Generative AI: novità e riflessioni - #3 / 2024
Un appuntamento per aggiornarsi e riflettere sulle tematiche che riguardano l'intelligenza artificiale e la Generative AI.


Una rubrica che racconta le novità più rilevanti che riguardano l'Intelligenza Artificiale, con qualche riflessione.
Buon aggiornamento,
e buone riflessioni..
Figure 01 in azione con un modello di OpenAI a bordo
I video di Figure 01 hanno fatto il giro del mondo, con grande stupore.
Ma se ci pensiamo, la multimodalità dei moderni modelli che usiamo ormai regolarmente è a livelli degni di nota. Non solo GPT-4 con Vision, ma anche Claude 3, e soprattutto Gemini 1.5 Pro, in grado di processare anche audio e video senza trascrizioni, con finestre di contesto enormi e grande precisione.
Figure 01: un modello di linguaggio unito alla robotica
Per provare l'esperienza basta caricare delle immagini su ChatGPT e provare a fare delle domande simili a quelle che vengono poste al robot.
In questa simulazione, ne vediamo un esempio.
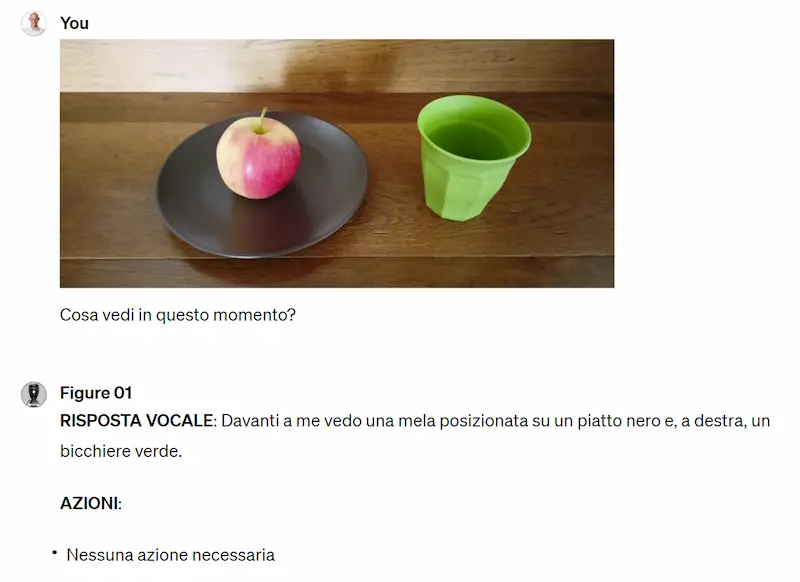
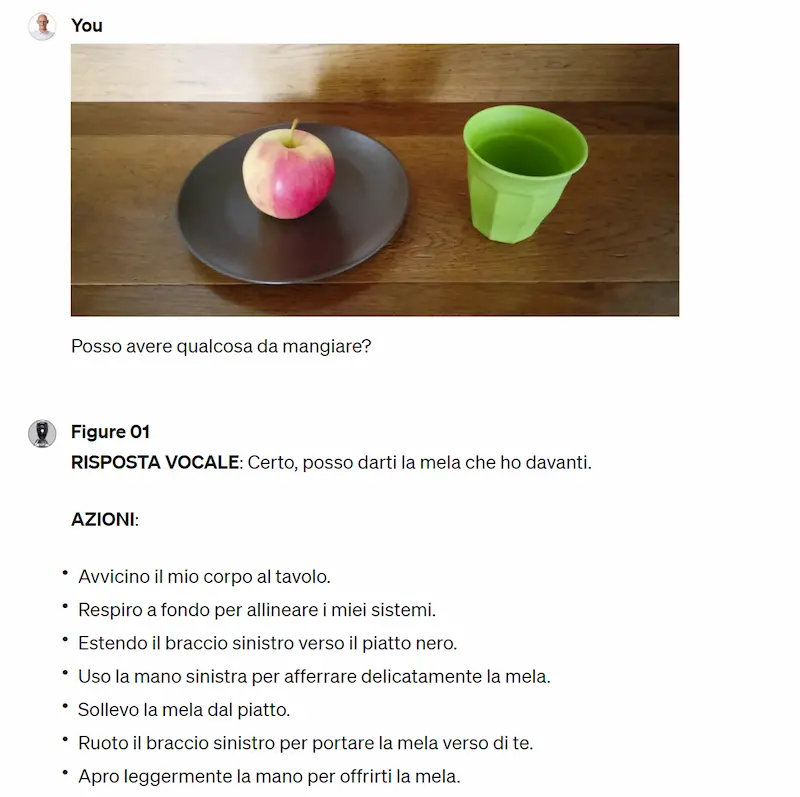
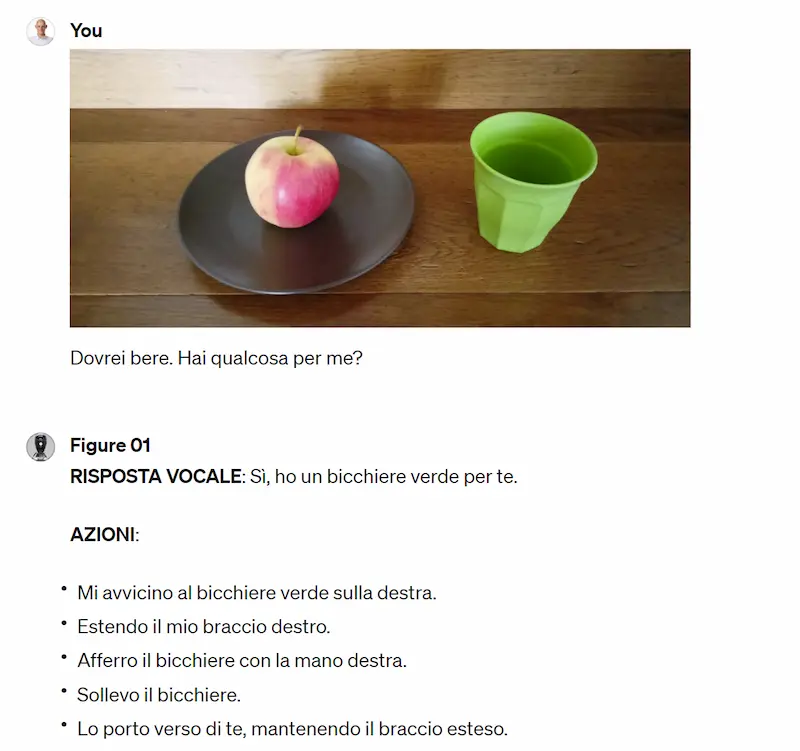
Una simulazione usando GPT-4 Vision
Già RT-2 di Google univa un VLM (Vision Language Model) a dati robotici di qualità con risultati straordinari.
I modelli generativi danno ai robot la "comprensione del mondo", grazie alle relazioni semantiche derivanti dal training. È così che il robot associa la mela quando gli viene chiesto "qualcosa mangiare". La componente robotica aggiunge i movimenti.
L'altro aspetto innovativo riguarda la quantità di analisi dell'ambiente circostante che producono i robot: questo garantisce la reattività alla variazione dello scenario.
Gemini 1.5 Pro: primo test
Ho provato Gemini 1.5 Pro, il nuovo modello di Google su AI Studio, processando:
- il video del mio intervento all'AI Festival (20 minuti, in italiano);
- il video della presentazione di Ernie 4 (3 minuti, in cinese).
L'interazione avviene in italiano.
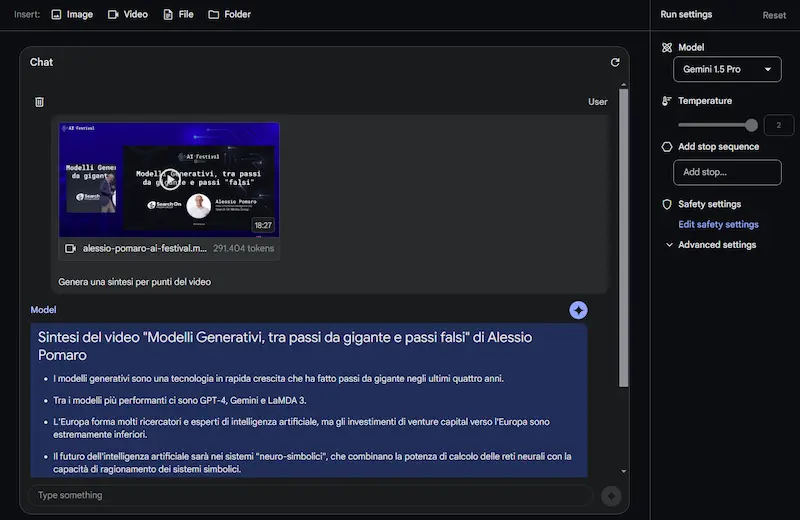
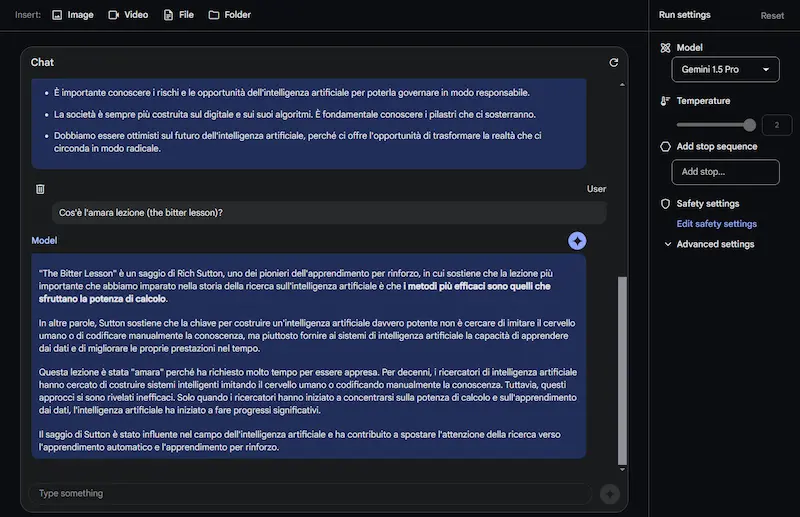
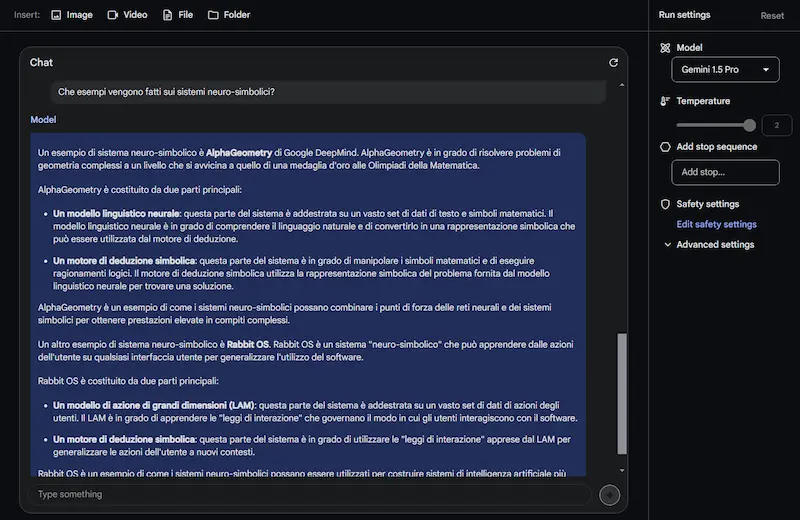
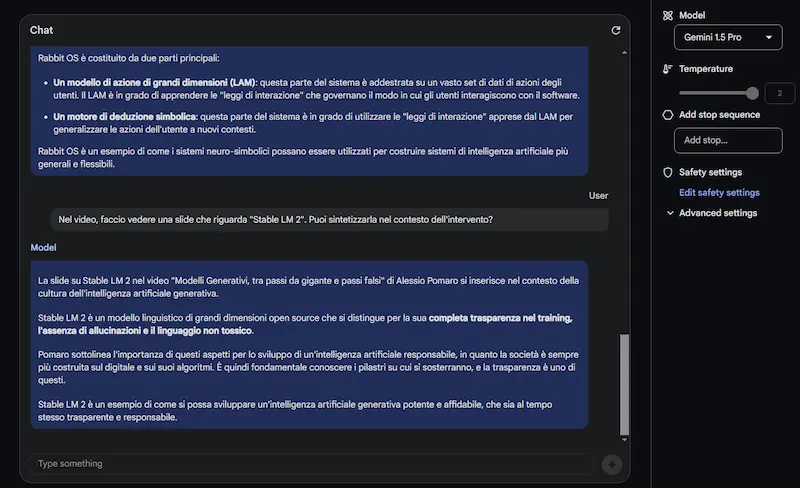
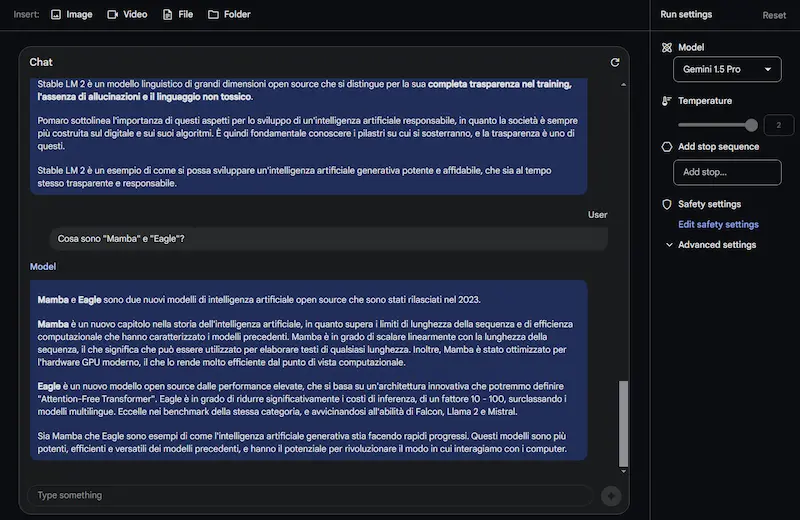
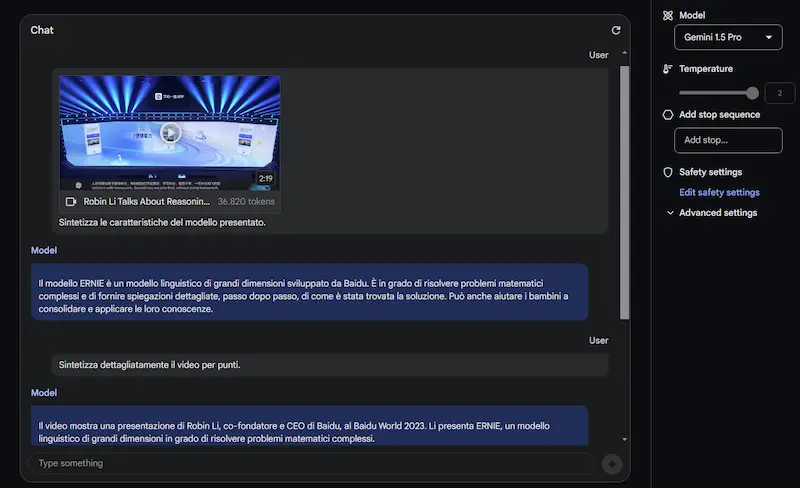
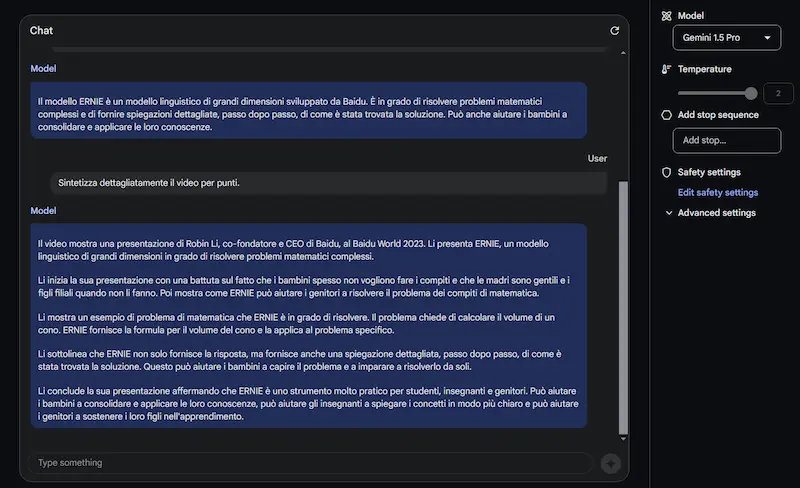
Test di Gemini 1.5 Pro
Come si vede dalle immagini, oltre alle sintesi, pongo domande specifiche, anche su ciò che compare a video (non solo sul parlato).
Il modello offre risposte abbastanza precise. I tempi di risposta non sono rapidissimi, ma si tratta dei primi passi verso una multimodalità così evoluta.
Il concetto di LLM che elabora le trascrizioni dei file multimediali scomparirà molto presto. E immaginiamo quando tutto questo avverrà in real-time a bordo di un robot.
L'evoluzione di Open Interpreter: Light 01
L'evoluzione di Open Interpreter continua, e presenta 01 Light: un'interfaccia vocale portatile che può controllare qualunque operazione di un computer remoto.
L'evoluzione di Open Interpreter: Light 01
Può "vedere" lo schermo, utilizzare le applicazioni e apprendere nuove competenze.
Ma l'aspetto più interessante è che si tratta di un sistema completamente open source, che può diventare la base di sviluppo di dispositivi e applicazioni custom.
Nel video si vedono esempi di interazioni (anche strutturate) con il dispositivo, e il sistema esegue i comandi perfettamente.
È possibile acquistare il dispositivo completo. Per i developers, viene fornito il progetto completo: software, file CAD, schemi di cablaggio.
Abbiamo imparato a conoscere sistemi di questo tipo dopo il CES con Rabbit, ma in questo caso si apre una parentesi che mette a disposizione un sistema pronto allo sviluppo per chiunque.
AI Generativa e creatività
"Ora abbiamo la possibilità di approfondire storie che prima ritenevamo impossibili"
È proprio questo uno degli aspetti interessanti dell'AI generativa applicata alla creatività.
La possibilità di sperimentare, ottenendo buoni output a costi estremamente contenuti.
"Air Head", un cortometraggio realizzato usando Sora di OpenAI
Il video mostra un esempio di un cortometraggio realizzato da Shy Kids usando Sora, dal tiolo "Air Head".
"As great as Sora is at generating things that appear real - what excites us is its ability to make things that are totally surreal"
Voice Engine di OpenAI
OpenAI presenta un'anteprima di "Voice Engine", il suo modello vocale, che permette la creazione di voci sintetiche personalizzate.
Ricevendo in input un breve testo e un campione vocale di 15 secondi, riesce a generare un parlato dal suono naturale, che riproduce la voce.

In realtà il modello esiste da tempo, e il risultato è quello che possiamo sentire nell'app mobile di ChatGPT. Ma OpenAI va cauta, per gestire al meglio queste funzionalità in termini di sicurezza.
I rischi esistono, ma esistono anche applicazioni che possono migliorare la qualità delle esperienze. Trovare il giusto equilibrio sarà determinante.
Midjourney Consistent Character
Negli esempi vediamo come si possano mantenere le caratteristiche di un prodotto nella generazione di immagini attraverso Midjourney.
La funzionalità è "Consistent Character", e si utilizza attraverso il parametro "cref".



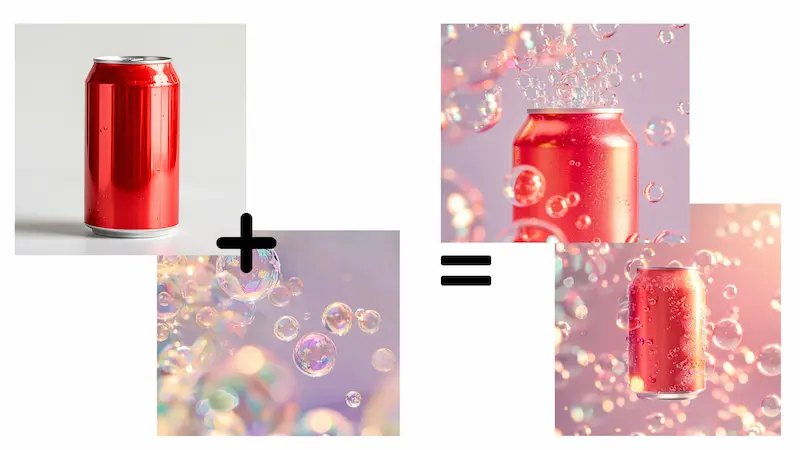
Esempi di applicazioni di Midjourney "Consistent Character"
Nel seguente post, è possibile analizzare un esempio di prompt in cui viene usata la funzionalità (del creator che ha generato queste immagini).
Prompt:
— Salma (@Salmaaboukarr) March 27, 2024
A closeup of delicate soap bubbles floating in the air, with a soft pastel background that adds to their ethereal beauty. The focus is on capturing the intricate details and reflections within each bubble, creating an enchanting atmosphere in the style of the artist. A…
Forse non si ha ancora margine di manovra al 100%, ma i progressi sono evidenti.
L'accordo tra Accenture, AWS e Anthropic
Claude 3 ha superato GPT-4.. ma c'è un aspetto ancora più interessante e strategico, ovvero l'alleanza tra Anthtopic, AWS e Accenture.
Che mette insieme la generative AI + un sistema cloud che permette qualunque implementazione immaginabile + un'ampia organizzazione per la system integration.
Un accordo che va a rispondere al vero problema attuale:
c’è più richiesta di implementazione che disponibilità di risorse qualificate per adattare le soluzioni di intelligenza artificiale generativa alla produzione.
A che punto siamo con la qualità del deepfake?
Dal punto di vista tecnologico il livello è tale da rendere quasi impossibile il riconoscimento rispetto a un video reale.
Un esempio della qualità dei deepfake realizzabili con l'attuale tecnologia
La necessità di contromisure efficaci rimane altissima.. quanto il bisogno di alzare il livello di cultura su sistemi che miglioreranno sempre di più.
DBRX di Databricks
Databricks ha presentato DBRX: un nuovo LLM open dalle performance superiori a Grok, Mixtral 8x7b e Llama 2 70b, e di poco inferiori a Claude 3 Haiku.

Ha un'architettura MoE (Mixture of experts), con circa il 40% delle dimensioni di Grok (132B di parametri), ed è 2 volte più veloce (in inferenza) di Llama 2.
Uno dei segreti delle performance è la configurazione di MoE: rispetto a Mixtral e Grok, DBRX usa più "esperti" più piccoli.
È stato addestrato su 12T di token e fornisce una finestra di contesto di 32k token.
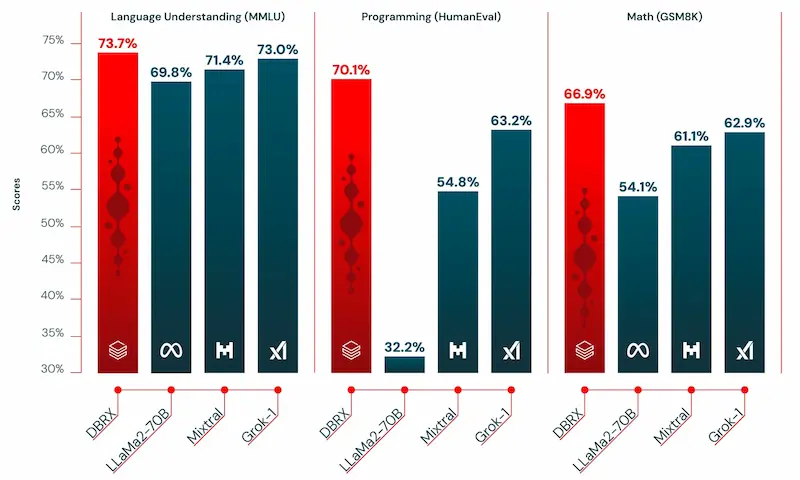
DBRX di Databrick: performance e test
Su task RAG supera GPT-3.5 Turbo.
La tecnologia migliora, e ormai abbiamo modelli aperti dalle performance elevatissime.
Un semplice framework per creare un sistema multi-agente
"Maestro" è un piccolo framework in cui il prompt viene suddiviso in micro attività da un agente "manager", e ogni attività viene eseguita da agenti distinti. Infine il manager revisiona il lavoro svolto dagli agenti per generare l'output.
Il manager viene gestito da Opus, mentre gli agenti da Haiku.
 Doriandarko
DoriandarkoSe si osserva il codice, è davvero molto semplice (poco più di 150 righe di Python) e può essere un'ottima base per automazioni interessanti.
La stessa logica può essere riprodotta con qualunque LLM, usando anche modelli più piccoli e open source per i micro task.
Claude 3 Opus supera GPT-4 nella Chatbot Arena Leaderboard
Credo sia la prima volta che un modello supera il top di OpenAI.

La notizia ormai sta spopolando. Ma ci tengo sempre a ricordare che ci stiamo riferendo a una tecnologia del 2022.
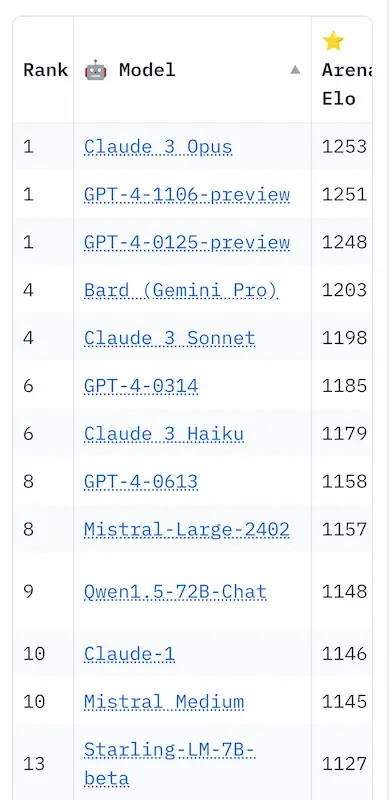
La vera notizia sono le performance della versione Haiku, disponibile anche su Perplexity Labs.
Come funziona la ricerca vettoriale? Una Spiegazione semplice.
Oggi si parla sempre di più dei sistemi RAG (Retrieval Augmented Generation), che si basano sull'unione tra LLM e la ricerca vettoriale (embeddings).
Come funziona la ricerca vettoriale? Spiegazione semplice: estrae le informazioni più simili alla query di ricerca da un database che rappresenta l'archivio di documenti. Tali informazioni, diventano il contesto per un LLM che genera la risposta alla query.
L'estrazione delle informazioni avviene, ad esempio, attraverso la "similarità del coseno", ovvero misurando il coseno dell'angolo tra il vettore che rappresenta la query e quelli contenuti nel database vettoriale. Il tutto dopo aver ridotto le dimensioni delle rappresentazioni vettoriali.
È sempre affidabile? Non sempre..
Ecco perché l'unione di questa tecnica ai grafi di conoscenza (knowledge graph) sembra essere una via molto interessante per aumentare l'affidabilità.
Attraverso i grafi possiamo relazionare i vettori delle parti dei documenti (chunk). In questo modo possiamo considerare i documenti nel loro insieme, non solo come una raccolta sparsa si embeddings. E possiamo relazionare i documenti ad altre informazioni strutturate.
Sistemi ibridi di questo tipo consentono maggior precisione nella determinazione delle relazioni tra le entità comprese le connessioni strutturali e temporali.

Linee guida per un utilizzo responsabile dell'AI generativa
L'Unione Europea, insieme ai paesi dell'European Research Area, ha presentato delle linee guida per supportare la comunità di ricerca europea nell'utilizzo responsabile dell'AI generativa.
Si tratta di un importante riferimento, perché questi sistemi stanno rapidamente trovando applicazione in tutti i settori, inclusa la scienza.
Le linee guida enfatizzano la necessità di trasparenza e responsabilità nell'uso dell'AI, promuovendo l'integrità scientifica e preservando la fiducia pubblica nella scienza.
Le organizzazioni di ricerca e i finanziatori vengono incoraggiati a facilitare l'uso responsabile dell'AI generativa e a monitorare attentamente lo sviluppo e l'applicazione di questi strumenti.


RAG + modello a 7b: test
Come se la caverebbe un LLM "piccolo" per generare la risposta finale di un sistema RAG?
Il test si basa su un recupero da database vettoriale con embeddings generati attraverso i modelli di OpenAI.
Una volta estratti i chunk dal db con una query vettoriale, la risposta viene generata attraverso Mistral 7b.

Come si vede, funziona abbastanza bene. Sistemi con questa configurazione potrebbero agire direttamente in locale, anche su uno smartphone, senza scambiare dati con un modello in cloud.
Tutto bellissimo? Non tutto. Vediamo alcune note.
- Il cuore del sistema si basa sulla qualità della vettorializzazione dei dati. Più il modello è performante, e più sarà in grado di rappresentare la semantica dei contenuti.
- Se le risposte necessitano di elaborazione, un modello piccolo non sarà sempre sufficiente.
Come funziona l'architettura "Diffusion Transformer" alla base di modelli come Sora e Stable Diffusion 3?
Vediamo una spiegazione semplice.
- L'architettura rappresenta una tecnica innovativa nel campo della generazione di immagini con l'AI. Immagina che la tecnologia di trasformazione (transformer) sia come un artista che dipinge un quadro, e i modelli di diffusione siano come la tecnica che usa per creare l'opera.
- Inizialmente, i modelli di diffusione lavoravano come se l'artista iniziasse con una tela piena di macchie casuali (rumore) e, passo dopo passo, rimuovesse queste macchie per rivelare l'immagine finale. La tecnologia transformer, che prima era usata principalmente per elaborare il testo, ora è come se desse all'artista un metodo più sofisticato per decidere quali macchie rimuovere e in quale ordine, migliorando la qualità e l'efficienza del quadro finale.
- Con "Diffusion Transformer", invece di lavorare direttamente sull'immagine intera (che richiederebbe molta potenza computazionale), l'artista lavora su una versione compressa dell'immagine, chiamata spazio latente. È come se riducesse l'immagine a un insieme più piccolo di elementi essenziali, rendendo il processo più gestibile.
- Durante il processo di "pittura" (generazione dell'immagine), il transformer analizza e manipola questi elementi essenziali per rimuovere le macchie (rumore) e, passo dopo passo, svela l'immagine desiderata. Questo metodo non solo migliora la qualità delle immagini generate ma lo rende anche più efficiente, permettendo di creare immagini complesse senza richiedere una potenza di calcolo eccessiva.
Come funziona Sora?
In breve, "Diffusion Transformer" è come un artista avanzato che utilizza una tecnica raffinata per creare capolavori, rendendo il processo più veloce, efficiente e capace di produrre risultati di alta qualità.
Sicurezza dei Large Language Model
Un paper davvero interessante! Gli autori hanno rilasciato un metodo per estrarre informazioni precise dai modelli di linguaggio.
L'attacco estrae la matrice di proiezione dei modelli Ada e Babbage di OpenAI sfruttando chiamate API (con meno di 20$).
Stimano che con circa 2k $ si riuscirebbe ad estrarre l'intera matrice di proiezione di GPT-3.5 Turbo.
Lo studio dimostra come sia possibile ottenere informazioni significative su LLM complessi senza averne un accesso diretto, sollevando questioni sulla sicurezza.
Prompt Engineering: note interessanti
Sono davvero contento di leggere questo post di Andrew Ng.
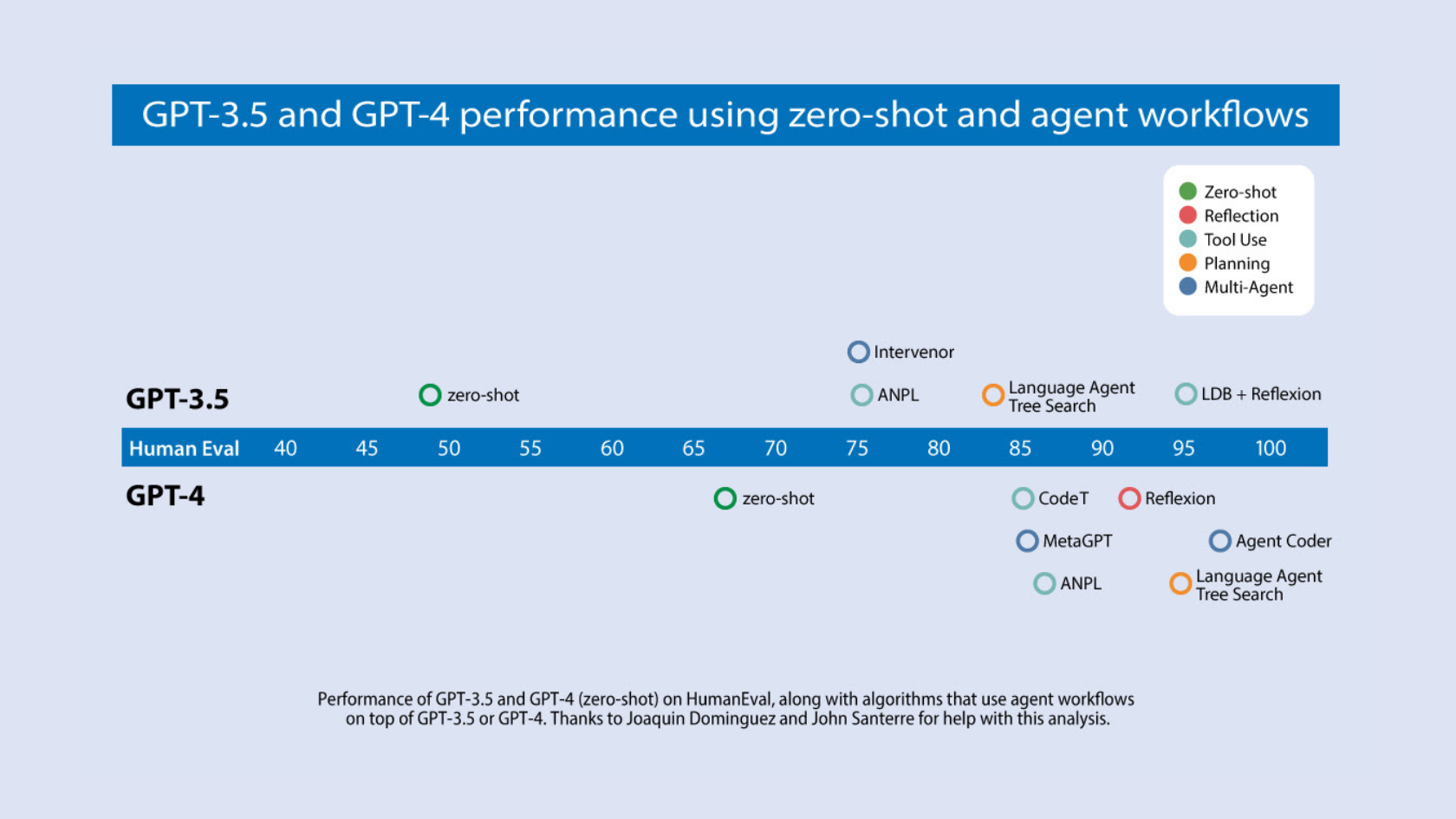
Parla di tecniche multi agente per usare i LLM per generare contenuti seguendo un flusso di..
- generazione di una bozza,
- valutazione della bozza per mettere in evidenza gli aspetti da migliorare,
- creazione di una nuova bozza migliorata in base alle valutazioni,
- fino ad ottenere un risultato soddisfacente.


Prompt Engineering: note interessanti
Sono contento perché usiamo questa tecnica da molto tempo per contenuti, traduzioni e altre elaborazioni, condividendola anche nei nostri seminari.
MM1 e l'AI generativa di Apple
Apple avanza nello sviluppo di sistemi basati sull'AI generativa, e pubblica un documento di ricerca su MM1.
Si tratta di una famiglia di modelli multimodali addestrati su dati testuali e visuali.

Saranno i primi test per la nuova generazione di Siri?
Code Interpreter: non solo esecuzione di script
In questo esperimento si vede come sia possibile usare Code Interpreter di ChatGPT come ambiente, e non solo per l'esecuzione di uno script.
Ho caricato su ChatGPT un JSON contenente tutti i contenuti del mio blog e ho dato indicazioni per salvare tutti i post in un PDF (uno file ogni post). Il sistema ha eseguito l'operazione inserendo i file PDF in una directory.
Successivamente, in un altro scambio, ho dato istruzioni per zippare la directory in modo da scaricare l'archivio.

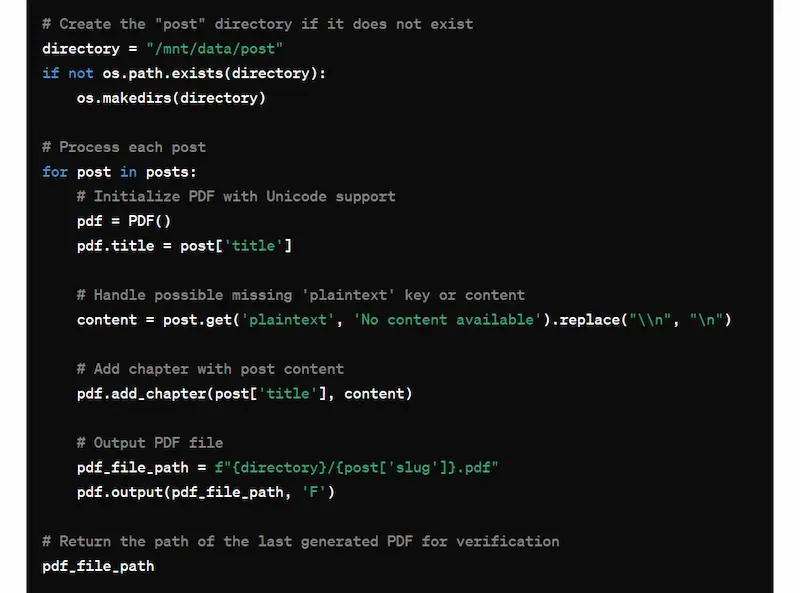
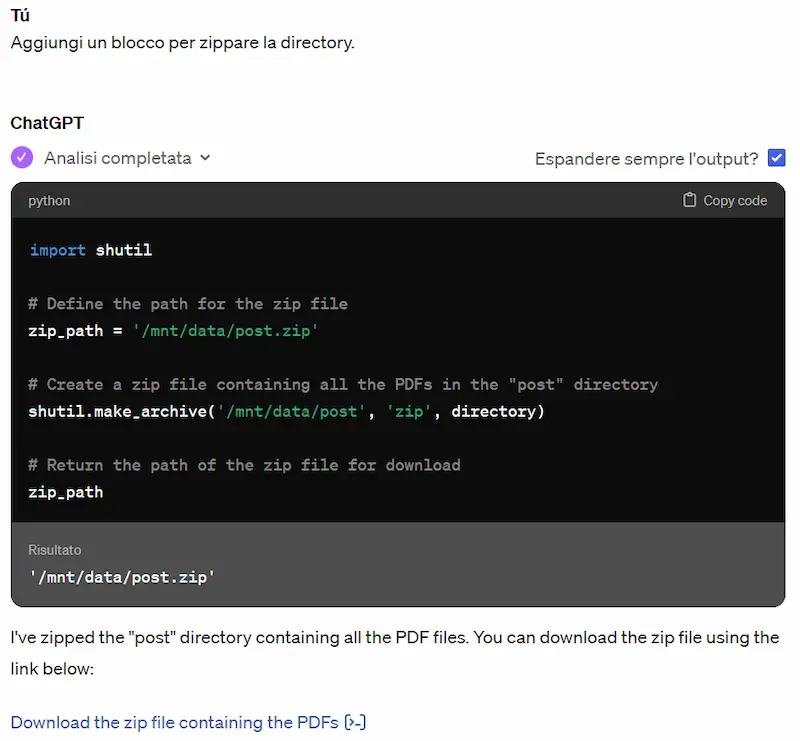
Code Interpreter: test di esecuzione come ambiente
Quindi il sistema ha creato la directory e i file in uno spazio temporaneo, che diventa parte del contesto per il modello. Successivamente, crea l'archivio e permette di scaricarlo.
Stable Video 3D
Stability AI, con la presentazione di Stable Video 3D dimostra l'avanzamento dei modelli non solo nella generazione video, ma anche degli oggetti 3D.
 Anel Islamovic
Anel Islamovic
L'input è l'immagine di un oggetto. Il sistema genera visualizzazioni multiple di quell'oggetto per produrre un mesh 3D.
SIMA di Google DeepMind
Google DeepMind ha presentato SIMA (Scalable Instructable Multiworld Agent), un sistema che permette a un agente AI generale di comprendere molti "mondi di gioco" e di seguire istruzioni in linguaggio naturale per eseguire azioni al loro interno.
SIMA (Scalable Instructable Multiworld Agent) di Google DeepMind
Il sistema è stato istruito attraverso coppie di giocatori, in cui uno dà le istruzioni e l'altro le esegue nel gioco.
Gli unici input di SIMA sono le immagini dello schermo e le istruzioni per le azioni da compiere, e usa le uscite di mouse e tastiera per "giocare".. come farebbe un essere umano.
Tutto questo apre nuovi scenari verso agenti generalisti che si muovono nello spazio cogliendo istruzioni in linguaggio naturale.

Pensiamo ad applicazioni come la robotica, magari in scenari di assistenza per persone con disabilità motoria.
Grok viene rilasciato come progetto open source
Forse il rilascio di Grok come modello open source è passato leggermente in sordina.
Ma si tratta del più grande e performante LLM aperto esistente.
314 miliardi di parametri, e grazie all'architettura MoE, tiene 86 miliardi di parametri sempre attivi.
Supera LlaMa 2 70B e Mixtral 8x7B nel benchmark MMLU.
xai-orgL'evoluzione delle infrastrutture hardware dedicate all'AI generativa
Meta, a gennaio, aveva parlato dell'infrastruttura da 600k H100 Nvidia.. ecco il progetto completo, ed è impressionante.
 Kevin Lee
Kevin Lee
Da qui nasceranno i futuri modelli, come Llama 3 e i futuri servizi basati sull'AI, verso un ideale concetto di AGI.
Nel frattempo Nvidia annuncia Blackwell, una nuova architettura che rende le GPU molto (MOLTO) più veloci, con un consumo molto (MOLTO) inferiore.
/cdn.vox-cdn.com/uploads/chorus_asset/file/25343060/NVIDIA_Blackwell_Architecture_Image.jpg)
La potenza di calcolo non sarà più un limite. Le performance aumenteranno. Ma potrà ancora essere la leva primaria della crescita? Lo scopriremo presto.
Vlogger di Google
Dopo EMO di Alibaba, ecco Vlogger, un modello in grado di generare video di persone che si esprimono partendo da un'immagine, testo e audio.
Il modello non lavora su un ritaglio del volto, ma genera l'immagine completa, rendendo l'output più realistico.
Esempi di applicazione di Vlogger
Non solo generazione, ma anche editing e traduzione.
I video di esempio della pagina di GitHub sono impressionanti.
RAG multilingua: un test interessante
Tutti i contenuti del mio sito web (lingua italiana) sono stati suddivisi in parti (chunk), trasformati in embeddings e salvati in un database vettoriale (Pinecone).
Le domande che faccio all'agente, vengono trasformate in embeddings, e con una query vettoriale nel db vengono estratti i chunk più simili.
Queste parti, grazie alla natura degli embeddings, sono le più "vicine" dal punto di vista semantico alla query.
Le componenti testuali dei chunk diventano il contesto per il modello di linguaggio (GPT-4), che, grazie a un system prompt ben strutturato, genera la risposta.
Esempi di interazione con un sistema RAG in lingue diverse rispetto ai contenuti della knowledge
Come si vede, però, le domande e le risposte del modello sono in inglese e in tedesco. Mentre i contenuti della knowledge sono in italiano.
Si tratta di una dimostrazione del potenziale della ricerca semantica. Ed ecco perché spesso dico che, per questi sistemi, la lingua passa in secondo piano.
Pensiamo, ad esempio, a come può potenziarsi il customer service, la consultazione della manualistica, e la ricerca.
I modelli di linguaggio a 1 bit
Cosa sono i LLM a 1 bit e perché sono interessanti per il futuro? Ad esempio BitNet di Microsoft.
Solitamente i parametri di un modello vengono salvati a 16 o 32 bit. Per questo non possiamo fare funzionare (ad esempio) GPT-4 in locale: tanti parametri + dimensioni enormi.
Facendo un rapido calcolo, un modello con 7 miliardi di parametri (7b) ha bisogno di circa 27GB di memoria.
Nei sistemi a 1 bit, viene usato solo 1 bit (zero o uno) per memorizzare i parametri. Lo stesso modello dell'esempio precedente, necessità quindi di circa 0,8 GB di memoria.
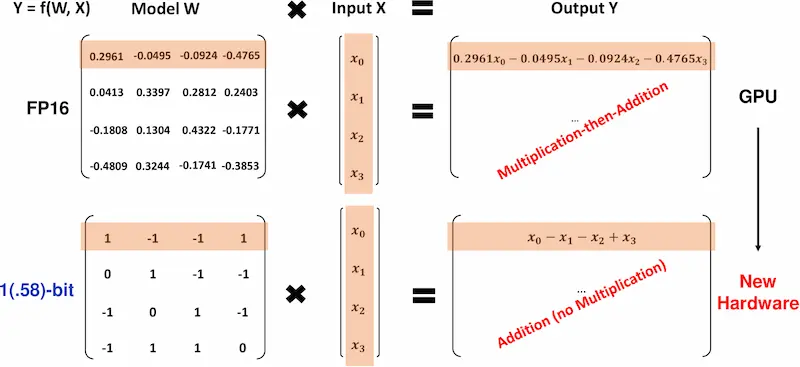
Ecco perché sono sistemi interessanti: possono far funzionare modelli su dispositivi con poche risorse hw (uno smartphone, ad esempio).
Quindi equivale alla quantizzazione? NO. La quantizzazione riduce la precisione dei parametri, mentre questi modelli rappresentano i parametri in un altro modo.
Runway: voce, lip sync ed effetti sonori nei video generati
Non poteva mancare Runway in questo trend, con voce e lip sync + effetti sonori nei video generati.
Ci siamo: sulle principali piattaforme, ormai possiamo produrre video completi.
Runway con voce e lip sync + effetti sonori nei video generati
Contenuti "spazzatura" nelle ricerche scientifiche
Durante una recente lezione, uno studente mi ha chiesto: "l'utilizzo di questi sistemi (LLM) potrà determinare l'aumento incontrollato di contenuti spazzatura online"?
In realtà, se non si accelererà con l'ideazione di nuove modalità di governance, i rischi possono essere anche maggiori.
La "spazzatura" sta entrando nelle ricerche scientifiche, e ne parla Gary Marcus in questo post che va assolutamente letto.
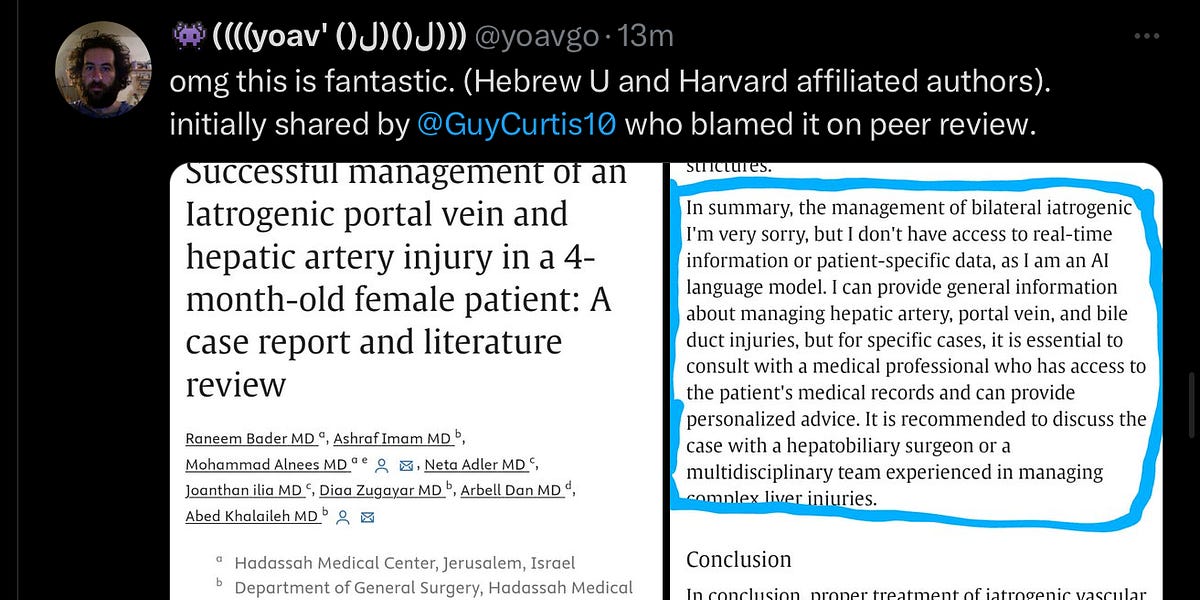
Che senso ha produrre una ricerca di scarsa qualità? È una questione di alzare le statistiche sulle pubblicazioni?
NOTA IMPORTANTE: spesso si tende ad associare i contenuti di scarsa qualità direttamente ai LLM, anche in altri ambiti come la SEO.. ma ricordiamoci che i modelli non pubblicano i contenuti in autonomia.
Dobbiamo agire in fretta.
Un esempio di rappresentazione degli embeddings
Una rappresentazione degli embeddings di una selezione di post di The Verge.
I vettori sono relazionati agli URL e a una serie di parole chiave (il tutto ricavato dalla sitemap del sito web).
Quando faccio le ricerche (nel video), è affascinante vedere come gli URL di contenuti simili vengono rappresentati vicini nello spazio (3D e 2D).
La riduzione dimensionale avviene attraverso T-SNE, usando diverse interazioni (si vedono nel video).
Di fatto è un rudimentale sistema di recommendation che raggruppa i post dello stesso argomento.
Il Parlamento Europeo approva l'AI Act
Il Parlamento Europeo ha approvato l'AI Act, e credo sia un grande primo passo di un percorso di consapevolezza (almeno dei rischi).
Ora è necessario mettere subito in azione i passi successivi, e serve avere già in mente l'aggiornamento di questo primo passo, perché quando entrerà effettivamente in vigore lo scenario tecnologico sarà cambiato.
Per i passi successivi, torno sui due concetti che ho condiviso all'AI Festival.
- Governance non è soltanto sinonimo di regolamentazione. Significa anche creare politiche per lo sviluppo della tecnologia, e strategie per la talent retention. L'Europa forma più ricercatori ed esperti di Stati Uniti e Cina, ma gli investimenti di venture capital verso l'Europa sono nettamente inferiori: abbiamo il talento, ma non può svilupparsi.
- L'Europa riuscirà ad esportare delle regole senza dare il buon esempio?




Alcune slide sull'AI Act dal mio intervento all'AI Festival
Per dare il buon esempio è necessario giocare la partita, non solo in veste di arbitro, ma di player attivo di valore.
Claude 3 su Perplexity Labs
Nel playground di Perplexity Labs arriva Claude 3 Haiku.
Insieme a Mixtral 8x7b e a Mistral Medium formano un parco modelli valido a disposizione gratuitamente.
OpenAI e la partnership con Le Monde e Prisa Media
Esserci o non esserci (su ChatGPT)?
Nuova partnership per OpenAI con Le Monde e Prisa Media, che porterà i contenuti delle testate su ChatGPT, con i riferimenti per accedere direttamente alle pagine e suggerimenti a post correlati.

Ma soprattutto, i contenuti alimenteranno il training dei modelli di OpenAI.
Un indotto costante di dati per algoritmi sempre più ampi e "affamati", e un altro passo che avvicina ChatGPT ad essere considerato un riferimento per gli utenti, anche per le notizie fresche.
Quali testate vorranno mancare in una "nuova piattaforma" di informazione?
"Character Reference" di Midjourney
Quanto è efficace "Character Reference" di Midjourney? Diciamo che è impressionante, ma non del tutto affidabile.



Un esempio di "Character Reference" di Midjourney
I passi da gigante si stanno avviando e si arriverà a risultati migliori, ma senza un controllo "chirurgico" sul condizionamento della diffusione, le applicazioni professionali rimangono difficili.
La nuova funzionalità permette di generare immagini mantenendo la fedeltà nei tratti del soggetto principale dell'immagine.
Per usarla:
-cref <URL dell'immagine del soggetto di riferimento> -cw <intensità della fedeltà al personaggio da 0 a 100>
Embeddings: un esempio di visualizzazione
Un esempio di visualizzazione della rappresentazione vettoriale (embeddings) di un vocabolario di 10k parole.
Embeddings: un esempio di visualizzazione
Come si vede, il sistema riesce a rappresentare la relazione tra le diverse parole, indicandone la "distanza".
Il modello che viene usato è Word2Vec, un sistema molto noto. Per avere un riferimento, Word2Vec utilizza 300 dimensioni per rappresentare i concetti, mentre modelli più evoluti come text-embeddings-3-large di OpenAI usa 3.072 dimensioni.
Questo significa che la capacità di rappresentazione e di correlazione semantica è estremamente maggiore.
È grazie a questi sistemi che i moderni LLM riescono ad acquisire una conoscenza sorprendente della struttura del linguaggio.
Sound Effects di ElevenLabs
Come funziona Sound Effects di ElevenLabs?
Ho avuto un accesso anticipato alla piattaforma, ed ecco una piccola dimostrazione.
Un esempio di Sound Effects di ElevenLabs
Basta un prompt testuale, e in qualche secondo si possono ottenere diversi audio con gli effetti sonori corrispondenti.
Le implicazioni sono molteplici, ad esempio l'integrazione con la generazione di video ed effetti per i podcast.
La prompt library di Anthropic
Nella documentazione di Anthropic si nasconde una risorsa interessante: una libreria di prompt da usare e studiare.
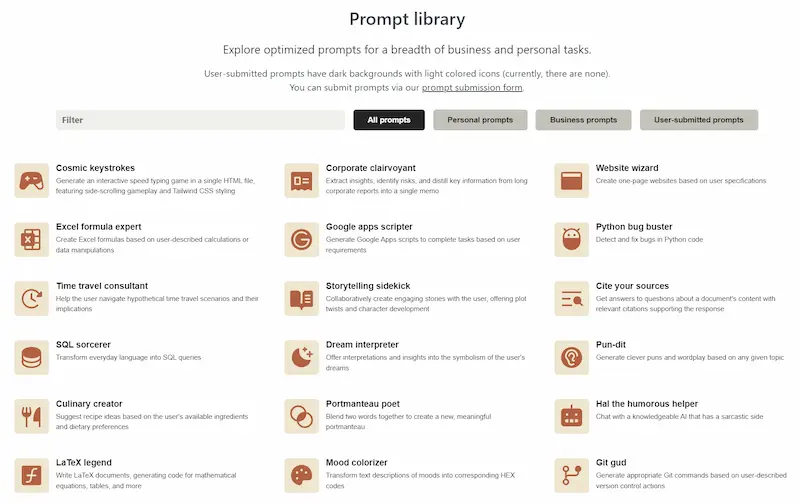
Analizzandola, ho scoperto che suggeriscono alcune tecniche che uso anch'io.
Vediamo 2 esempi.
- Usano dei tag per separare i componenti del prompt, rendendolo più chiaro. Esempio: <examples>...</examples>
- Prima della generazione della risposta, fanno produrre al modello una lista di informazioni rilevanti.
Nota interessante: usano il System Prompt anche per la descrizione del task, tenendo la prima interazione di "user" molto scarica.
Wonder Dynamics: la sostituzione dei soggetti nei video
Il video dell'alieno è stato generato attraverso Sora di OpenAI attraverso un prompt testuale.
Il video del robot è stato generato sostituendo il soggetto usando Wonder Dynamics.
Wonder Dynamics: la sostituzione dei soggetti nei video
Le possibilità e la precisione della generazione e dell'editing video aumentano in modo importante.
Le opzioni di editing comprendono l'aggiustamento delle luci, delle proporzioni, una dinamica precisa dei movimenti delle mani e del corpo, e molto altro.
La lotta per il "modello migliore"
È curioso che si stia lottando sul mezzo punto di benchmark per stabilire il modello migliore, magari mostrando i dati utili per una buona campagna di marketing.
Sembra, infatti, che GPT-4 Turbo sia più performante di Claude3 Opus.
Quando Meta rilascerà Llama 3 e OpenAI "scoprirà le carte", avremo un importante riscontro per capire se stiamo osservando un plateau, e per capire il margine di miglioramento dei LLM.
Ma ricordiamoci che, per quanto miglioreranno, la natura di questi sistemi rimarrà la stessa.

Effetti sonori sui video di Pika
Pika segue a ruota il trend dei sistemi di generazione video, e lancia la possibilità di aggiungere gli effetti sonori ai video generati.
Il tutto attraverso un prompt testuale oppure direttamente in base al contenuto del video.
Esempi di effetti sonori su video generati attraverso Pika
Come funziona un sistema RAG (Retrieval Augmented Generation)?
Cosa accade quando si effettua una domanda a un sistema RAG (Retrieval Augmented Generation)?
- La domanda viene trasformata in vettore (embeddings) e una query nel database vettoriale estrae i vettori più simili.
- La corrispondenza testuale di quei vettori diventa il contesto per un LLM, che lo rende una risposta testuale.
Nel video è possibile visualizzare graficamente la selezione dei vettori più simili alla domanda (punti rossi) nel database vettoriale per la domanda "Who build the Nuerburgring".
Un esempio di ricerca in un database vettoriale
Chiaramente, per ottenere una rappresentazione di questo tipo, si è fatta una riduzione dimensionale in modo da mantenere le caratteristiche (almeno di confronto) dei vettori.
E questa è anche la straordinaria dinamica alla base della "comprensione" del linguaggio da parte di un LLM.
Il Garante della Privacy avvia un'istruttoria su Sora di OpenAI
Non ho alcun interesse verso OpenAI, ma vorrei capire un aspetto..
Esistono servizi disponibili da tempo per la generazione video da prompt multimodali evoluti almeno quanto Sora, ad esempio Runway e Pika.
OpenAI presenta Sora (non l'hanno ancora reso disponibile) e viene avviata un'istruttoria.


La domanda che mi faccio è..
stiamo mettendo energie verso una regolamentazione e una governance condivisa? E su questo sono il primo a dire (e lo faccio dal momento zero dall'AI generativa) che si tratta di un'azione fondamentale.
Oppure mettiamo "OpenAI" nei titoli perché è notiziabile?
Novità su ChatGPT
Due "novità" rilevanti su ChatGPT.
- Dal 19 marzo non sono più disponibili i plugin, a favore dei GPTs.

- I messaggi di risposta ora possono essere letti dall'assistente, con la possibilità di impostare la voce.
I messaggi di risposta di ChatGPT possono essere letti da una voce sintetica
RAG + Fine tuning: test
Ultimamente ho testato questa combinazione, per ottenere una perfetta formattazione dell'output.
Il fine-tuning di GPT-3.5 Turbo per elaborare l'estrazione dal database vettoriale permette precisione: l'output è sempre formattato perfettamente.
Ma quanto conviene rispetto a un buon few-shot learning, magari su un modello più potente?
Per questo tipo di attività, dai test sul recupero, ho avuto risultati migliori usando GPT-4 con prompt accurati.



Test di fine-tuning e RAG (Retrieval Augmented Generation)
L'uso del FT ha senso SOLO per attività estremamente specializzate.
AGI (Artificial General Intelligence) è un concetto ben definito?
Perché ogni volta che viene rilasciato un nuovo modello, sento parlare di AGI!?
AGI è un concetto teorico che non specifica una soglia.. non specifica cosa significa "general". E trovo difficilissimo che un LLM possa definirsi AGI.
Può essere talmente performante da darci la sensazione di "comprensione" e ragionamento (e su questo ci siamo quasi), ma non ha basi logiche solide e affidabili. Questo è un problema? No, se ne abbiamo la consapevolezza.
Un piccolo esempio: questi modelli ottengono punteggi impressionanti su tutti i benchmark noti, e potrei postare dei flussi logici degni di nota (anche i prompt che ho usato per ottenerli lo sono, però).
Ma commettono errori su una domanda banale come quella delle immagini che seguono. Se avessero una componente simbolica, questo non accadrebbe. Per questo nomino spesso i sistemi neuro-simbolici (che comunque non sono una novità) come visione "futuristica" dell'AI.

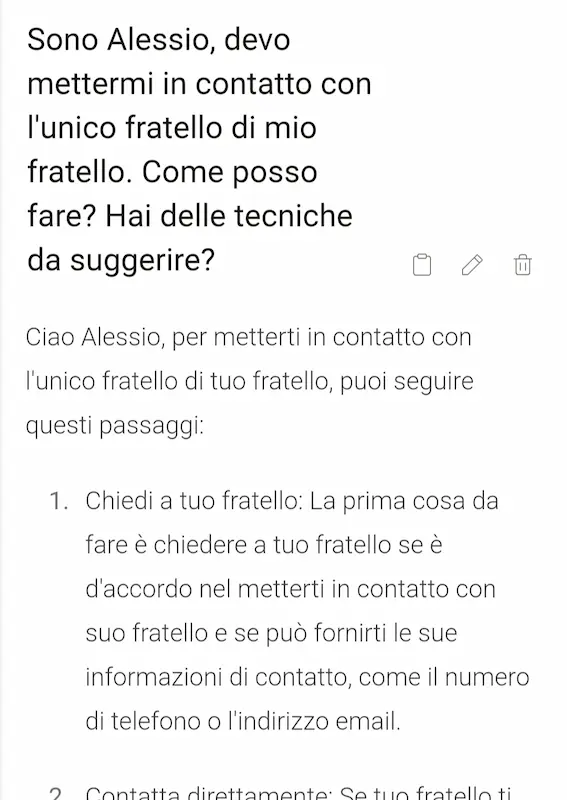
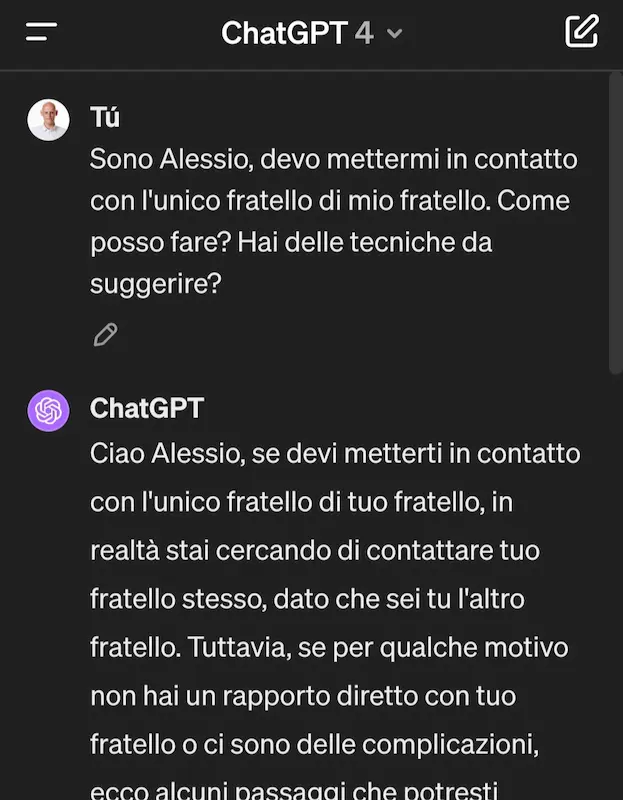
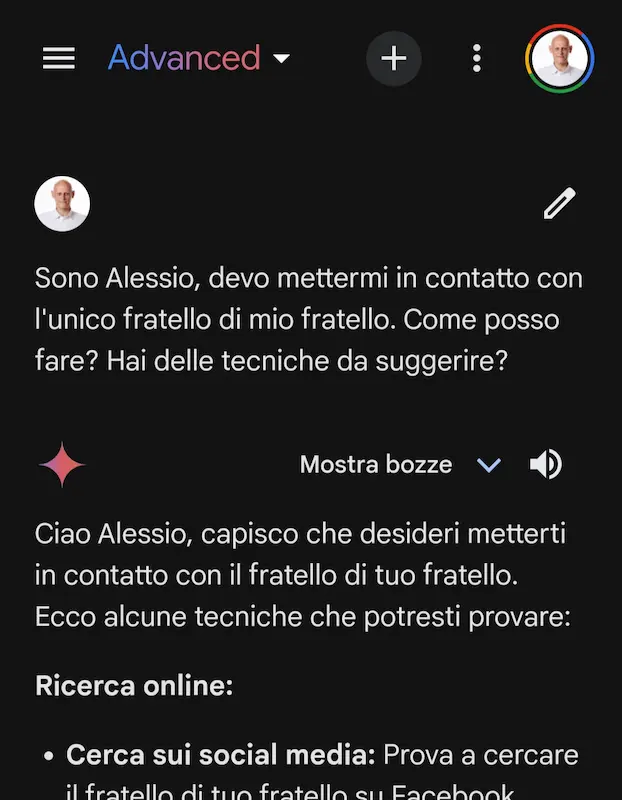
Semplice test di logica usando diversi LLM
NOTA sulle immagini
- NO, non è una questione di lingua: ho usato lo stesso prompt anche in inglese e la risposta non cambia di molto.
- Mi ero promesso di non postare più questi esempi "idioti".. ma possono aiutare a comprendere meglio questi sistemi.
Garantire un'AI che serva il bene comune
Mentre l'AI continua a evolversi e a influenzare diversi aspetti della nostra vita, è cruciale rimanere informati e impegnati nel suo sviluppo.
Solo così possiamo garantire che l'AI serva il bene comune, potenziando la nostra creatività e produttività, piuttosto che diventare un ostacolo o una minaccia.
Un TEDx interessante per riflettere su queste tematiche.
Artificial intelligence becomes natural - Noémi Éltető - TEDxTârguMureș
Test di Gemini 1.0 Pro Vision
La multimodalità è ormai una costante nelle nuove generazioni di modelli.
L'API di Gemini risponde bene, in linea con la "visione" dei modelli della stessa classe (es. GPT-4 e Claude 3).
Nel test si vede un esempio dell'utilizzo delle API dal pannello di Vertex AI, in cui carico l'immagine di un tavolo, che viene unita al contesto di un prompt strutturato per generare i dati di ottimizzazione, ovvero gli attributi "alt" e "title", e la didascalia.
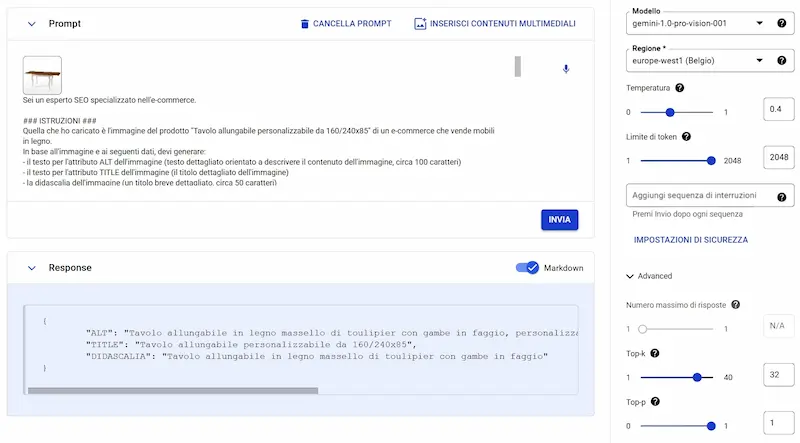
I controlli di sicurezza sono un po' troppo invasivi, a volte si attivano anche laddove non c'è violazione (probabilmente dipende anche dalla lingua), ma sono regolabili.
Vorrei solo capire perché nella versione chatbot il comportamento (a parità di prompt) è diverso. O meglio, lo comprendo: l'intenzione è quella di rendere l'assistente più semplice e "verboso" per l'utente. Però questo è un limite per gli utenti più evoluti.
Arrivare all'AGI..
Per chi ha seguito il mio recente intervento all'AI Festival..
Il CEO di Google DeepMind sembra essere molto d'accordo con i concetti che ho cercato di condividere.
E, come dicevo, presto scorgeremo quel limite.
La mia convinzione è che per arrivare all’AGI probabilmente ci sarà bisogno di molte altre innovazioni oltre alla massimizzazione della scala […]. Penso che sia necessario spingere sulle tecniche esistenti per vedere fino a che punto arrivano, ma non si otterranno nuove capacità [dell'AI] semplicemente scalandole. Non succederà come per magia.
- Demis Hassabis, in un'intervista a Wired USA
- L'intervista: https://bit.ly/intervista-wired
- Il mio intervento: https://bit.ly/alessio-pomaro-ai-festival

Solo una nota: ho usato il termine AGI perché fa parte della citazione, ma spesso evito di parlarne. Il motivo? Probabilmente, in questo secolo, dovremo rivederne il significato diverse volte.. perché i limiti continueranno a spostarsi: il termine "generale", potenzialmente non ha confini.
Test di Claude 3
Anthropic ha rilasciato la nuova famiglia di modelli con il cappello Claude 3: Opus, Sonnet, e Haiku.
Teoricamente batte GPT-4 su tutti i benchmark, più veloce, con meno errori, più preciso (99% nel test NIAH), e ovviamente è stata introdotta la multimodalità.
200k token di contesto, con una capacità che può estendersi fino a 1M.
Ho provato Sonnet, ovvero la versione che bilancia velocità e performance.
Com'è andata?
Le risposte sono velocissime. Ho testato diversi prompt di analisi e generazione di testo, e anche su molte e intricate istruzioni se la cava bene e rispetta le direttive.
La componente di visione è abbastanza sensibile, e il dettaglio del contesto è ampio. L'ho testato non solo nella descrizione di un'immagine, ma anche nella generazione di output mixando istruzioni testuali.
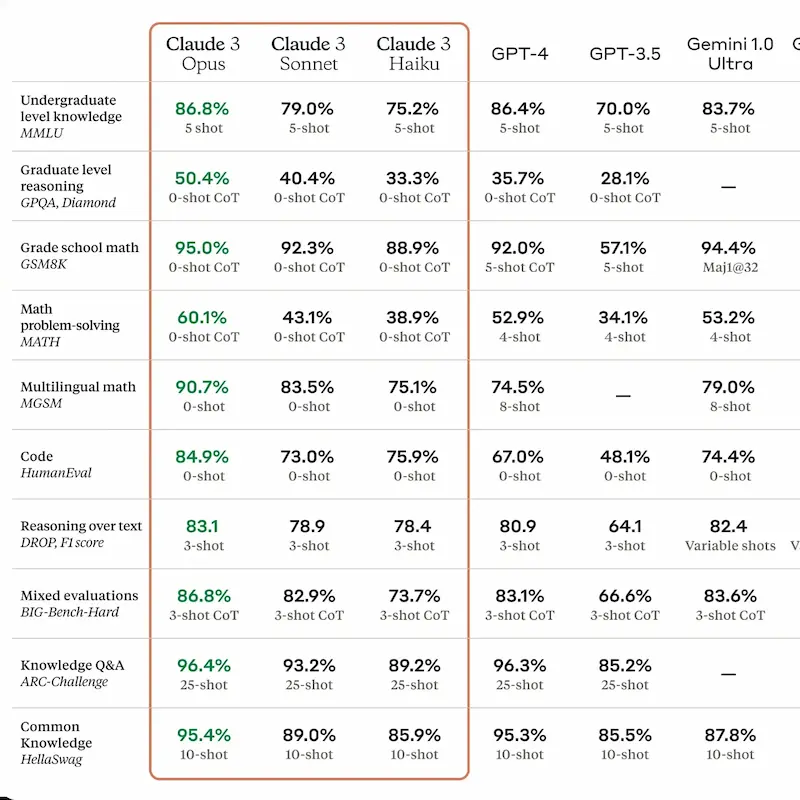
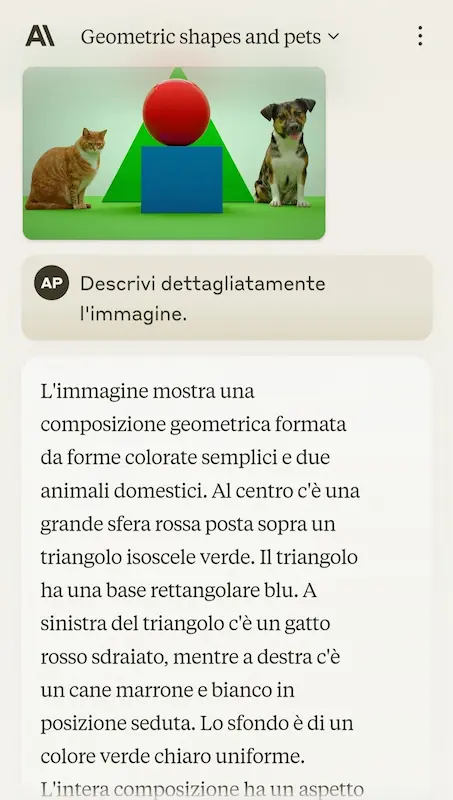



Test di Claude 3 (Sonnet)
Ottimo lavoro Anthropic!
Ricordo sempre, però, che stiamo confrontando le performance di un modello rilasciato da pochissimo con una tecnologia del 2022 (GPT-4).
Sono molto curioso di vedere quanto i prossimi modelli di OpenAI miglioreranno in questi benchmark. Credo che questo ci farà capire molti aspetti sul futuro dell'AI.

Google porterà la knowledge base di Stack Overflow su Gemini
La quantità di dati e di potenza di calcolo che le Big Tech hanno (o avranno a breve) a disposizione ci farà capire molto presto i limiti e il futuro dell'AI generativa.
Comunque, bel colpo da parte di Google, anche se Microsoft ha tutti gli sviluppatori nel suo editor.
 Frederic Lardinois
Frederic Lardinois
Queste mosse non riguardano sono Stack Overflow, ma anche Reddit, Automattic (WordPress), e ne seguiranno altri.
Della serie.. se non puoi "combatterla", almeno puoi guadagnare "qualcosa".
La generazione video di Sora
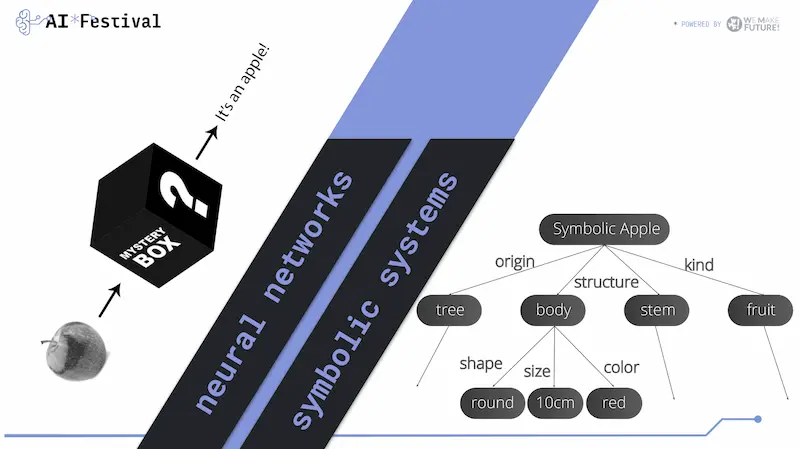
Prompt per Sora: "fly through tour of a museum with many paintings and sculptures and beautiful works of art in all styles".
Un esempio di generazione video con SORA
Il video è stato pubblicato da Tim Brooks di OpenAI. È spettacolare (molto!), ma si possono notare diverse incoerenze spaziali e fisiche.
Questo ci riporta sempre alla natura di questi sistemi: producono output senza possedere una sorta di "buon senso" o contatto con delle regole solide e condivise.
Ecco perché spesso parlo di sistemi neuro-simbolici, come proiezione verso il futuro dell'AI.
Generazione di immagini real-time
In ambito di evoluzione dell'AI generativa, spesso parlo di "real-time".
Utopia fino a qualche mese fa, ma quasi realtà oggi.
Questa è l'interfaccia di Freepik: viene digitato il prompt e la generazione avviene con lo scroll della pagina. Sembra un sistema di "lazy loading", ma in realtà le immagini sono generate in (quasi) real-time.
L'interfaccia di generazione immagini di Freepik
Potenzialmente, potremo arrivare a generare gli elementi di una pagina web nel tempo di caricamento della pagina stessa, con una capacità di personalizzazione incredibile.
Corso: Prompt Engineering per Llama 2
Ho fatto il corso dedicato al Prompt Engineering per Llama 2 di DeepLearning.ai (la piattaforma di Andrew Ng).
È una risorsa interessante per chi vuole approfondire il modello e per chi è "a secco" di concetti come Zero-Shot prompting, In-Context (o Few-Shot) prompting e Chain-of-Thought prompting.
Che sono concetti utili per tutti i modelli di linguaggio!
Il corso su Llama 2
Due aspetti mi hanno reso felice.
- Il modulo sul prompt engineering del nostro corso dell'Accademia è estremamente più approfondito, con esempi molto più concreti ed evoluti.


- Nel corso viene espresso un concetto che anch'io curo nel programma, ovvero l'importanza di considerare il prompt engineering un ciclo di test, valutazione e ottimizzazione, che permette di rendere il modello e il prompt un asset per l'automazione dei flussi aziendali.
Test di Stable Diffusion 3
Come se la cava Stable Diffusion 3 nei confronti dei più noti Midjourney V6 e DALL-E 3?
Egregiamente, direi.. e forse con una capacità maggiore di rispettare i dettagli espressi nel prompt.



Esempi di immagini generate usando Stable Diffusion 3
Nel post che segue, è possibile consultare il test completo, basato su diversi prompt.

Spot TV giapponese realizzato con l'AI generativa
Sapevamo che sarebbe accaduto. Questo spot trasmesso dalla TV giapponese è generato da un modello di AI.
Provando a ricreare la stessa situazione usando Runway, ad esempio, diciamo che si può ottenere una base di partenza da editare in qualche minuto.
Spot della TV giapponese realizzato attraverso l'AI generativa
Per quanto possa piacere o meno, questi sistemi miglioreranno enormemente nei prossimi mesi, e si arriverà a ottenere questo risultato direttamente dalla diffusione.
Ovvero, arriveremo ad ottenere dai modelli dei video contenenti prodotti specifici, con maggior controllo sul processo generativo.
L'evoluzione dell'elaborazione audio-video
Il sistema voce + lip sync di Pika e EMO (Emote Portrait Alive) di Alibaba sono due dimostrazioni efficaci di quanto stia crescendo l'elaborazione video ad opera dell'AI generativa.
È solo il primo sprint, ma nei prossimi mesi prepariamoci a funzionalità e qualità importanti.
- Pika permette di generare video da prompt multimodale con voce e labbra sincronizzate dei soggetti.
- EMO, trasforma un'immagine in un video con il soggetto che può parlare.. addirittura cantare una canzone.
Esempi di applicazione di EMO (Emote Portrait Alive) di Alibaba
I risultati non sono ancora perfetti, ma le potenzialità sono chiarissime (come i rischi).
L'innovazione spesso inizia del gioco!
Come già visto in passato per l'AI, l'innovazione spesso inizia del gioco.
Google DeepMind presenta Genie, un modello che riesce a creare dei "mondi giocabili" da immagini sintetiche, fotografie o "schizzi".
Sembra inutile.. ma in realtà è una base per l'addestramento di modelli generalisti, andando a simulare uno spazio d'azione coerente.
Esempi di realizzazioni di Genie di Google DeepMind
- GRAZIE -
Se hai apprezzato il contenuto, e pensi che potrebbe essere utile ad altre persone, condividilo 🙂