
Runway annuncia Gen-3 Alpha, il primo di una serie di modelli basati su una nuova infrastruttura per il training multimodale.
Il sistema diventerà la base di tutti i tool di Runway, mantenendo funzionalità come Motion Brush, controlli della fotocamera e la modalità Director.
Il video mostra alcuni esempi di generazione del modello, che implementerà i dati C2PA e altri sistemi di sicurezza.
Demo di Runway Gen-3
Come sempre, le demo sono bellissime e ormai ci fidiamo poco.
Ma, quello che segue, è un video realizzato da Riccardo Silano con Gen-3.
Uno "stress test" per Runway Gen-3
L'obiettivo era uno "stress test", esplorando una "foresta di fiori".
L'audio è stato realizzato attraverso Udio.
L'aspetto che emerge è che possiamo davvero pensare di concretizzare idee in modo "semplice".
Ridurre complessità e consumo dei LLM
Un nuovo studio dimostra che è possibile ridurre in modo significativo la complessità e il consumo di risorse dei LLM, senza degradare le performance.
Per farlo è stata eliminata la moltiplicazione di matrici (MatMul), ovvero la principale causa del costo computazionale.
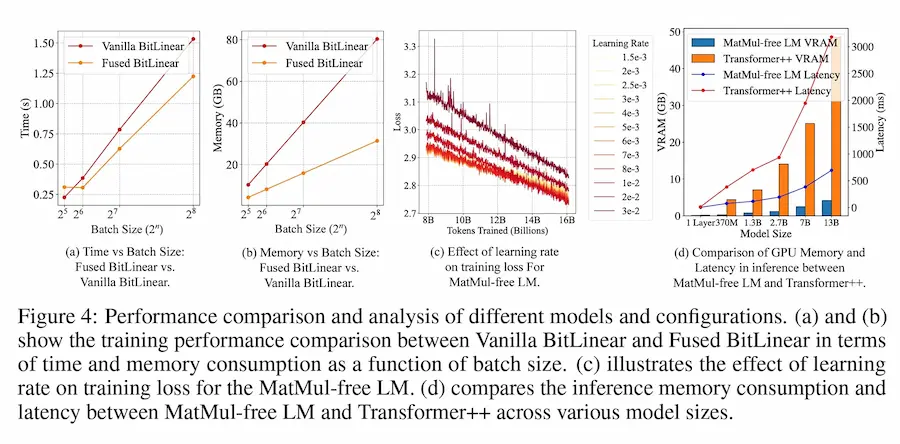
Risultati: fino al 61% di memoria in meno durante il training, e una riduzione di 10 volte in fase di inferenza.
L'uso di un hardware personalizzato, ha permesso di processare modelli su scala di miliardi di parametri con un consumo energetico di 13W, avvicinando questi sistemi all'efficienza (in termini ci consumo) del cervello umano.
Dire che è un risultato sbalorditivo, credo sia riduttivo.
Generative AI for Beginners
Microsoft continua ad aggiornare il corso "Generative AI for Beginners" con la versione 2.
18 lezioni interessanti per una visione completa sul mondo della Generative AI.
Da un'introduzione sui LLM, passando per le fondamenta del Prompt Engineering, per la creazione di applicazioni, RAG e database vettoriali, fino ai sistemi multi-agente e fine-tuning.
Un'intervista a Demis Hassabis (CEO di Google DeepMind)
Tra i diversi concetti, ne metto in evidenza uno. Si parla, infatti, di "approccio ibrido": Hassabis espone l'importanza di combinare modelli generali di AI (come i LLM) con sistemi specializzati per applicazioni specifiche.
Un esempio: il modello generale potrebbe gestire la comprensione del linguaggio naturale, mentre quello specializzato la risoluzione di problemi matematici o la pianificazione strategica.
Un'intervista a Demis Hassabis (CEO di Google DeepMind)
Si torna, quindi, a parlare di sistemi neuro-simbolici. E questo è molto interessante.
Geoffrey Hinton in un'intervista per Bloomberg
I think there's approximately a fifty percent chance that it will become more intelligent than us in the next 20 years
Concordo sulla questione della sicurezza, sulla critica a OpenAI, e sull'importanza della cooperazione globale.
Geoffrey Hinton in un'intervista per Bloomberg
Non sono d'accordo sul fatto che più si aumenterà la scala dei modelli e più miglioreranno. Non lo sappiamo.. e GPT-4 è il riferimento da un bel po' di tempo.
HAI at Five Conference di Stanford
È online l'ultima HAI at Five Conference di Stanford.
I concetti più interessanti?
- Efficienza energetica e dati. Si confronta l'efficienza dei sistemi di AI rispetto al cervello umano, che consuma molta meno energia grazie alla gestione migliore delle connessioni simultanee. Si discute l'importanza di migliorare l'efficienza dei dati, per ridurre la scala dei dataset per l'addestramento dei modelli.
- Neuroscienze e AI. Si discute come i modelli da AI possono aiutare a comprendere meglio il cervello umano e viceversa. La registrazione dell'attività neuronale è fondamentale per sviluppare modelli più accurati dell'intelligenza.
- Il progetto "Thousand Brains", un'iniziativa open source finanziata dalla Gates Foundation per sviluppare sistemi di apprendimento sensomotorio basati su principi biologici. Questo progetto mira a creare macchine veramente intelligenti che possano apprendere e adattarsi in modo simile agli esseri umani.
HAI at Five Conference di Stanford
È sempre più importante un approccio interdisciplinare per affrontare le complesse sfide etiche, sociali, e tecniche che ci aspettano nel prossimo futuro.
V2A di Google DeepMind
Google DeepMind presenta V2A, un modello in grado di generare l'audio per i video.
Il sistema si basa su un processo di diffusione, guidato da input visuali (dal video) e da prompt in linguaggio naturale (facoltativo).
In output si riesce a ottenere audio sincronizzato e realistico.
Le tracce audio sono dorate di SynthID, la filigrana digitale targata Google.
I video negli esempi sono stati creati usando Veo + V2A. Impressionante!
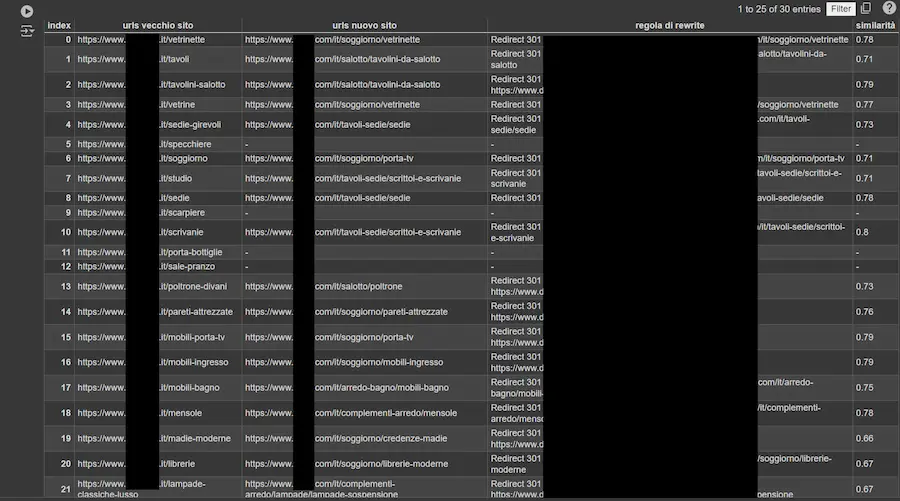
Perché gli esperimenti SEO con gli embeddings non funzionano?
In diversi mi hanno scritto per sperimentazioni deludenti con gli embeddings, usando la nuova funzionalità di Screaming Frog e le API di OpenAI.
Il motivo? Non si tratta di "magia": dobbiamo scegliere bene i dati da vettorializzare.

Lo snippet di default di Screaming Frog, infatti, lavora sul corpo completo della pagina, ma non sempre è utile (anzi!).
Durante il prossimo seminario dell'Accademia, dedicato all'AI nella SEO per l'e-commerce (9 luglio), vedremo degli esempi di utilizzo su un sistema per facilitare la redirection in fase di migrazione.
Il primo spot pubblicitario generato con SORA
Toys "R" Us ha pubblicato il primo spot pubblicitario generato con SORA di OpenAI. L'abbiamo visto tutti, vero?
È incredibile, ma non amo il fatto che questa sia una leva per fare notizia.
Perché c'è la necessità di dire che è stato realizzato con l'AI?
Tra l'altro, prendendo un rischio di effetto boomerang.. vedi i commenti online, con utenti che stanno setacciando ogni singolo fotogramma, trovando "difetti" che nemmeno con la spiegazione si riescono a comprendere.
Toys "R" Us: il primo spot pubblicitario generato con SORA
Nota divertente: in un seminario, l'anno scorso, ho fatto un esperimento mostrando un servizio fotografico dei piatti di un noto 3 stelle Michelin, dicendo che le immagini erano state generate da un modello. Ci fu chi trovò "difetti tipici dei sistemi di AI", e chi si spinse addirittura a capire il modello usato.
CharXiv: un nuovo approccio alle performance dei modelli multimodali
Iniziamo a vedere dei benchmark più interessanti per misurare le performance dei modelli multimodali.
CharXiv propone test su una grande quantità di diagrammi provenienti da studi scientifici, con domande relative alla comprensione.
Nel paper possiamo vedere anche una classifica dei modelli, a confronto anche con gli esseri umani.
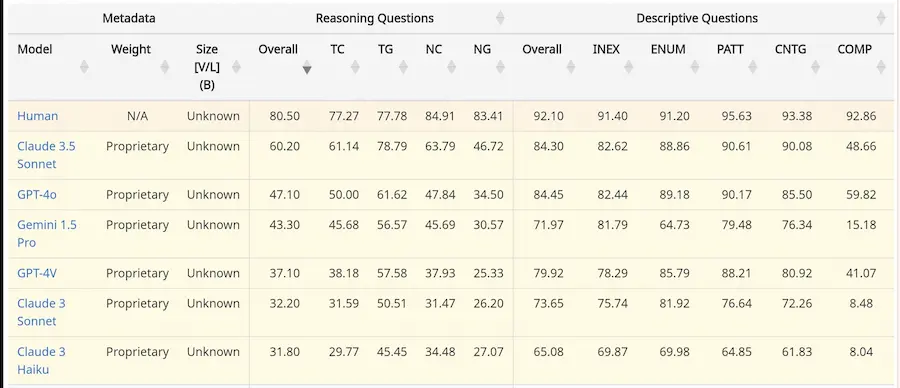
Di certo, i benchmark che stiamo usando attualmente tendono a darci un quadro ottimistico sulle performance.
Diagnosi medica predittiva con l'analisi della voce
Un nuovo studio mostra come, grazie all'AI, sarà possibile fare diagnosi medica predittiva attraverso l'analisi della voce. Con una precisione altissima.


Ho parlato di questo concetto nel mio libro 3 anni fa, insieme al prof. Giovanni Saggio.
Alessio Pomaro
Questi passi in avanti fanno capire l'importanza dell'evoluzione di queste tecnologie.
Un'intervista a Mustafa Suleyman (Microsoft)
Nei prossimi 15 anni il costo della produzione di conoscenza si avvicinerà allo zero, portando a un cambiamento radicale, e a un vero punto di svolta nella storia umana
- Mustafa Suleyman, Microsoft
Straordinario in termini di democratizzazione della conoscenza.
Un'intervista a Mustafa Suleyman di Microsoft
Ma ci sono solo alcuni aspetti da considerare: qualità e veridicità delle informazioni, impatto economico, etica e regolamentazione.
Una demo di ElevenLabs Voiceover Studio
Grazie a sistemi di Text-To-Speech (TTS) e alla clonazione vocale, la semplicità di editing è diventata davvero impressionante.
Basta aprire il microfono e registrare. Il sistema fa il resto.. da vedere.
Arriva Gemini su Colab
Il sistema permette di generare codice Python trasferibile nel notebook, ma anche di spiegare i notebook che vengono aperti in piattaforma.
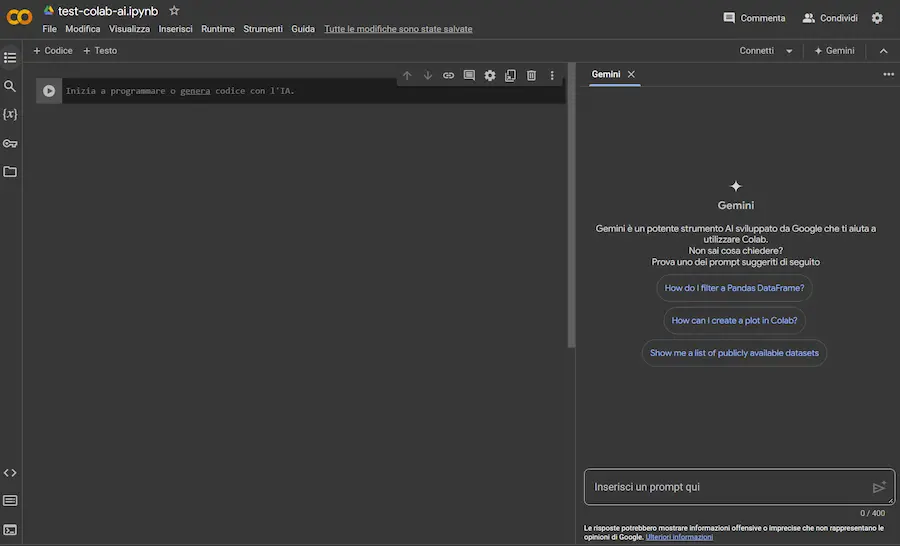
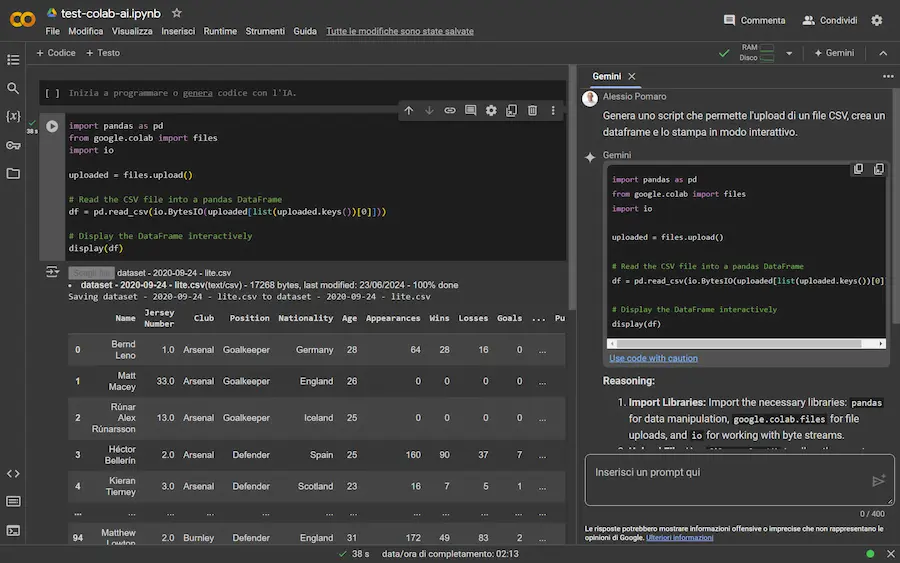
Esempi di utilizzo di Gemini su Colab
Unico neo attuale: 400 caratteri per un prompt di questo tipo sono davvero pochi.
CriticGPT: un modello per rilevare gli errori
Un paper di OpenAI molto interessante: hanno addestrato CriticGPT, un modello (basato su GPT-4) per rilevare errori nelle risposte di ChatGPT.
Le persone che ricevono aiuto da CriticGPT per rivedere l'output di ChatGPT superano le performance di chi non ha questo aiuto nel 60% dei casi.

Sistemi come questo, infatti, verranno integrati nei flussi di feedback umano per il rinforzo dell'addestramento dei modelli di AI.
AI Chat serverless con RAG
RAG con una libreria JavaScript e senza bisogno di configurazione server?
È possibile con LangChain.js e i servizi serverless di Azure per l'applicazione e il database vettoriale.
Questo è un passo in avanti importante, perché la componente di sviluppo rappresenta spesso uno scoglio anche in fase di R&D.
Con sistemi come questo, è possibile realizzare un POC con poco sforzo, e applicazioni strutturate con ridotto impatto sullo sviluppo.
Groqnotes: da audio a contenuto organizzato a una velocità incredibile
Groqnotes è un'applicazione semplicissima che sfrutta Whisper e Llama 3 attraverso le API di Groq.
Una demo di Groqnotes
Risultato: trasforma qualunque audio in un contenuto organizzato a una velocità impressionante (più di 1200 token/secondo).
Open-Sora 1.2
È stata rilasciata la versione 1.2 di Open-Sora, un progetto open source dedicato alla produzione efficiente di video.
Video generati usando Open-Sora 1.2
La qualità non è paragonabile alla generazione video alla quale siamo già abituati, ma migliorerà.
La sintesi vocale open source
L'Università di Stoccarda ha pubblicato IMS-Toucan, un toolkit dedicato alla sintesi vocale open source.
Completamente basato su Python e PyTorch. Quindi semplice e adatto a tutti, ma molto potente.
IMS-Toucan
Il team ha condiviso anche il dataset su cui si basa il sistema.
Google introduce la cache di contesto per le API di Gemini
Si tratta di un sistema che può memorizzare i token in input del modello, che nelle interazioni successive avranno un costo inferiore, garantendo anche una risposta più veloce.
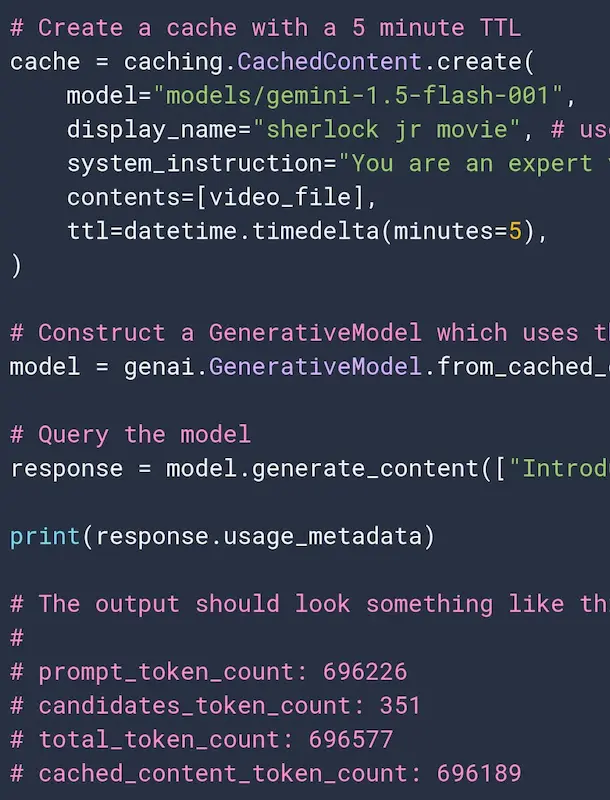
Sembra inutile? Sì, finché non iniziamo a ragionare su system prompt multimodali contenenti ore di video.
Gli investimenti in ricerca sono il motore dello sviluppo economico
Mi rendo conto che non sia un concetto semplice, perché l'effetto non può essere immediato. Ma forse, merita qualche riflessione.
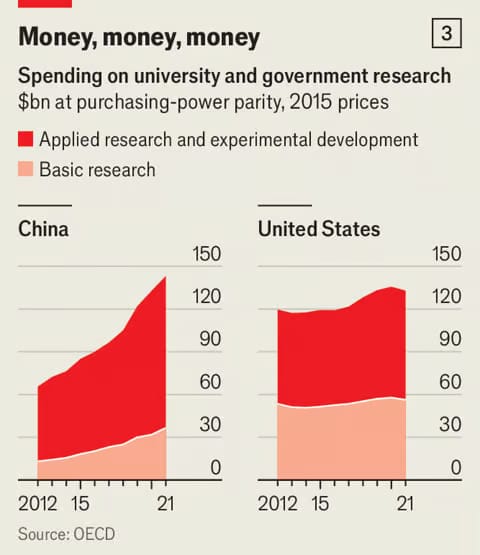
Anche in termini di una governance condivisa a livello internazionale.

OpenVLA: un VLM open source per il controllo robotico
OpenVLA è un VLM (Vision Language Model) open source per il controllo robotico.
OpenVLA, un VLM open source per il controllo robotico
Questo è un passo in avanti importante per rendere accessibili sistemi VLA (Vision Language Action).
I sistemi VLA, uniscono il VLM (comprensione semantica) a dati robotici di qualità (azione).
Un'estensione per PostgreSQL dedicata all'AI
pgVectorscale è una nuova estensione open source che rende PostgreSQL un database performante per applicazioni basate sull'AI.
Le prestazioni sono paragonabili, e spesso migliori, di database vettoriali specializzati come Pinecone.
 Avthar Sewrathan
Avthar Sewrathan
I due principi cardine del sistema sono: indice di ricerca vettoriale StreamingDiskANN, e quantizzazione binaria statistica (SBQ).
Le performance, a confronto con Pinecone,
sono devastanti.
Whisper WebGPU
Whisper WebGPU è un progetto che permette di avere un sistema di speech recognition basato su ML direttamente nel browser.
 xenova
xenovaIl modello viene eseguito in locale, quindi, potenzialmente, nessun dato lascia il dispositivo.
Spiegabilità dei modelli: il lavoro di OpenAI
Anche OpenAI è al lavoro sulla spiegabilità dei modelli, usando la stessa tecnica di Anthropic: "sparse autoencoders".
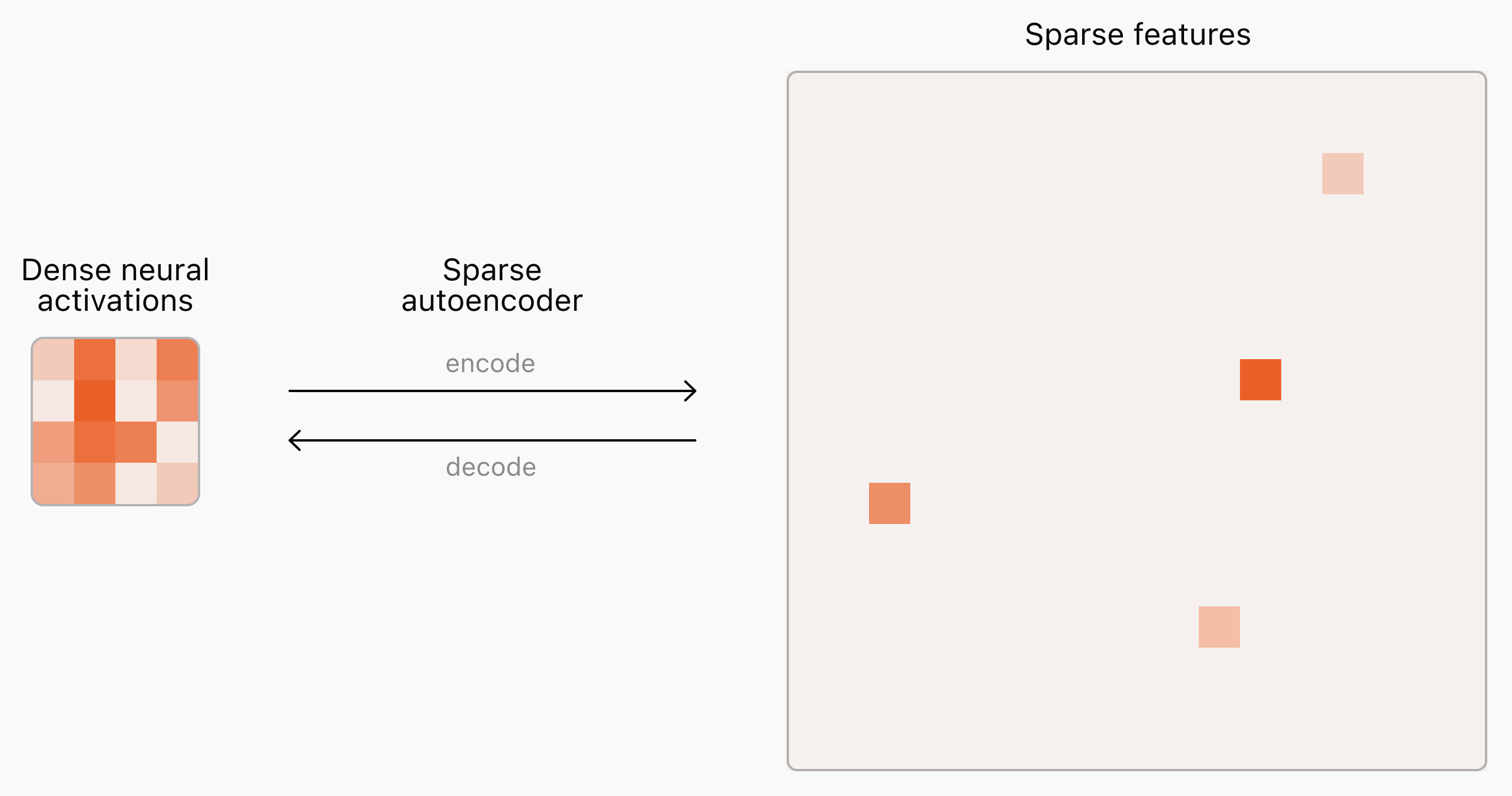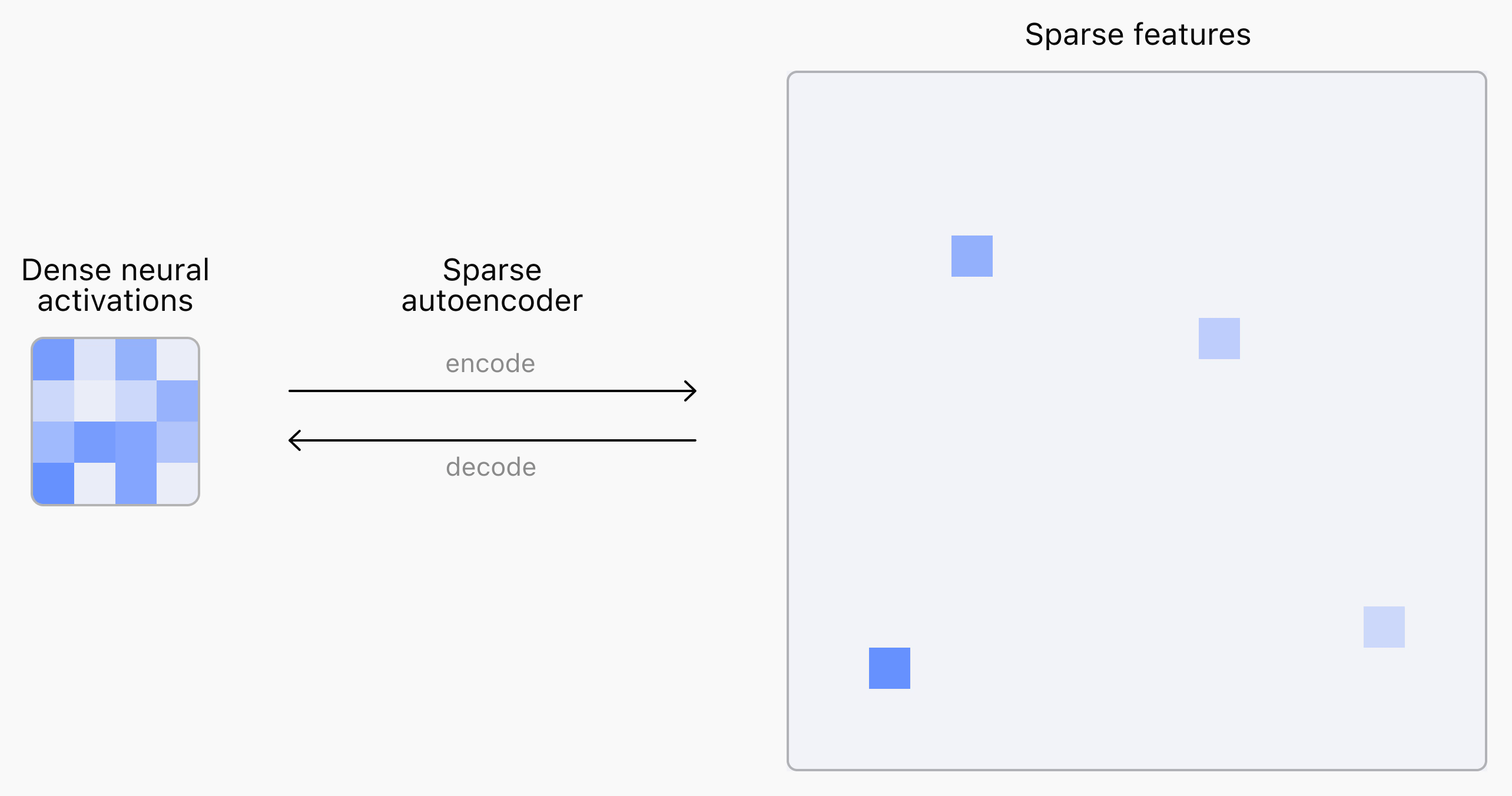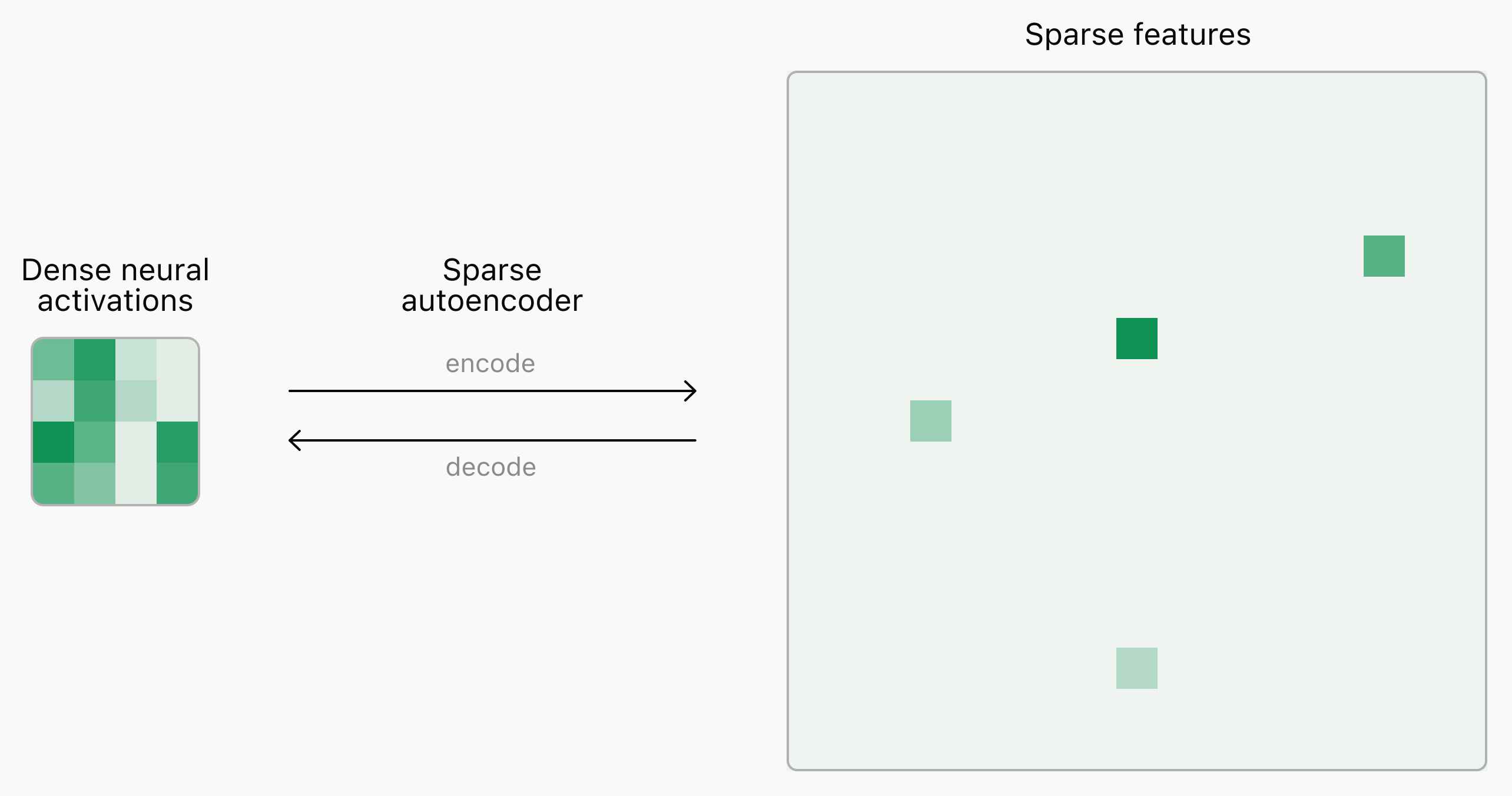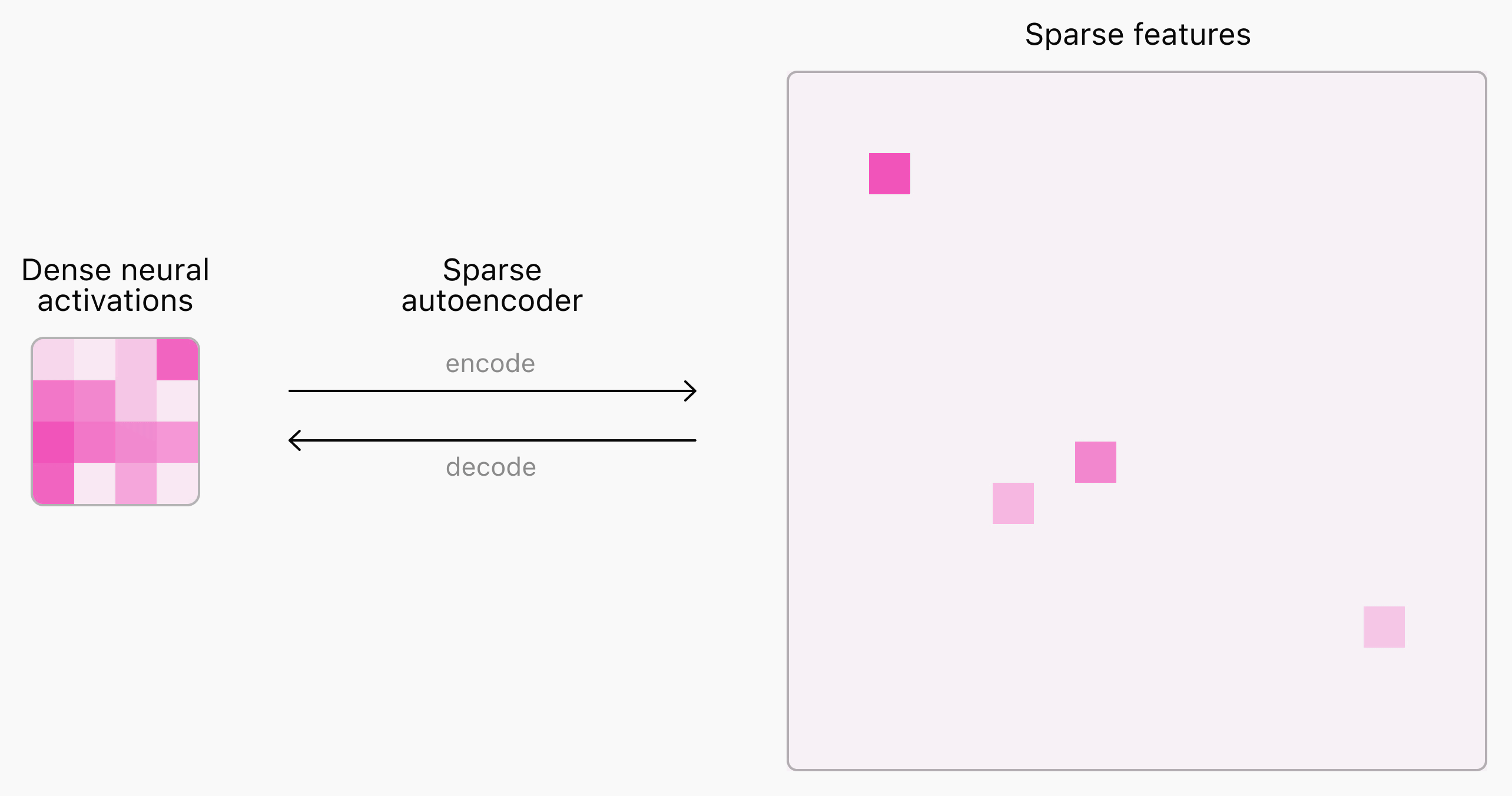
Questi sistemi permettono di individuare delle caratteristiche nell'attivazione della rete neurale, su determinati argomenti. Un piccolo passo in avanti, anche se la strada è lunga.
Considerazioni su Apple Intelligence
Perché l'AI di Apple sarà probabilmente la miglior esperienza di questo genere? Perché può contare su un vantaggio che gli altri player non hanno (al 100%): il controllo su hardware e software.
Questo garantirà un'integrazione più ampia, una conoscenza dell'utente superiore, e probabilmente maggior sicurezza.
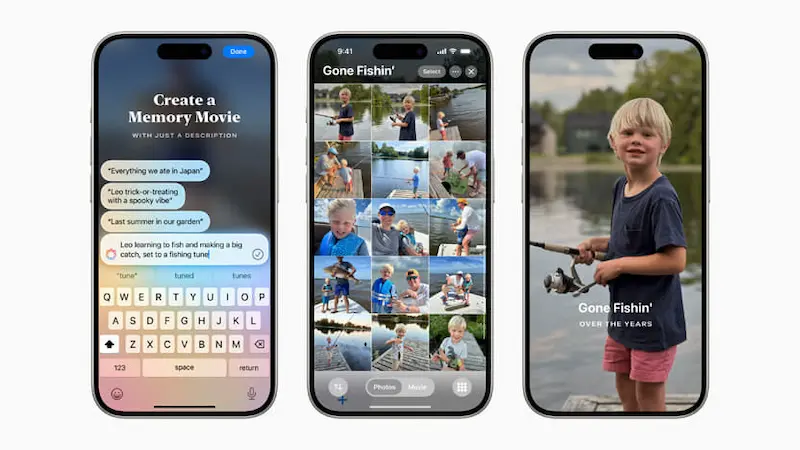
In fin dei conti, le funzionalità presentate da Apple sono le stesse già abbondantemente esplorate, compresa la formula che vede un modello piccolo in locale + l'estensione in Cloud per funzionalità superiori.
Ma se l'integrazione funzionerà e i modelli di Apple saranno all'altezza, non solo il gap sarà chiuso, ma potremmo vedere un vantaggio significativo.
Una grande mossa anche quella di integrare ChatGPT (e altri sistemi di terze parti) per alcune funzionalità.
Grazie a tutto questo, Siri, da sempre il peggior assistente virtuale, potrebbe avvicinarsi più di ogni altro a un livello di interazione vincente.
Prometheus-2: un LLM open source per valutare le risposte di sistemi RAG
Prometheus-2 è un LLM open source dedicato alla valutazione delle risposte dei sistemi RAG.
L'uso di un modello come "giudice" è un approccio comune, ma con problemi come la trasparenza, la controllabilità e il costo.
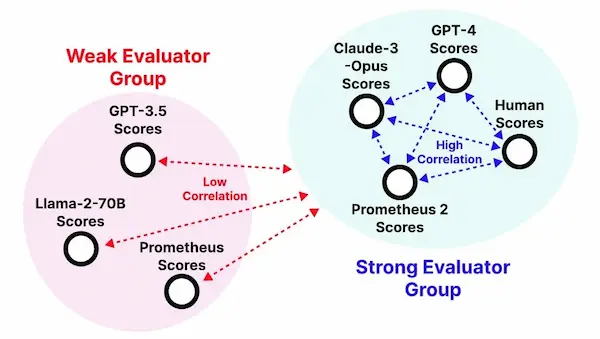
Le caratteristiche di Prometheus-2?
- È costruito su Mistral 7B e Mixtral 8x7B.
- Può dare valutazioni dirette, una classificazione a coppie, o con configurazioni di valutazione custom.
- Ottiene performance paragonabili a GPT-4, Claude 3 e la valutazione umana.
L'embedding multimodale di Nomic AI
Nomic AI mostra un esempio di embedding multimodale.
Uno spazio di incorporamento unificato per testo, immagini e altri elementi multimediali.
L'embedding multimodale di Nomic AI
Attraverso questo Colab è possibile vederlo in azione come RAG, con la capacità di estrarre elementi testuali e immagini.
Stabile Audio Open
Stability AI ha rilasciato Stabile Audio Open, un modello open source text-to-audio.
Permette di generare tracce audio da 47 secondi, ad esempio con riff strumentali, ritmi di batteria, suoni ambientali, ecc..
 Guest User
Guest User
Un'ottima risorsa da usare in fase di montaggio di output digitali.
Code Transformation
Google ha rilasciato Code Transformation, uno strumento per la modifica e l'ottimizzazione automatizzata del codice Python.
Google Code Transformation
Sono possibili diverse azioni, come la pulizia, la correzione e la creazione della documentazione. E viene creato un file "diff" che illustra i cambiamenti del codice.
Il sistema permette anche di usare il linguaggio naturale per creare automaticamente notebook Python per l'analisi di dataset. E con un clic si esegue su Colab.
G-Assist di Nvidia
Nvidia presenta il progetto G-Assist: un assistente per giochi e app.
Il sistema riceve input vocali o di testo, e può "vedere" lo schermo. Con questo contesto, il modello, che è connesso a una knowledge sul gioco o sull'app, offre risposte e consigli.
Questi modelli vengono eseguiti in Cloud e accelerati localmente da PC e laptop AI GeForce RTX.
G-Assist di Nvidia
L'assistente è anche in grado di valutare l'hardware e configurare i giochi per un'esperienza ottimale.
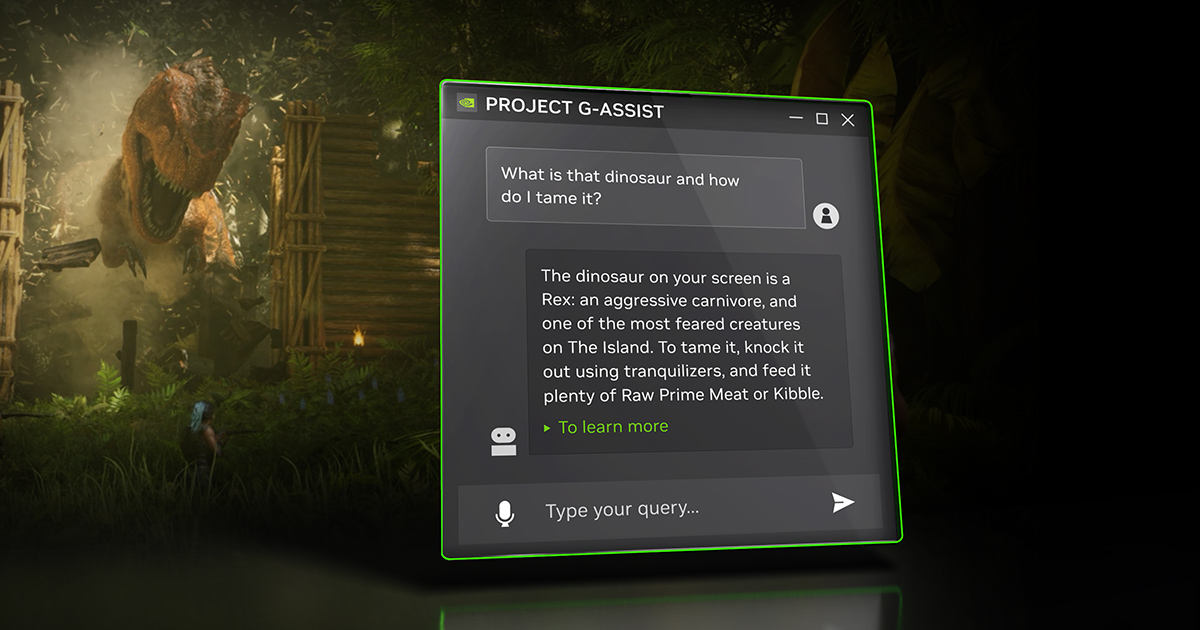
Avremo un assistente per tutto?
Wllama: l'esecuzione del LLM nel browser
Wllama è un progetto che permette di eseguire l'inferenza del modello di linguaggio direttamente nel browser.
Senza back-end, e senza GPU. Il tutto basato su WebAssembly SIMD.

Con tutte le limitazioni del caso, ma per certi tipi di applicazioni semplici è un approccio davvero interessante.
RAG potenziato da Knowledge Graph
Llamaindex mostra le soluzioni per creare un sistema RAG (Retrieval-Augmented Generation) potenziato da knowledge graph.
È possibile realizzarlo in diversi modi, ad esempio con la ricerca vettoriale + il confronto sul grafo, oppure con un sistema text-to-cypher.
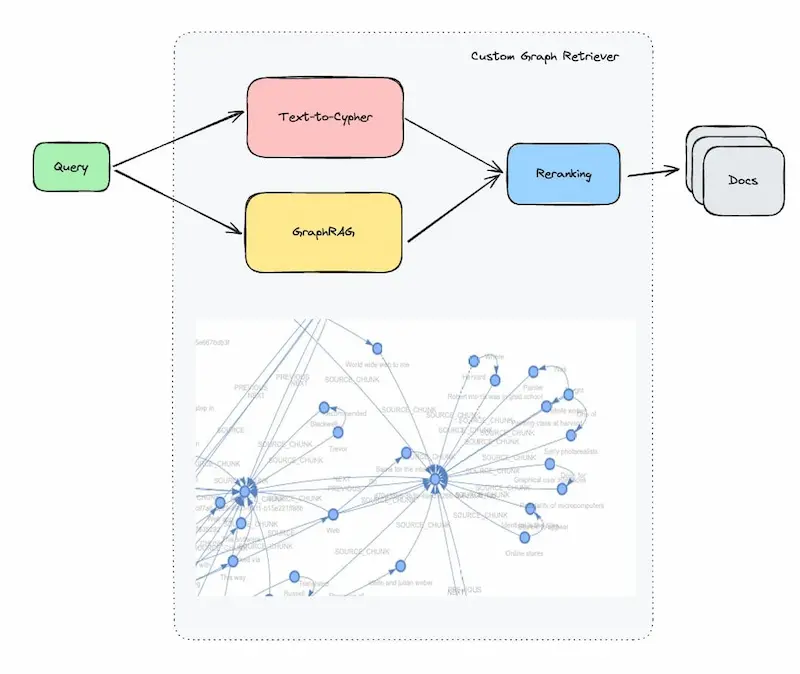
L'uso della ricerca vettoriale guidata dal grafo permette soluzioni più affidabili e sicure.
"Tool Use" di Anthropic
Anthropic fa evolvere Claude, lanciando una nuova funzionalità definita "Tool Use".
Il nuovo sistema permette al LLM di interagire con API e strumenti esterni per creare automazioni e integrazioni.
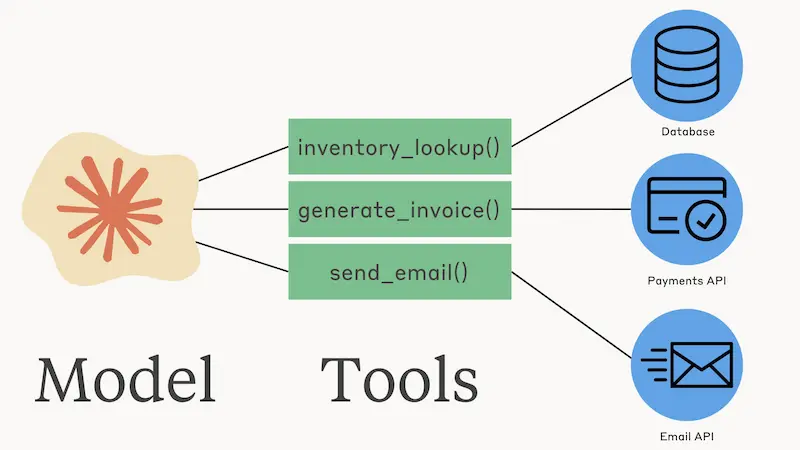
Il tutto a disposizione attraverso le API del modello, via Amazon Bedrock e via Vertex AI di Google.
Era3D: Image To 3D
Era3D è un nuovo modello che permette di creare modelli 3D da un'immagine in input.
Era3D: Image To 3D
Nell'esempio viene caricata un'immagine di Yann LeCun, viene rimosso lo sfondo e creato il 3D a 360°.
Le allucinazioni dei modelli di linguaggio
Uno studio molto interessante di Stanford, mostra le allucinazioni prodotte da sistemi RAG (Retrieval-Augmented Generation) nel mondo legal. Il lavoro per ridurle è notevole, ma rimane un "problema" importante.
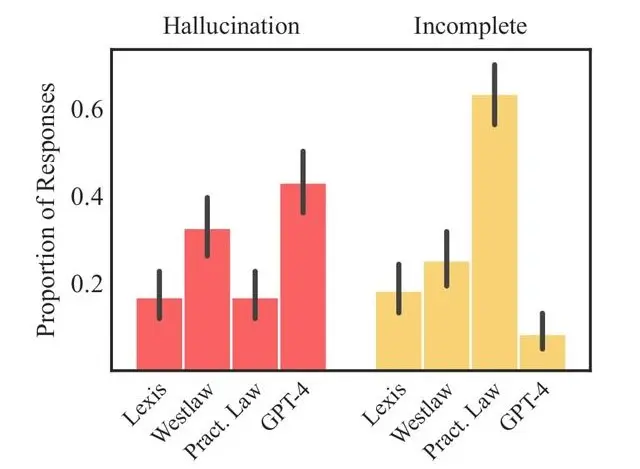
Tuttavia, lavorando su informazioni delicate dove le entità e le loro relazioni sono determinati, credo sia necessaria un'architettura basata su knowledge graph + LLM.
- GRAZIE -
Se hai apprezzato il contenuto, e pensi che potrebbe essere utile ad altre persone, condividilo 🙂