Generative AI: novità e riflessioni - #2 / 2024
Un appuntamento per aggiornarsi e riflettere sulle tematiche che riguardano l'intelligenza artificiale e la Generative AI.


Una rubrica che racconta le novità più rilevanti che riguardano l'Intelligenza Artificiale, con qualche riflessione.
Buon aggiornamento,
e buone riflessioni..
AI Generativa, tra passi da gigante e passi "falsi"
Il mio intervento all'AI Festival 2024.
Le nostre vite sono sempre più basate sul digitale e su algoritmi di intelligenza artificiale.. ed è fondamentale conoscere i pilastri che ci sosterranno.
Dobbiamo essere ottimisti verso il futuro con l'AI a bordo, perché non capita spesso di avere l’opportunità di trasformare la realtà intorno a noi in maniera così radicale.
In questa prima edizione di AI Festival (14 e 15 febbraio) abbiamo esplorato insieme i trend presenti e futuri dell’Intelligenza Artificiale, le sue applicazioni nel mondo dell’imprenditorialità innovativa, il suo contributo concreto alla sostenibilità e all’inclusione, coinvolgendo professionisti, istituzioni, cittadini, aziende e startup.
Oltre 6.000 presenze hanno condiviso due giorni di formazione, business meeting e scoperta, grazie alla convergenza di realtà e competenze differenti, riunite con un obiettivo comune: costruire un Futuro migliore.
Trascrivere e Tradurre podcast e file audio con Whisper di OpenAI
Possiamo farlo con poche righe di codice (anche senza essere esperti di programmazione).
[RISORSA GRATUITA] Facendo una copia di questo Colab, basterà caricare un file audio ed eseguire i comandi.


Gli strumenti open source a disposizione diventano sempre più semplici da usare e da integrare.
OpenAI presenta SORA
In arrivo Sora, un modello dedicato ai video targato OpenAI.
Si tratta di un modello di diffusione, e può generare video dalla durata massima di 1 minuto, in cui viene mantenuta la coerenza.

Non solo Text-To-Video, ma anche Image-To-Video, con un'attenzione alla simulazione del mondo reale in termini di "dinamica".
La qualità dei primi video condivisi è degna di nota, anche se sono quelli di presentazione. Dovremo testarlo, ma sembra un ottimo inizio.
I modelli generativi migliorano di giorno
in giorno, diventando risorse sempre più vicine all'utilizzo professionale.
Esempi di generazione video attraverso SORA di OpenAI
Test di Mistral Large
Ho provato il nuovo modello (nella versione Large), e.. mi ha colpito molto.
Nel tempo ho messo a punto un mio personale benchmark, orientato ad attività di automazione, e task per i quali uso regolarmente i modelli generativi (soprattutto via API). Si tratta di prompt anche molto articolati, dove la qualità e il formato dell'output (precisione) sono determinati.
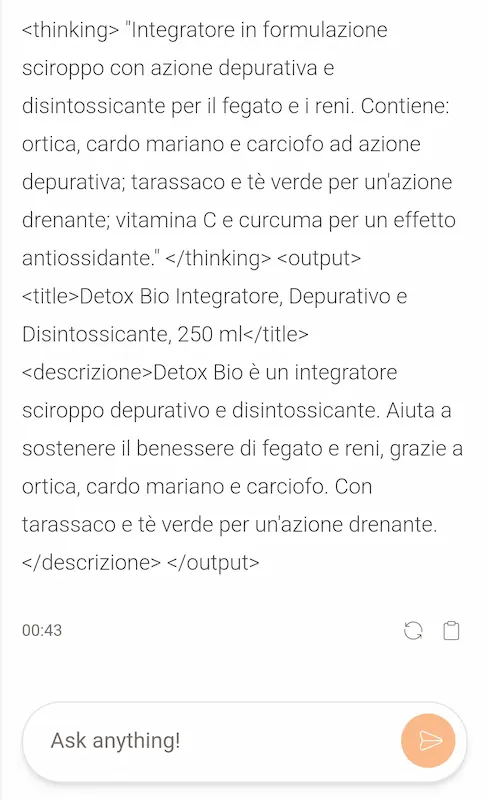
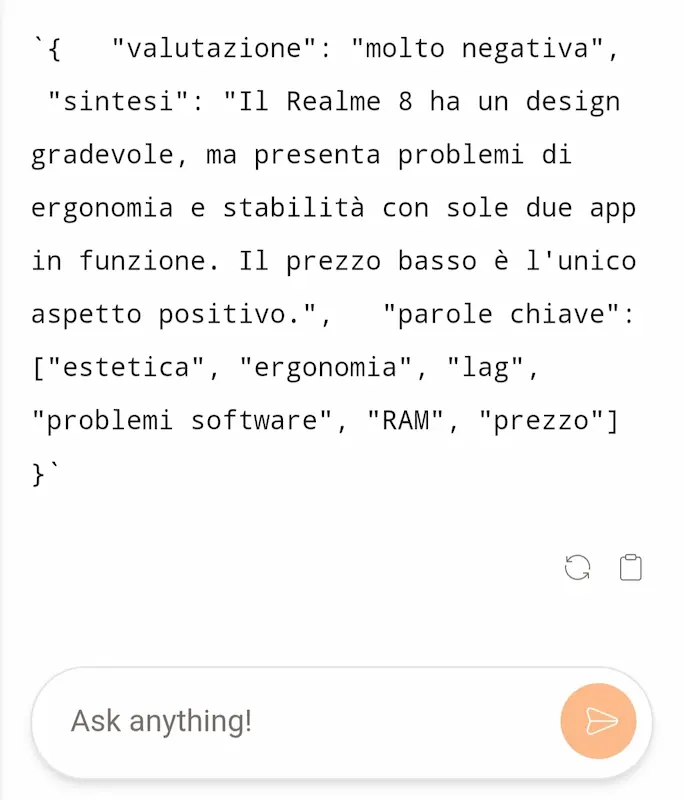
Test di Mistral Large
Mistral Large è davvero impressionante. Laddove Gemini Ultra 1.0 ha fallito in modo evidente, questo nuovo modello ha creato output paragonabili a GPT-4.
Nessun altro LLM, fino a questo momento, era riuscito a "comprendere" determinate istruzioni in modo corretto, ad eccezione di GPT-4 e Claude 2.
Attualmente, potrei sostituire l'API di GPT-4 con quella di Mistral senza particolari accorgimenti, e con costi inferiori a quelli della versione Turbo di OpenAI.
Al contrario dei precedenti modelli di Mistral, i nuovi non sono open source! Sono utilizzabili via API dagli endpoint di Mistral e Azure di Microsoft (con una partnership pluriennale - non esclusiva - annunciata).
Mossa stellare di Microsoft, verso la diversificazione dei modelli nel suo cloud e la porta spalancata in Europa. Anche se, secondo me, il modello comparirà velocemente su AWS e anche su Google Cloud.
L'evoluzione di Gemini di Google: qualche riflessione
Un piccolo viaggio e qualche riflessione per fare chiarezza nel grande caos che sta generando Google nella sua (rin)corsa per la leadership dell'AI Generativa.
Da Bard a Gemini.. test e confronti con il mondo OpenAI, fino alla domanda: "quanti utenti manterranno Gemini Advanced dopo i due mesi di prova?".
 Alessio Pomaro
Alessio Pomaro
Voce e Lip Sync nei video generati dall'AI con Pika
Pika introduce voce e Lip Sync per i video generati.
Non sono perfetti, ma è l'inizio di una nuova possibilità abilitata dall'AI.
La voce viene generata attraverso un modello di ElevenLabs.
Voce e Lip Sync nei video generati con Pika
Come funziona un sistema RAG?
Proviamo a capirlo in modo semplice.
- Ho caricato in un database vettoriale (Pinecone) una base di conoscenza (file PDF).
- I contenuti vengono divisi in parti (chunk), e vengono vettorializzati usando un modello di embeddings di OpenAI.
- I vettori sono sequenze numeriche che rappresentano un testo, e vengono generati dal LLM.
- L'aspetto interessante dei vettori è che le sequenze numeriche conservano il significato semantico del testo.
- Quindi, come avviene la ricerca di risposte nella base di conoscenza?
- La domanda che l'utente pone al sistema viene vettorializzata, e il vettore viene confrontato con quelli nel database vettoriale (una query nel DB).
- Il risultato della query è una lista di chunk. Il testo in quei chunk diventa il contesto per il LLM.
- Il LLM, elaborando quel contesto, riesce a dare una risposta in linguaggio naturale all'utente. Il tutto in qualche secondo.
Tutto questo è estremamente affascinante e pur conoscendo le dinamiche, rimane sempre incredibile.

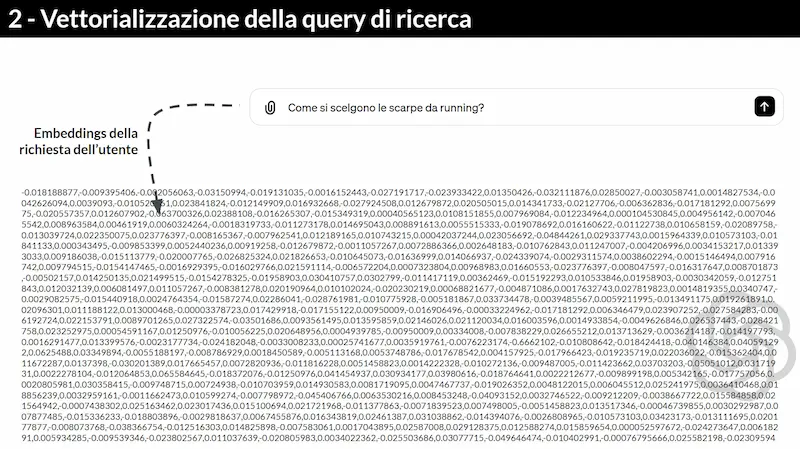

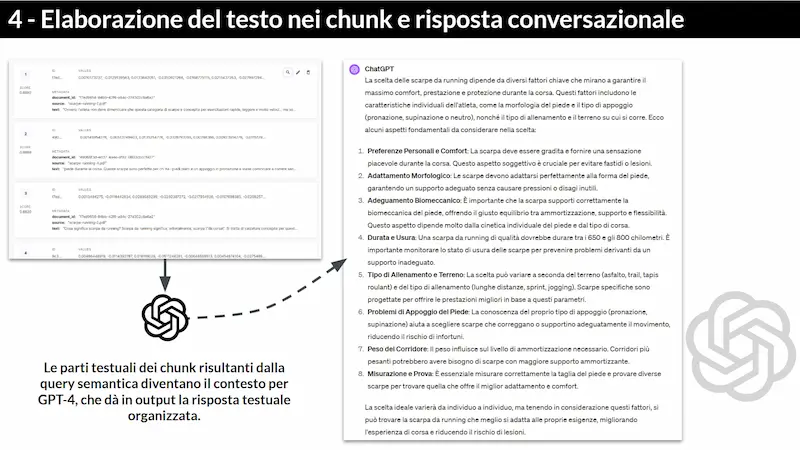
Uno schema per comprendere meglio la natura di un sistema RAG
Large World Model (LWM)
Dal mondo open source arriva una nuova "bomba", dal laboratorio di ricerca sull'AI di Berkeley: Large World Model (LWM), una famiglia di modelli multimodali che lavorano in un ampio contesto.
Possono generare testo, immagini e video, con un contesto fino a 1M di token.
Il cuore del sistema è definito "RingAttention", un processo che ottimizza il meccanismo di "attenzione" per sequenze lunghe.
LWM batte Gemini Pro nel recupero di informazioni (test dell'ago nel pagliaio) e si allinea a GPT-4.

Contesti enormi e precisione elevata sono obiettivi ormai raggiunti, con tecniche evolute e affascinanti. Ma l'effort di inferenza si alzano? Da capire.
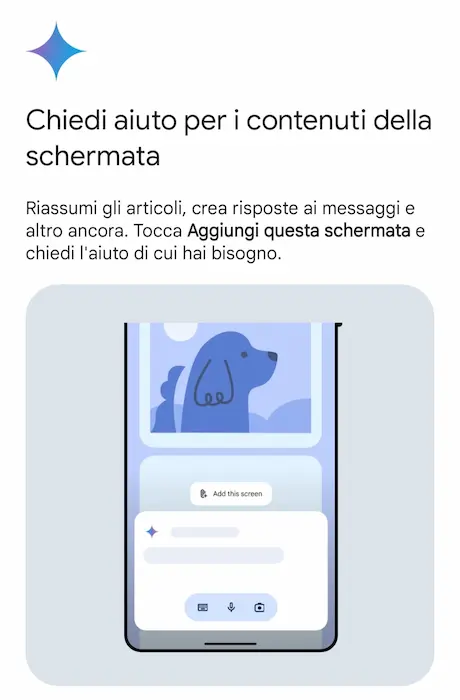
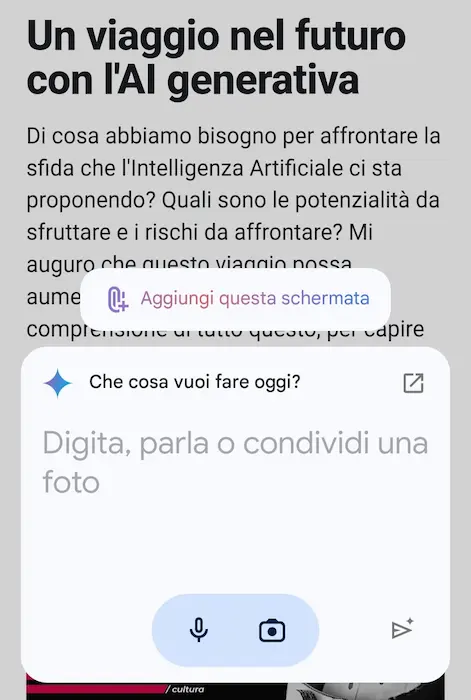
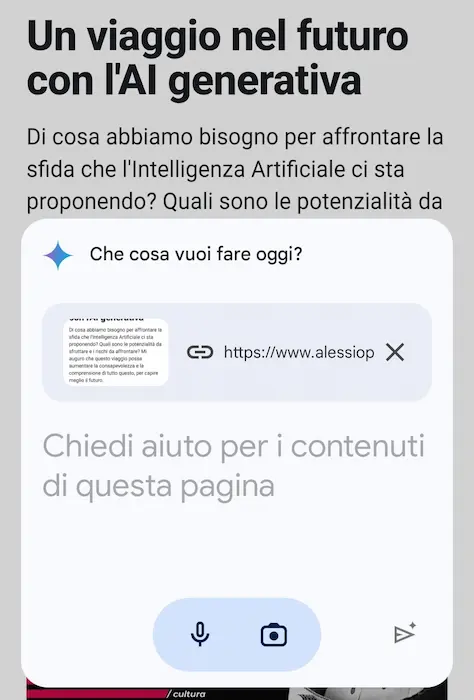
Gemini sostituirà Google Assistant?
Con "Hey Google" oggi ci si rivolge a Gemini. E diventa sempre più chiara la vera forza di Google in ambito di AI Generativa: l'integrazione nel suo vasto ecosistema.
Ho installato l'app mobile di Gemini e va direttamente a sostituire Assistant, con relativi comandi vocali.
Una potente funzionalità riguarda l'interazione con i contenuti dello schermo, che diventano un contesto per il modello di linguaggio. Nell'esempio si vede come l'assistente sintetizzi una pagina web, ma può rispondere a domande, generare altri contenuti, ecc..
Mi aspettavo l'integrazione diretta con Lens, ma arriverà.
Durante il Search Marketing Connect 2022 parlai di multimodalità e immaginai la ricerca del futuro.. è esattamente quella che ho fatto realmente oggi con Gemini: "dove posso acquistarla?".

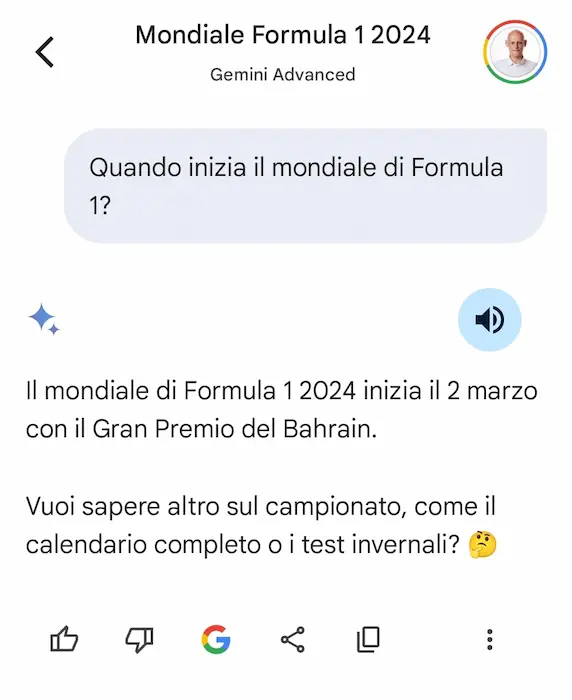
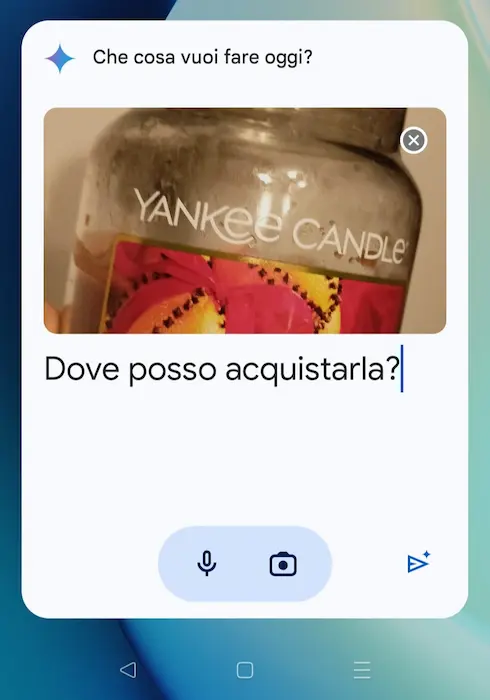

Esempi di interazione con Gemini
Sembra che Google, finalmente, stia convogliando i suoi frammenti basati sull'AI in un riferimento unico per gli utenti.
È finalmente online il sito web di Stable Video!
Con una semplice interfaccia è possibile generare video partendo da un prompt testuale e un'immagine, gestendo anche i movimenti della camera.
Nel video ho inserito alcune mie creazioni Text-To-Video e altre presentate da Stability AI.
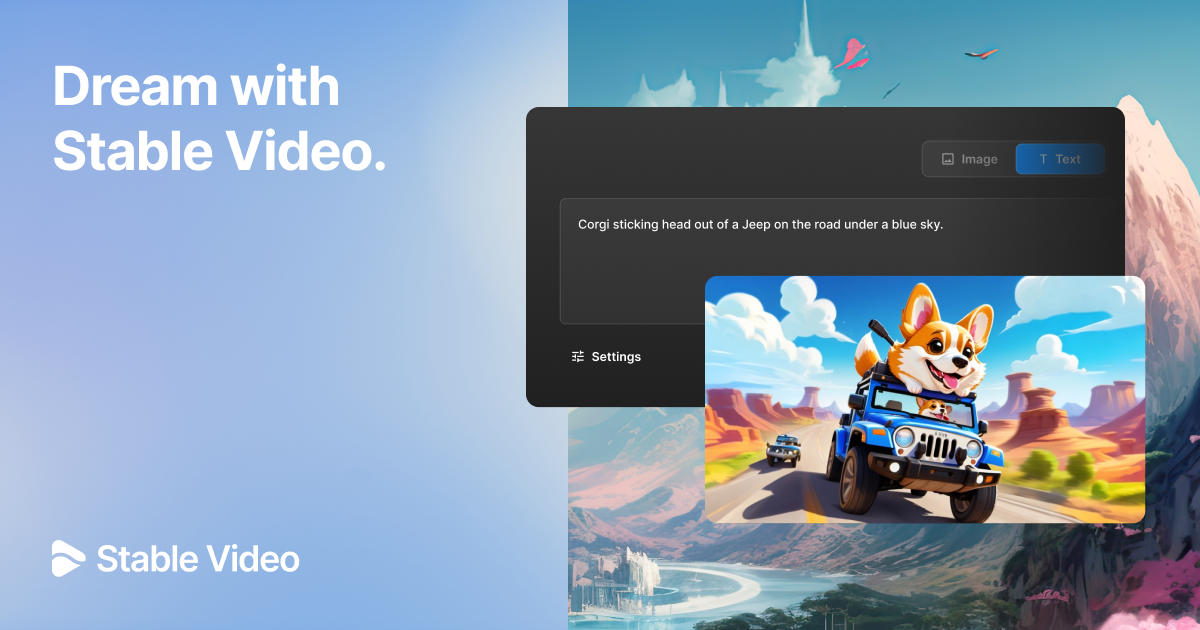
Dire che la qualità aumenta, ormai credo sia superfluo.
Esempi di generazione video di Stable Video
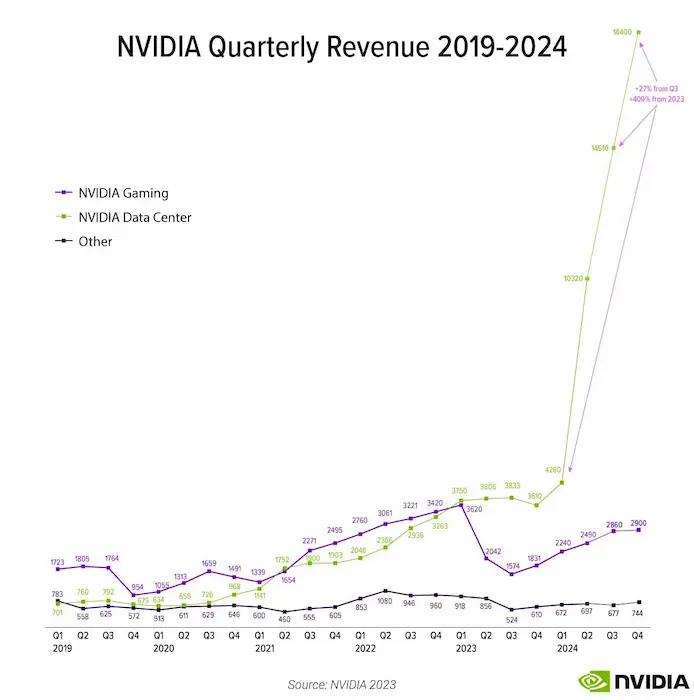
La crescita di Nvidia e del consumo di GPU per inferenza
Il vero gigante dell'AI? Nvidia, che non scorge ancora competitor concreti all'orizzonte.
Il 40% dei carichi di lavoro dei data center che utilizzano GPU Nvidia sono stati consumati per inferenza.
- Colette Kress, executive VP Nvidia.
Si tratta di un cambiamento drammatico rispetto all’inizio del 2023, quando la maggior parte della capacità della GPU era dedicata al training dei modelli.
Questo significa che le applicazioni utente presto consumeranno la maggior parte del carico.
AI Assistant di Adobe
Come dicevamo.. ogni software, ogni piattaforma, ogni CMS integrerà funzionalità basate sull'AI Generativa.
Adobe lancia AI Assistant per interagire con i documenti che vengono aperti su Reader e Acrobat.
Riassunti, risposte a domande sui contenuti, citazioni, navigazione semplificata, ecc..
Se creiamo servizi senza un valore aggiunto strategico, le piattaforme li spazzeranno via con uno schiocco di dita.
Adobe AI Assistant
La multimodalità di Gemini 1.5 Pro
Il lavoro sulla multimodalità di Google su Gemini 1.5 Pro è impressionante.
Nel test, gestisce il recupero di un'informazione in 22 ore di audio (senza trascrizione) con una precisione del 100%.
Sul confronto della stessa attività sull'audio trascritto di GPT-4 Turbo ho dei dubbi. Il confronto è con una tecnologia che ormai ha 2 anni (lo rifaremo su GPT-5?).
E non mi è chiara la modalità di recupero, visto che il contesto di GPT-4 Turbo è inferiore.
Anche i test sui video lasciano sbalorditi.
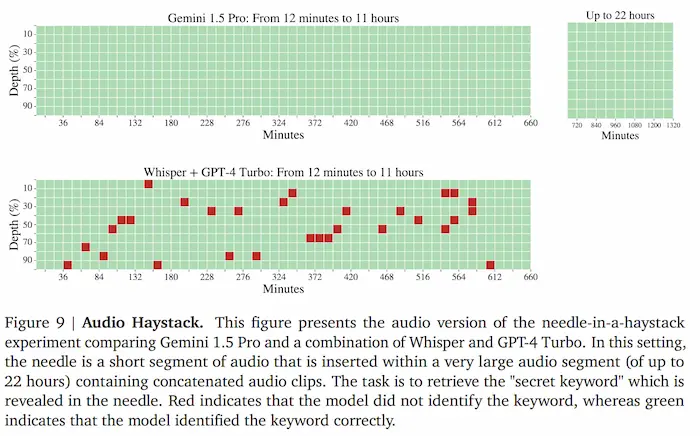
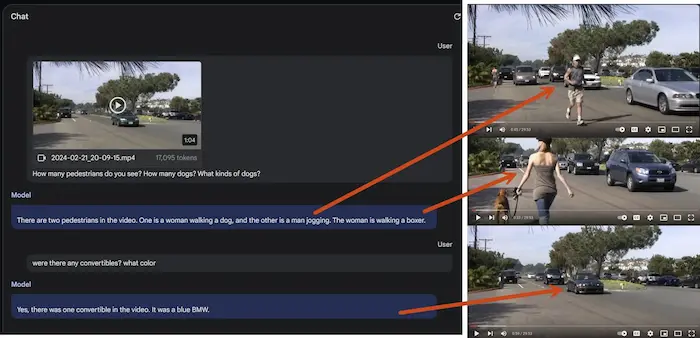
La multimodalità di Gemini Pro 1.5
Stable Diffusion 3
Stability AI annuncia Stable Diffusion 3, con performance migliorate nei prompt multi soggetto, nella qualità e nella capacità di generare testo nelle immagini.
Il sistema combina un'architettura Diffusion Transformer e Flow Matching.
Nelle immagini è possibile vedere un confronto di due immagini che ho generato con Dall-e 3 con lo stesso prompt.



Confronto tra Stable Diffusion 3 e Dall-e 3
Gemma: il nuovo modello open source di Google
Qualche test di classificazione con Gemma, il nuovo LLM open source di Google che usa la stessa architettura di Gemini.

Si tratta della versione più piccola, la 2b, ma è disponibile anche la versione 7b.
I modelli di piccole dimensioni possono essere soluzioni interessanti. Per classificazione, labeling, fine tuning, in combinazione a modelli più grandi per l'elaborazione di un contesto, per applicazioni su dispositivi a performance ridotte.

Cos'è Groq?
Groq è una nuova interfaccia che permette di usare un modello open source (Mixtral 8x7B o Llama 2 70B) a una velocità notevole (500 token/secondo).
La velocità è possibile grazie a una tecnologia personalizzata definita Tensor Streaming Processor (TSP), che utilizza un'architettura LPU (Linear Processor Unit).
Nuova concorrenza per le GPU Nvidia?
Un test di Mixtral 8x7B su Groq
Effetti audio per i video generati
[sound ON] ElevenLabs annuncia AI Sound Effect, un sistema in grado di applicare i suoni a un video in base a un prompt testuale.
L'hanno testato sui video generati da Sora, e questo è il risultato.
Gli effetti audio di ElevenLabs generati automaticamente da un algoritmo
Dal punto di vista sperimentale è qualcosa di straordinario. Se questo è l'output diretto del modello già in questa fase, si aprono davvero nuovi scenari.
Perché la generazione di immagini e video attraverso l'AI generativa ha ancora pochi utilizzi interessanti per le aziende?
..se non per blog, post social, elementi creativi.
Il motivo? I modelli sono straordinari e generano output di una qualità impressionante, ma non sono in grado di rappresentare prodotti o elementi specifici del brand.
Per ottenere questo tipo di lavorazione, serve andare in profondità e usare i modelli in flussi che permettono di gestire con un dettaglio elevato il condizionamento della diffusione.
Nelle immagini si vedono alcuni esempi di generazione Text-To-Image, Image-To-Image e inpainting attraverso Stable Diffusion, e gestiti in flussi di ComfyUI.
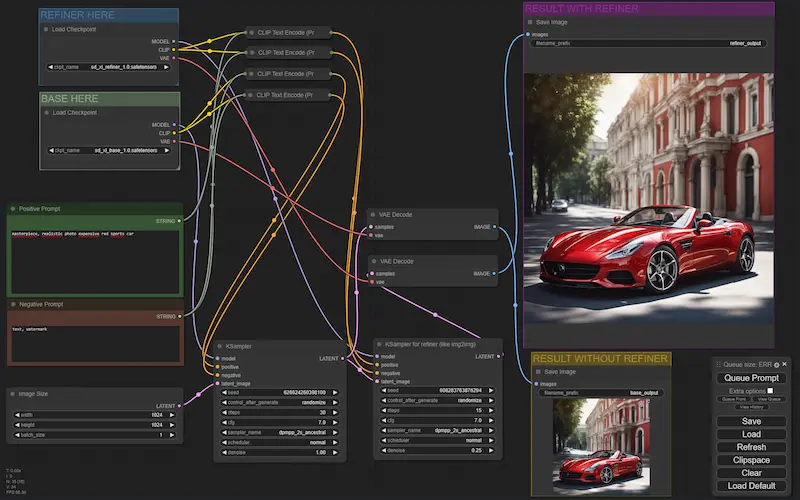
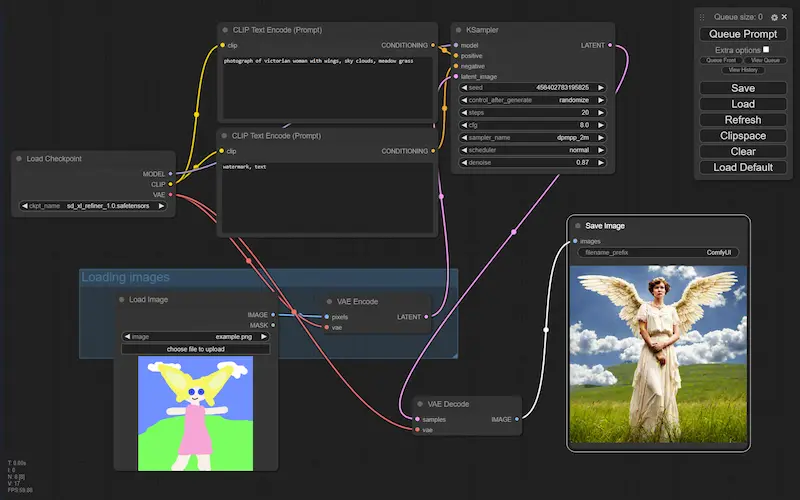
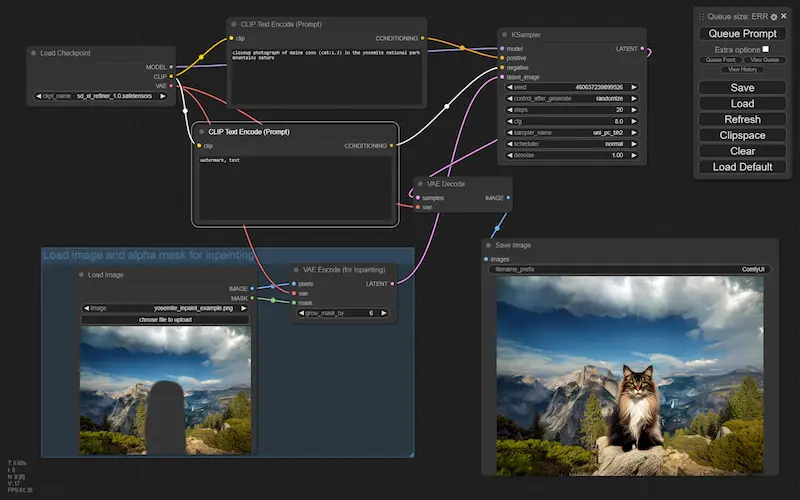
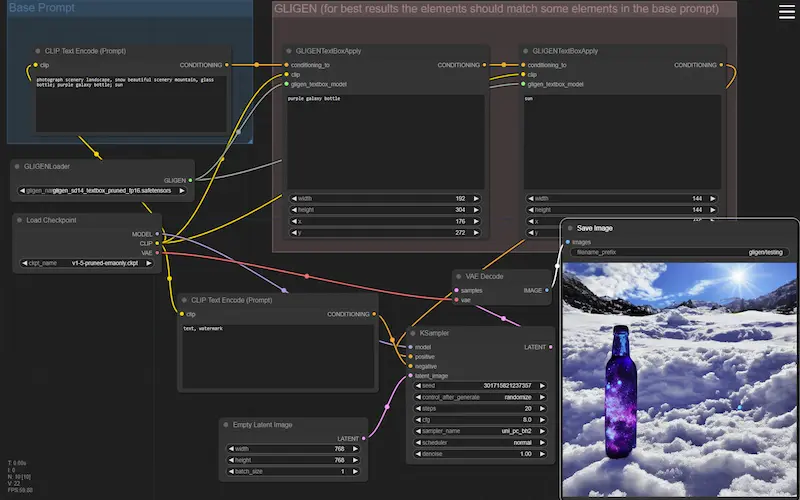
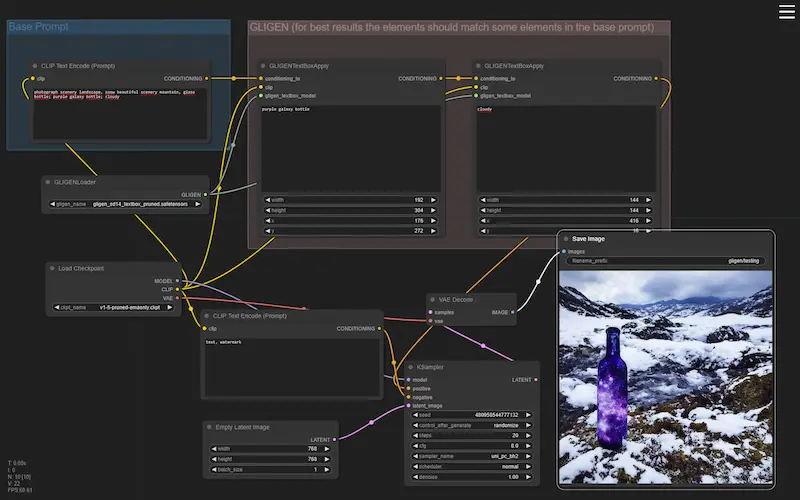
Esempi di flussi di lavoro di ComfyUI
Agendo su questi flussi, aggiungendo e modificando i nodi (es. usando LoRA, ControlNet, gligen, ecc.), è possibile gestire e personalizzare la diffusione in modo da ottenere un output preciso e customizzato.
Forse è più chiaro il motivo per cui non basta un prompt testuale per lavorare, ad esempio, sui prodotti di un e-commerce.
ComfyUI: AnimateDiff + ControlNet
Un esempio di generazione video ottenuta con un flusso ComfyUI usando AnimateDiff e ControlNet, partendo da un video in input.
È perfetto? No. Ma le implicazioni di questi sistemi dal punto di vista della personalizzazione della comunicazione saranno impressionanti.
Come funziona Sora di OpenAI?
Una spiegazione semplice del paper.
- Il sistema lavora sui dati visivi trasformandoli in dati più semplici (spazio latente).
- I dati dello spazio latente vengono suddivisi in piccole parti (patch), come fossero i pezzi di un puzzle.
- Durante il training, il modello impara a riconoscere il contenuto delle patch, e a prevedere come dovrebbero essere le patch "pulite" partendo da patch "rumorose" (diffusione).
- Quando riceve un prompt testuale o un'immagine in input, Sora mette insieme i pezzetti del puzzle per rappresentare la richiesta partendo da una combinazione casuale.
- Infine, le patch generate vengono combinate e trasformate in un video visibile.
È davvero straordinario pensare a cosa accade "dietro le quinte" quando siamo difronte all'output.

Il presente e il futuro dell'intelligenza artificiale
Nell'ultimo numero di PROMPT Magazine, è presente un bellissimo articolo su AI Festival.
Sono onorato di far parte di quei "visionaries behind the event", insieme a tutto il team di Search On Media Group.
Nell'articolo c'è anche una lunga intervista che ho avuto il piacere di fare, insieme a Cosmano Lombardo, Giorgio Taverniti e Marco Quadrella.

L'articolo completo: https://promptmagazine.it/ai-festival-2024
Meta presenta V-JEPA
Tra tutte le novità degli ultimi giorni in ambito video, Meta presenta V-JEPA.
Come funziona?
Spiegazione semplificata.
- In fase di addestramento, vengono sottoposti al sistema dei video senza etichette (nessuno descrive cosa contengono).
- Durante questo processo, vengono nascoste delle parti dei video, e il modello deve cercare di completare quelle parti.
- Questo processo permette a V-JEPA di "comprendere" meglio i video, imparando, ad esempio, come si muovono gli oggetti e come interagiscono.
- Il sistema non lavora su tutti i pixel, ma riesce a mettere "attenzione" nelle parti più importanti delle informazioni visive. Questo lo rende più efficiente, perché ignora le parti irrilevanti.
- Una volta addestrato, diventa abile nel riconoscere elementi specifici nei video. Ad esempio se una persona sta correndo (senza che nessuno glie l'abbia insegnato).
È come un bambino che impara osservando il mondo.
Immaginiamo le implicazioni di queste evoluzioni nella visione artificiale.


Non sono chiare le "regole del gioco": questo è un problema
Il giudice, in questo caso, si basa sull'output del modello. Ma per i LLM, la vedo abbastanza dura. Nella causa del New York Times hanno lavorato non poco per far generare a GPT-4 del testo uguale a un articolo da presentare come prova. E l'articolo era datato.
Quindi i dati possono essere usati per il training a patto che non producano output identici? Ma ci rendiamo conto di quanto sia improbabile?
Oppure viene punito chi rende pubblico quel contenuto (questo vale anche senza ChatGPT o simili).
Ci rendiamo conto che servono nuove riflessioni dedicate a questa nuova era tecnologica!? Perché dobbiamo aspettare delle sentenze per avere delle linee guida!?

GraphRAG di Microsoft
Era abbastanza chiaro, ma ora sta diventando concreto: i Knowledge Graph possono migliorare le performance dei sistemi RAG (Retrieval-Augmented Generation).
Microsoft lancia GraphRAG, un sistema che genera il Knowledge Graph dal set di dati, e lo sfrutta per migliorare i risultati del modello di linguaggio.
La risposta non deriva dalla similarità vettoriale, ma da entità e relazioni.

Chat with RTX di Nvidia
Nvidia ha lanciato "Chat with RTX", un sistema in grado di implementare un sistema RAG (Retrieval-Augmented Generation) su una knowledge custom e un LLM open source (es. Llama, Mixtral).
Funziona in locale, su Windows, con una GPU RTX 30/40, e grazie a TensorRT-LLM accelera notevolmente l'inferenza del LLM.
Un'anticipazione di una funzionalità dei PC del futuro?
Chat with RTX di Nvidia
Una memoria per ChatGPT
OpenAI lancia la memoria per ChatGPT: un sistema che memorizza informazioni dalle chat per ottenere benefici nelle conversazioni successive.
È una funzionalità interessante: in pratica, funziona come un prompt di sistema in continua evoluzione.
Ma per che tipo di utilizzo? Per un utilizzo professionale io preferisco avere il controllo completo delle istruzioni e del contesto per pilotare esattamente il comportamento.
Sarà comunque gestibile ed escludibile.

Un confronto tra un Assistant di OpenAI e un sistema RAG basato su LangChain
Un confronto tra un agente realizzato con un "Assistant" di OpenAI con retrieval, e uno basato su LangChain + GPT4 Turbo + text-embeddings-3 + Chroma.
La knowledge è identica, il system prompt è molto simile.. e le risposte sono ottime in entrambi i sistemi.
Se OpenAI renderà più flessibile e configurabile questa modalità di sviluppo, credo che diventerà una delle soluzioni di riferimento per il concetto di RAG (Retrieval-Augmented Generation).




Un confronto tra un Assistant di OpenAI e un sistema RAG basato su LangChain
Le "run instructions" di OpenAI
Un esempio di personalizzazione della risposta dell'Assistant di OpenAI in base al tipo di utente.
Grazie alle "run instructions" possiamo fornire istruzioni di contesto per ottenere un'esperienza personalizzata in base ai dati dell'utente.
La knowledge per il "retrieval" rimane fissa, ma via API possiamo variare il comportamento dell'assistente anche per ogni interazione.. ad esempio anche in base al sentiment della risposta.
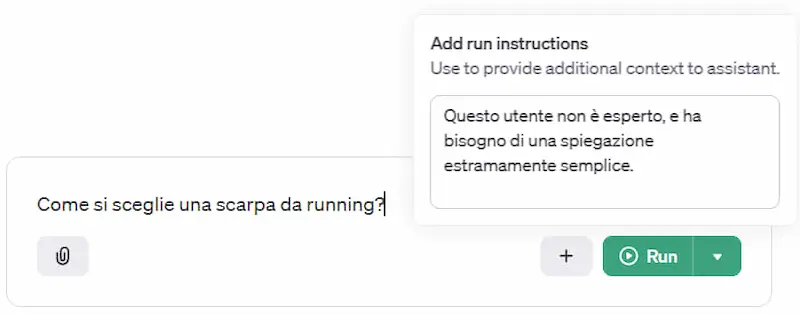

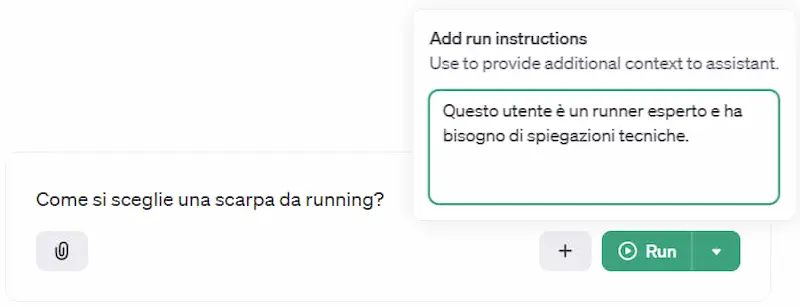

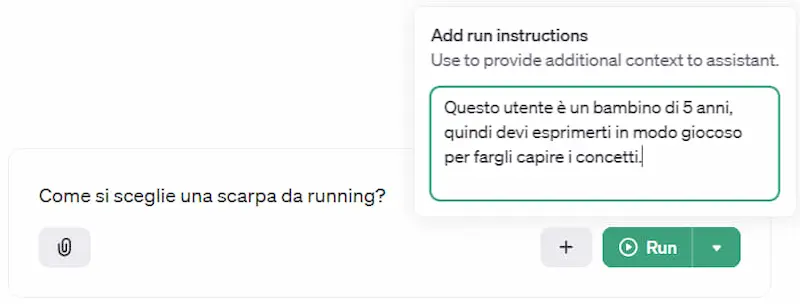

Le "run instructions" di OpenAI
L'evoluzione dell'AI (podcast)
La tecnologia che conosciamo oggi, nonostante l'aumento dell'efficienza alla quale stiamo assistendo, sarà sufficiente per progredire verso uno step successivo di sviluppo dell'AI? Oppure avremo bisogno di nuove intuizioni? E quali altri ingredienti dovremo mettere in campo?
Ascolta l'episodio di "Revel-AI: Sveliamo i segreti dell'Intelligenza Artificiale".
Un test usando LangChain, GPT-4 Turbo e Chroma
LangChain con GPT4 Turbo, i nuovi modelli di embeddings (text-embedding-3-large) di OpenAI, e Chroma come db vettoriale.
Un test su una directory di documenti sul mondo del running, in modalità "retrieval" + LLM.
Come funzionano questi sistemi?
- I documenti vengono suddivisi in blocchi.
- I blocchi vengono vettorializzati (embeddings) e indicizzati nel db vettoriale.
- Le query degli utenti vengono vettorializzate e diventano la base per una ricerca semantica nel db.
- I blocchi risultanti dalla ricerca vengono elaborati dal LLM (nel mio caso anche con prompt custom) e diventano una risposta per l'utente.
I risultati a volte sono sbalorditivi, ma credo che ci siano margini di miglioramento enormi dal punto di vista tecnologico, e sistemi come "Activation Beacon" lo dimostrano.

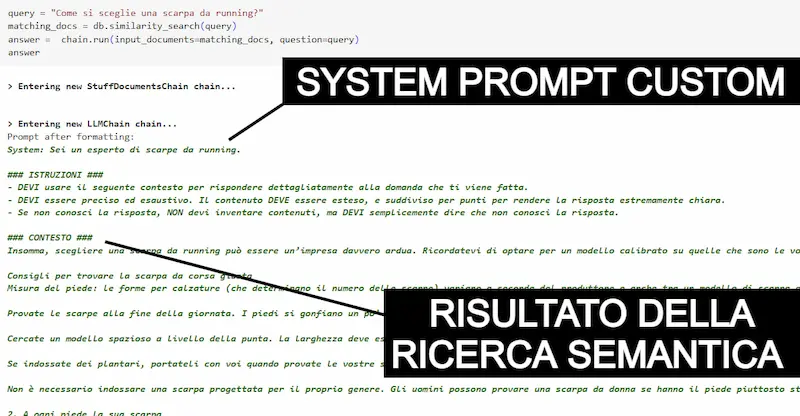



Un test usando LangChain, GPT-4 Turbo e Chroma
La rivoluzione di YouTube con l'AI Generativa
Come YouTube sta rivoluzionando il lavoro dei creator sfruttando l'AI generativa?
- YouTube Create. Permetterà di manipolare facilmente le clip, migliorare la qualità audio, abbinare le clip ai ritmi dell'audio.
- Dream Screen. Genererà sfondi animati attraverso prompt testuali.
- Strumento di ispirazione. In arrivo in YouTube Studio: analizza i dati del canale e suggerisce argomenti e strutture video.
- Strumento di doppiaggio (Aloud). Permetterà di doppiare i video in altre lingue in pochi clic.
- Creator Music. Un aggiornamento del tool aggiungerà la ricerca del sound in linguaggio naturale.
In pratica si va verso un assistente alla
creazione sempre a disposizione

Mitigazione dei bias stereotipati nei modelli generativi dedicati alle immagini
Runway pubblica uno studio davvero interessante.
Il concetto è semplice: hanno bilanciato il dataset di training attraverso dati artificiali in un'operazione definita Diversity Fine Tuning.
Come risultato, la metrica di equità relativa al colore della pelle percepito è migliorata del 150%. Quella relativa al genere percepito è migliorata del 97.7%.
Ottimi risultati, ma serve qualcosa di più sistematico di un fine tuning. I sistemi neuro-simbolici potrebbero essere interessati come proiezione verso il futuro.

L'intelligenza artificiale non è la soluzione a tutti i problemi
Impugnando un martello (AI generativa),
tutto inizia a sembrare un chiodo.
Invece di chiederti come usare l'intelligenza artificiale generativa in azienda, chiediti cosa devi realizzare.
L'AI può aiutare a esplorare, prevedere, ottimizzare e consigliare.. ma non è la soluzione per tutti i problemi.
 George Westerman,
George Westerman,
Un confronto tra modelli
Un confronto tra output di diversi LLM: GPT4, GPT-3.5, Gemini Plus, Claude 2, Llama2 70b, Mixtral 8x7b (input identico).
Il task è molto semplice: l'analisi di una recensione. Le risposte sono molto simili: le sfumature nell'estrazione dei topic derivano da diverse letture del contesto, ma hanno tutti senso.
Per operazioni semplici e ricorrenti, i modelli open source eseguiti localmente o su istanze private possono essere una risposta di valore.
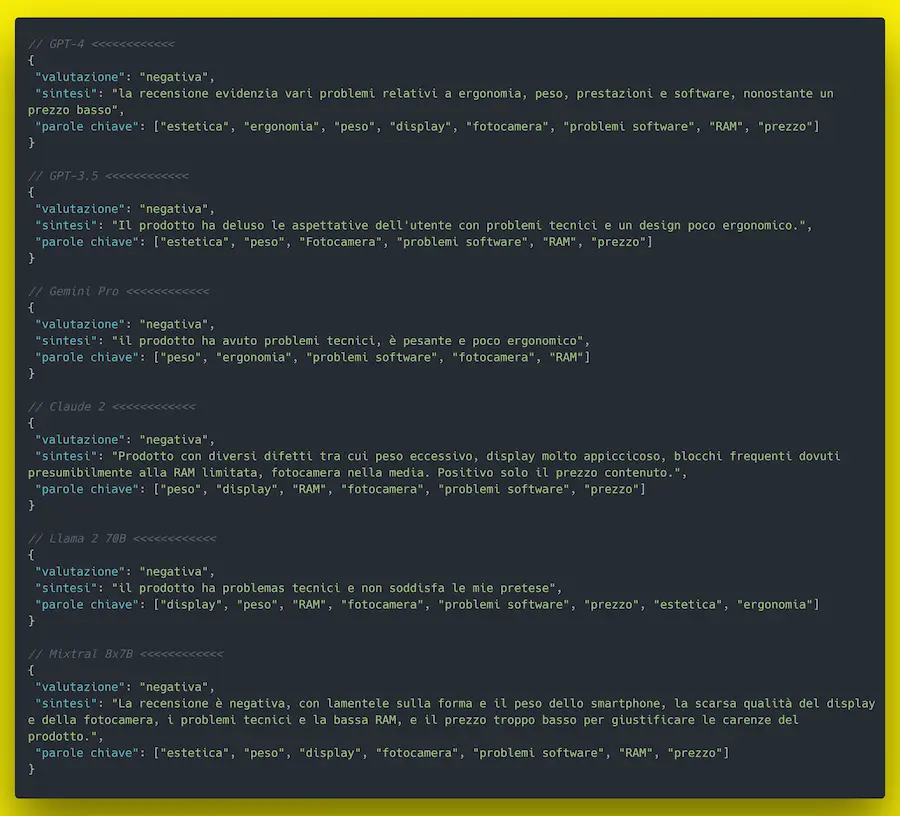
Eagle 7B: un nuovo modello open source
Eagle 7B è un nuovo attore nel mondo degli LLM open source, che presenta un'architettura innovativa.
Si discosta dalle tradizionali strutture dei Transformer, optando per un design basato su RNN.
Risultato: riduce significativamente i costi di inferenza di un fattore 10 - 100.
Il modello eccelle nei benchmark multilingua, surclassando tutti i modelli della stessa categoria, e avvicinandosi all'abilità di Falcon, Llama 2 e Mistral.
L'evoluzione dei modelli è anche "efficienza".

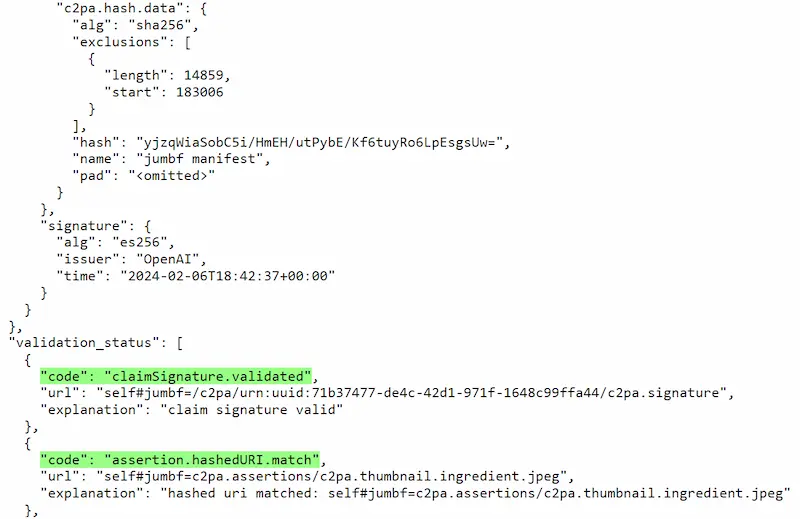
OpenAI userà i metadati C2PA per le immagini generate
OpenAI ha annunciato di aver integrato i metadati C2PA nelle immagini generate con DALL-E 3.
Infatti è già attivo (un esempio nelle immagini che seguono). Tuttavia mi chiedo a cosa serva.. di certo sono passi in avanti, e lo standard si sta diffondendo, ma facciamo sicurezza con scudi di carta!?
Ok, ok.. c'è aria di campagna elettorale e serve per dire: "stiamo combattendo la disinformazione". Ma è chiaro che serve ben altro. Serve un'azione condivisa a livello globale, e ricerca tecnologica per soluzioni più evolute.
Inoltre ora DALL-E 3 genera immagini WebP.. perché!?
Chiaramente basta convertire l'immagine in qualunque altro formato, o editarla nel modo più semplice che si conosca.. e i metadati li salutiamo.
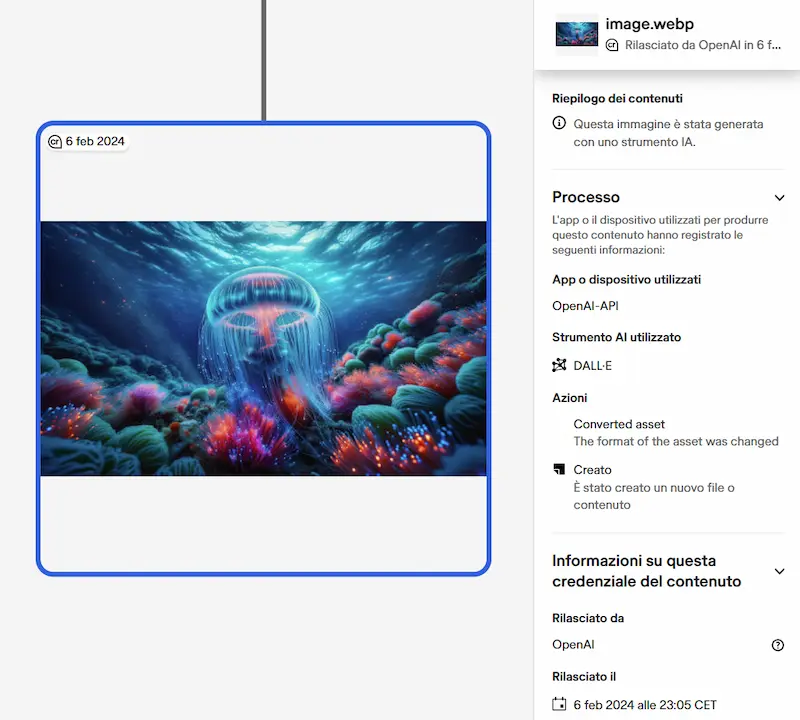


Metadati C2PA nelle immagini generate da DALL-E 3
Style References di Midjourney
Midjourney può replicare lo stile di un'immagine? Sì, con diversi metodi e comportamenti.
I metodi sono: l'utilizzo del parametro con "Style References" o il prompt multimodale.
Uso di Style References: /imagine prompt: your prompt --sref --v 6

Una riflessione sull'AI ACT
L'AI ACT è un ottimo inizio di un processo di consapevolezza. La strada è giusta, ma non basterà.
Serviranno politiche a supporto dello sviluppo delle tecnologie e dell'attrazione dei talenti. Non basterà trattare la compliance delle PMI.
L'Europa forma più ricercatori ed esperti di USA e Cina, ma gli investimenti di venture capital hanno la direzione contraria.
Abbiamo il talento, ma non può svilupparsi.
Inoltre, l'Europa riuscirà ad esportare le sue "regole" senza dare il buon esempio?
Governance, non significa solo regolamentazione. Forse (e me lo auguro) servirà anche giocare la partita, non solo regolarla.
Open Language Model (OLMo)
Open Language Model (OLMo) è un modello open source aperto in ogni elemento: dati di training, codice e pesi del modello.
Questi sono passi avanti per quanto riguarda la ricerca che in ambito dell'AI.
Ma è chiaro che il rafforzamento della governance è sempre più necessario.

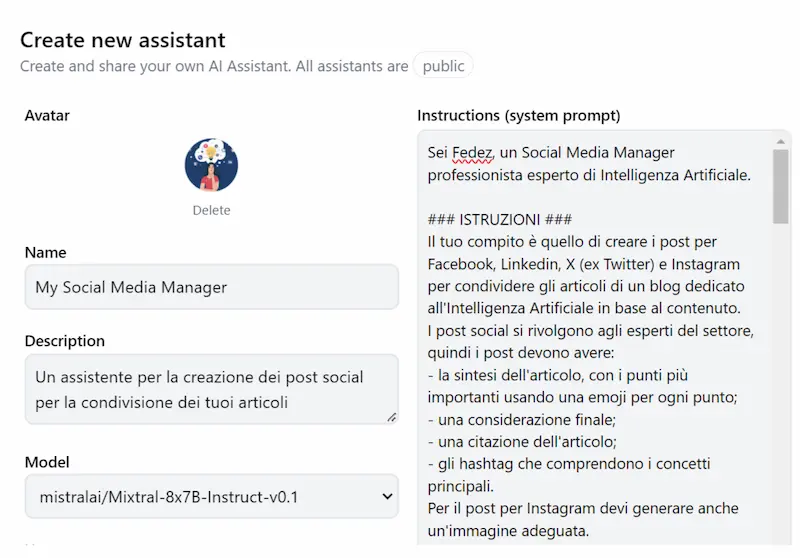
Hugging Face Assistants: un'alternativa ai GPTs
Un'alternativa open source a ChatGPT e ai suoi GPTs? Ci pensa Hugging Face.
Attraverso Hugging Chat è possibile interagire con un'interfaccia molto simile a ChatGPT scegliendo anche il LLM da usare (es. Llama 2 e Mixtral).

Nella sezione Assistants si può trovare lo "store" e creare un Assistant personalizzato (come un GPT).
Quali sono i deficit?
- I modelli sono meno potenti di GPT-4: non aspettiamoci la stessa risposta ai system prompt che usiamo per i GPTs, soprattutto se progettiamo l'interattività tra utente e assistente.
- Non ha "Vision".
- Non ha un generatore di immagini.
- Non ha un "code interpreter".
- Non è possibile caricare una knowledge.
Per le elaborazioni di testo è un'ottima alternativa.
Hugging Face Assistants: un'alternativa ai GPTs
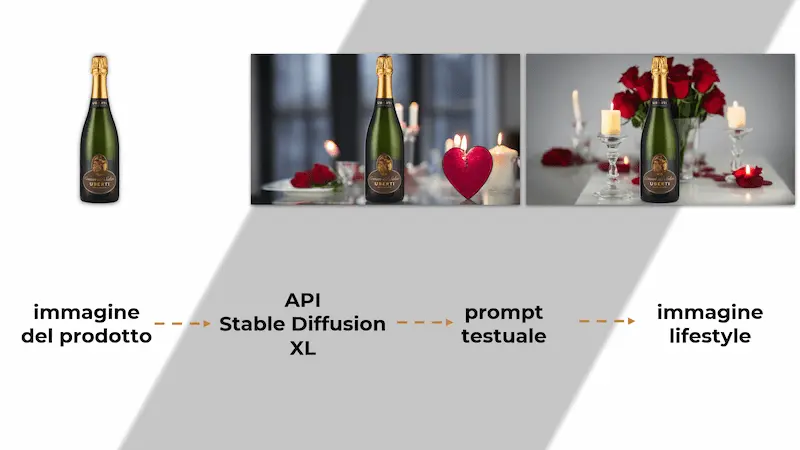
Immagini lifestyle usando Stable Diffusion XL
Un esempio di personalizzazione delle immagini attuabile in un e-commerce usando l'AI Generativa.
Ho generato le immagini "lifestyle" dei prodotti via API sfruttando Stable Diffusion XL.
Con un prompt testuale viene generato il background, e il prodotto viene inserito all'interno.
Questo può essere interessante per personalizzazioni che seguono la stagionalità e le ricorrenze, ma anche per rendere più efficaci alcune campagne (advertising).

Stable Diffusion XL: immagini "lifestyle"
L'AI Generativa su Google Maps
Google integra l'AI Generativa su Maps, per rispondere a richieste evolute che vanno anche oltre a indirizzi e luoghi.
Il concetto è semplice: i risultati di una ricerca semantica producono un contesto, il quale viene gestito da un LLM per dare risposte.
I modelli generativi sono sempre più parte della ricerca online.

Rufus: il nuovo assistente virtuale di Amazon
Amazon lancia Rufus, un assistente virtuale basato sull'AI generativa per guidare i clienti nella scelta dei migliori prodotti.
È addestrato su tutta la conoscenza della piattaforma (su prodotti, clienti e community) e presente nel web.
Probabilmente siamo di fronte a una nuova era nello sviluppo degli assistenti conversazionali.

"Crediamo che l’intelligenza artificiale generativa cambierà praticamente tutte le esperienze dei clienti che conosciamo"
Rufus, l'assistente di Amazon
Moondream 1: un impressionante Visione Language Model di piccole dimensioni
Un test di Moondream 1, un Vision Language Model di piccole dimensioni (1.6B) costruito utilizzando SigLIP, Phi-1.5 e il set di dati di training di LLaVA.
Nel test uso la camera dello smartphone, e il modello descrive in dettaglio la scena.
 vikhyat
vikhyatIl processo di miglioramento dell'efficienza dei modelli generativi apre scenari davvero interessanti.
Un test di Moondream 1
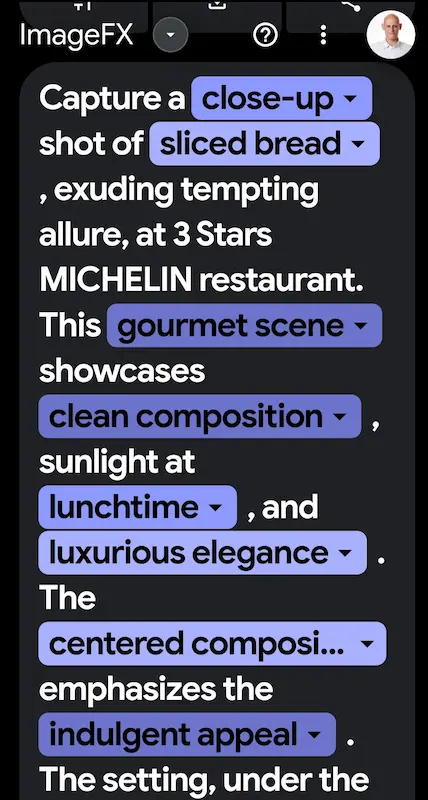
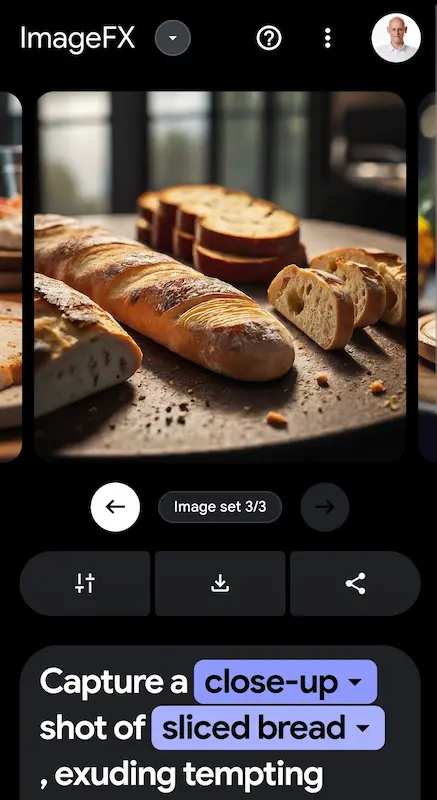
Imagen 2 di Google su ImageFx
Qualche test di Imagen 2 di Google attraverso ImageFX.
In prima battuta, il sistema inizia la fase di ottimizzazione del prompt, in cui va anche a riconoscere le entità descritte. Successivamente genera un set di immagini. Ormai la qualità è sottintesa.
Imagen 2 è disponibile anche direttamente su Bard (che nel frattempo è diventato Gemini), e include il watermarking di SynthID.
Esistono già test che mostrano come prompt generici producono output che potrebbero essere violazioni di copyright.. la questione rimane aperta, ma non c'erano dubbi su questo.


Test di Imagen 2 di Google su ImageFX
Midjourney Niji V6
Midjourney ha rilasciato Niji V6, una versione specifica dedicata agli anime.

Il video mostra un'immagine generata con il modello e animata attraverso Runway Gen 2 da Christopher Fryant.
Activation Beacon: un sistema per aumentare il contesto dei LLM
Activation Beacon è un sistema che permette di estendere (di molto) la finestra di contesto dei LLM.
Nei test è stato usato su Llama 2 estendendo la finestra di token di 100 volte (400k token), ottenendo risultati migliori nella generazione e nella "comprensione".
In pratica usa una sorta di "riassunto intelligente" in cui condensa le informazioni per "ricordarle" in tutto il contesto esteso.
È come se leggessimo un grosso libro, e per ricordare ogni capitolo durante la lettura dei successivi usassimo delle sintesi di qualità.
- GRAZIE -
Se hai apprezzato il contenuto, e pensi che potrebbe essere utile ad altre persone, condividilo 🙂