Generative AI: novità e riflessioni - #10 / 2024
Come funziona Canvas di OpenAI? Un GPT che lavora come "o1" è possibile? CORSI, TEST e RISORSE gratuite, la data analysis con o1 e i bias dei modelli di linguaggio. Novità su Flux 1.1 e l'addestramento con immagini personalizzate. Tutte le novità da Google, Meta, Anthropic, Runway, e molto altro.


Buon aggiornamento, e buone riflessioni..
[corso] AI per agenzie e team digital
Una giornata di formazione e un'opportunità unica per approfondire l'intersezione tra l'AI e il mondo del marketing, dal Prompt Engineering alle declinazioni dell'AI nella SEO, e i casi pratici nell'advertising e nel mondo copy.
Dalle basi alle applicazioni pratiche

Scopri il programma completo e l’offerta sul biglietto.
[corso gratuito] Generative AI for beginners
Microsoft rilascia la terza versione del corso "Generative AI for beginners".
21 lezioni gratuite dedicate allo sviluppo di applicazioni basate sui LLM.
Le lezioni sono etichettate: "Learn" per i concetti, mentre "Build" per esempi di codice (Python e TypeScript).
Il corso fornisce istruzioni anche su come configurare un ambiente di sviluppo.
Un'ottima risorsa, fin dalla prima versione.
Canvas di OpenAI
Ho provato il nuovissimo "Canvas" di OpenAI: un'interfaccia di ChatGPT che consente di lavorare su testi e codice con funzionalità di editing e "trasformazione".
Nei testi, è possibile affinare il contenuto (grammatica, chiarezza, coerenza), cambiare il livello di lettura, aggiustare la lunghezza, ottenere suggerimenti di miglioramento e aggiungere emoji pertinenti.
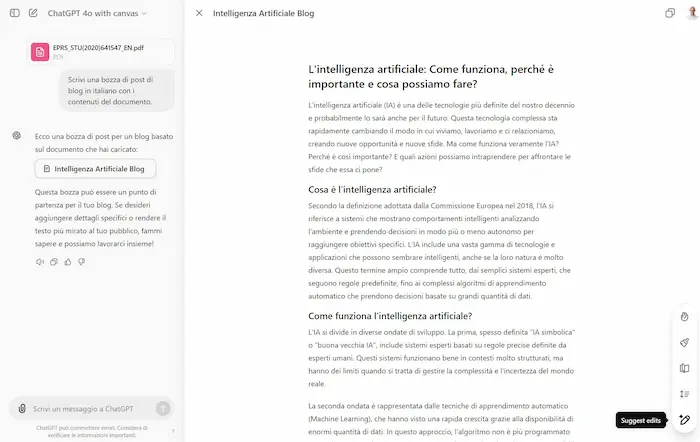
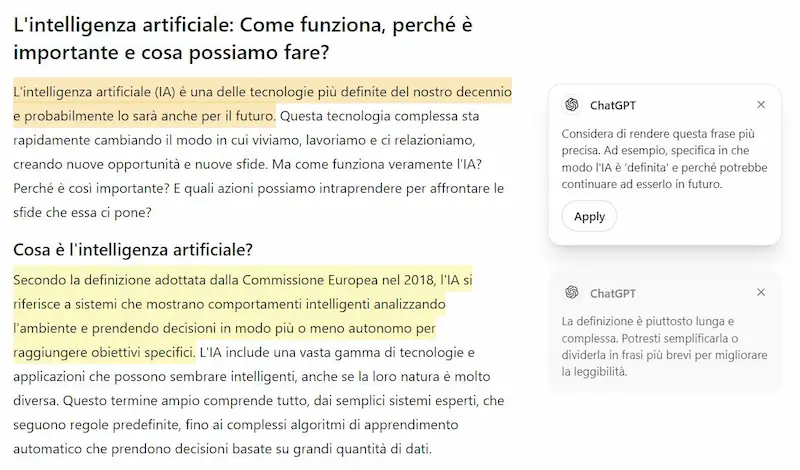


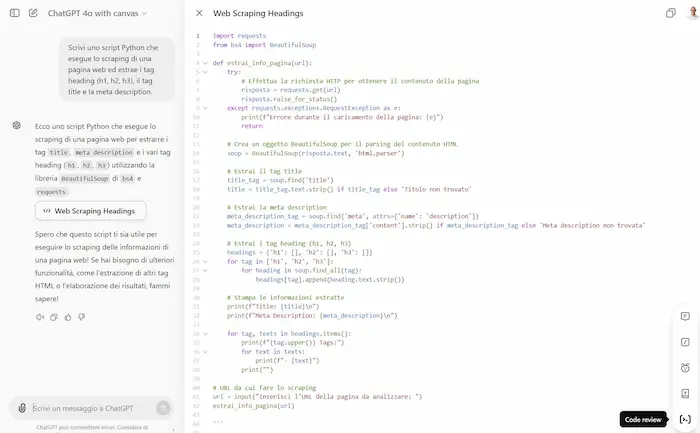
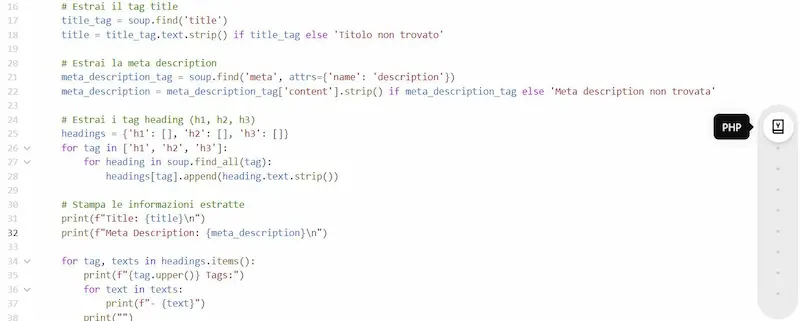

Test di Canvas di OpenAI
Nel codice, possiamo revisionare, aggiungere i commenti, i log, fixare i bug, eseguire il porting ad un altro linguaggio.
In entrambe le modalità, possiamo selezionare un blocco e applicate un prompt specifico alla selezione.
Non una semplice interfaccia.. ma un editor!
Non si tratta solo di un'interfaccia con nuove funzionalità, ma anche un EDITOR a tutti gli effetti.
Questo significa che è possibile lavorare sui contenuti direttamente dalla piattaforma, collaborando con un assistente.
Canvas di OpenAI non è solo una nuova interfaccia
Nel video, un piccolo esempio in cui genero una bozza, faccio modifiche insensate dall'editor, e infine applico la rifinitura. Come si vede il sistema corregge tutti i miei errori e i contenuti fuori contesto.
Uno strumento straordinario, per l'utilizzo di questi sistemi come "assistente personale".
Un GPT che si comporta come "o1" di OpenAI, con risultati simili
Ho fatto eseguire diversi task della presentazione di o1 di OpenAI al mio GPT addestrato per comportarsi allo stesso modo (eseguendo catene di pensiero - CoT).
I prompt sono identici, e i risultati sono ottimi. Nel video si vedono alcuni esempi che nella presentazione sono stati definiti "Reasoning", "Logic Puzzles", "HTML Snake", e "coding".
Un GPT che si comporta come "o1" di OpenAI, con risultati simili
Ho fatto questo test per dimostrare come questa modalità può essere utile per migliorare le performance anche di altri LLM, quando per le risposte servono passaggi logici.
Attenzione: "o1" non è solo questo. Ha un addestramento specifico per sviluppare CoT, e quella che vediamo negli step di ragionamento, non è l'unica CoT che genera (la documentazione lo spiega chiaramente). Ma è uno spunto interessante per migliorare i prompt.
L'analisi dei dati con o1
Anche se o1 di OpenAI non ha accesso a file esterni, possiamo usare un altro modello per analizzarli, per poi usare l'elaborazione di o1.
Nell'esempio, uso GPT-4o per descrivere il dataset, fornendo anche suggerimenti per la pulizia dei dati.
Questo diventa il contesto per il prompt su o1, attraverso il quale ho generato il codice Python per creare un piccolo modello predittivo sul dataset.
Dopo alcune interazioni e revisioni, il sistema fa predizioni con un errore medio inferiore al 15%.



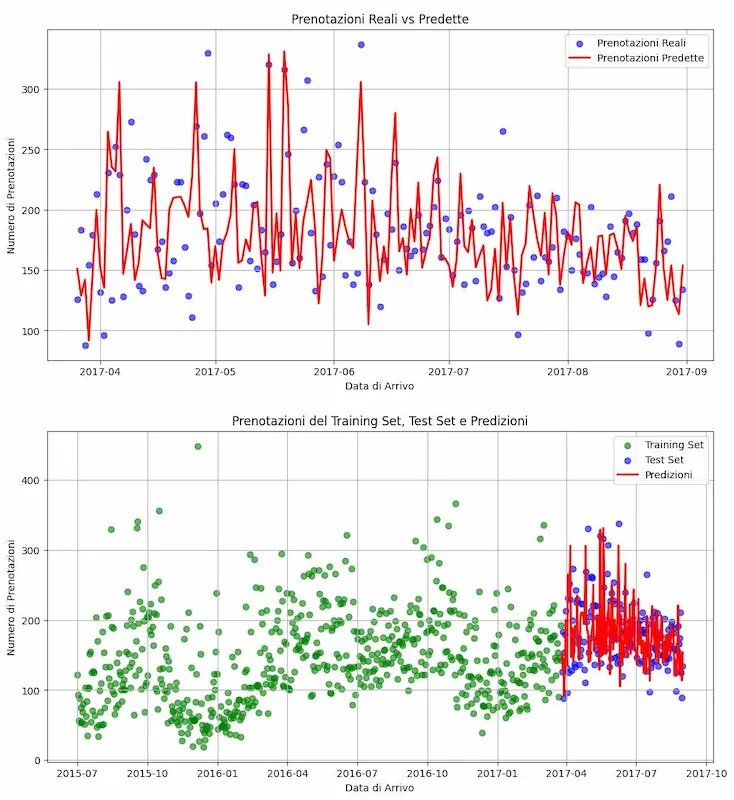
Un test di analisi dei dati usano o1 si OpenAI
Il potenziale di o1 è davvero notevole. Durante tutte le interazioni, non ho mai ottenuto un solo errore nella console Python.
[test] I bias dei modelli di linguaggio
Ho fatto un piccolo test usando gli embeddings di OpenAI per verificare la presenza di bias evidenti.
Ho usato text-embedding-3-large (la rappresentazione più ampia), termini in inglese, e similarità del coseno per il confronto.
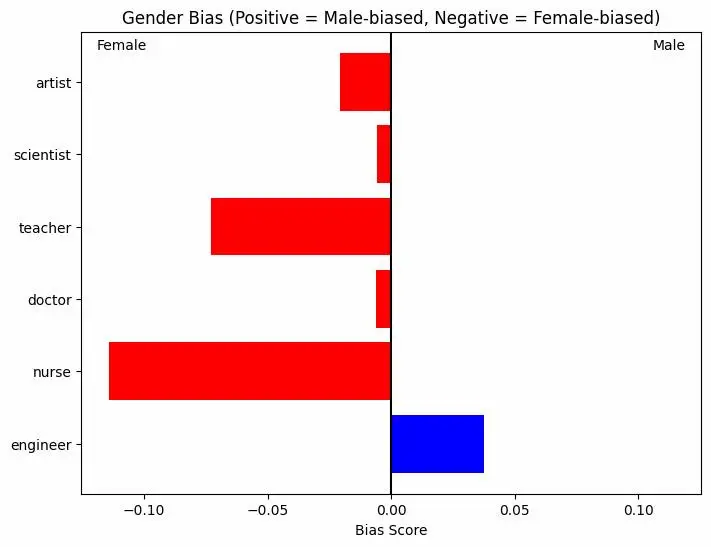
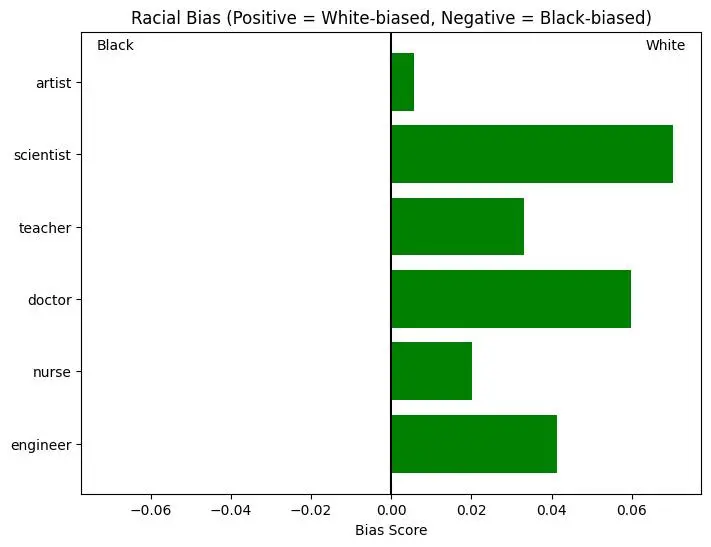
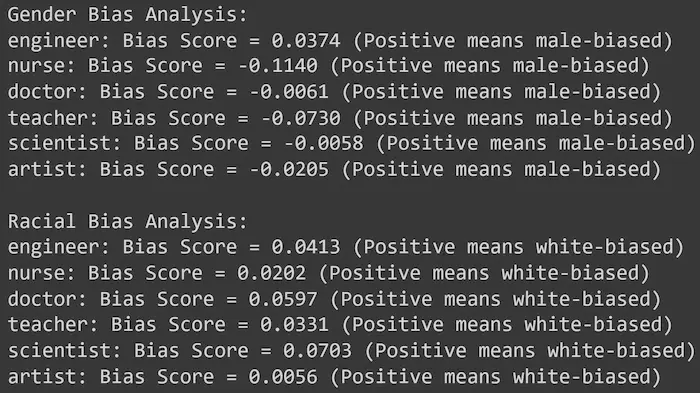
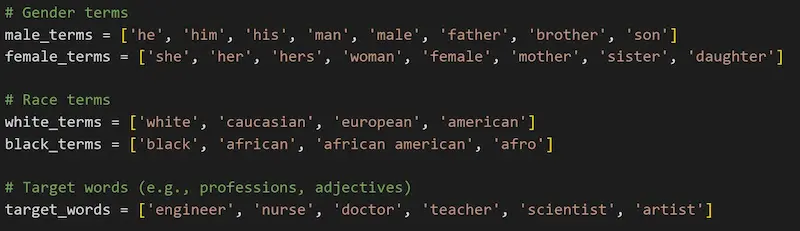
Un test sui bias dei LLM
- C'è sbilanciamento di genere, ma moderato. Solo per il termine "nurse" è significativo.
- C'è sbilanciamento quasi unidirezionale di razza, ma generalmente moderato.
È un test molto limitato, ma credo sia interessante esplorare questi aspetti della rappresentazione dei modelli. Fa capire, inoltre, la meraviglia di questi strumenti in grado di "comprendere" anche sfumature complesse del linguaggio.
[test] Il "code interpreter" di Anthropic
Anche Anthropic introduce su Claude una sorta di code interpreter in grado di sviluppare ed ESEGUIRE codice JavaScript per dare risposte agli utenti.
Può fare calcoli complessi e analizzare dati, e usa Artifacts per la visualizzazione.
Nelle immagini si può vedere in un piccolo test che ho fatto.
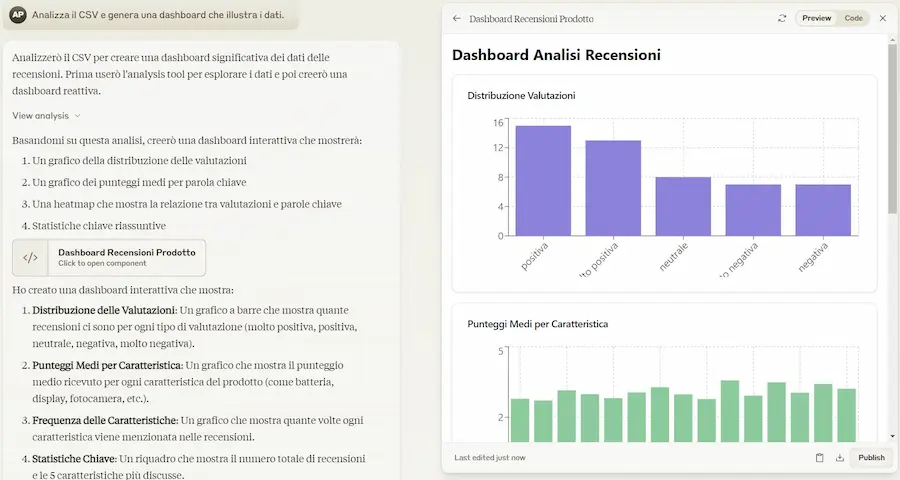
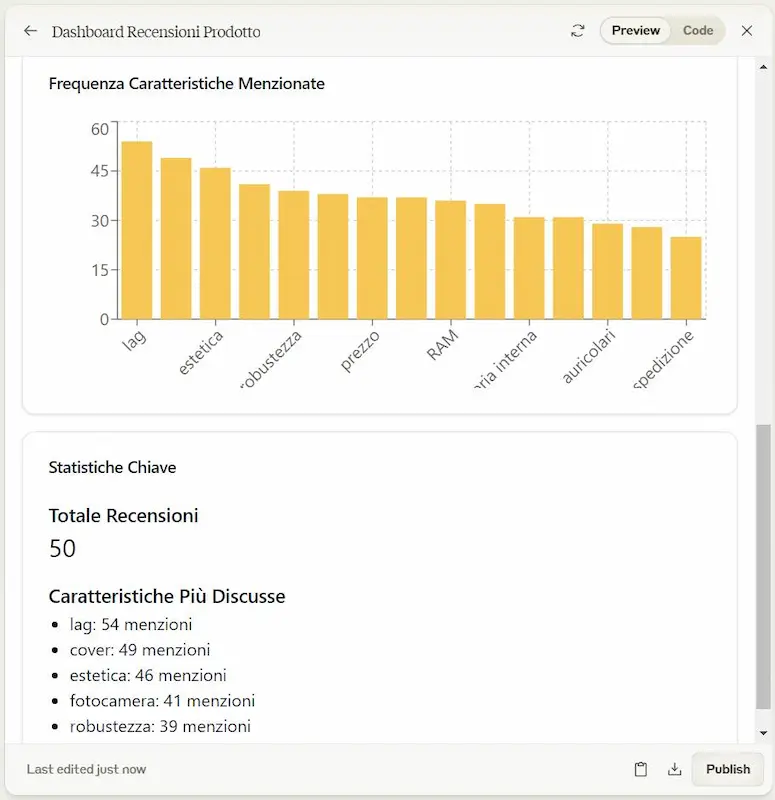
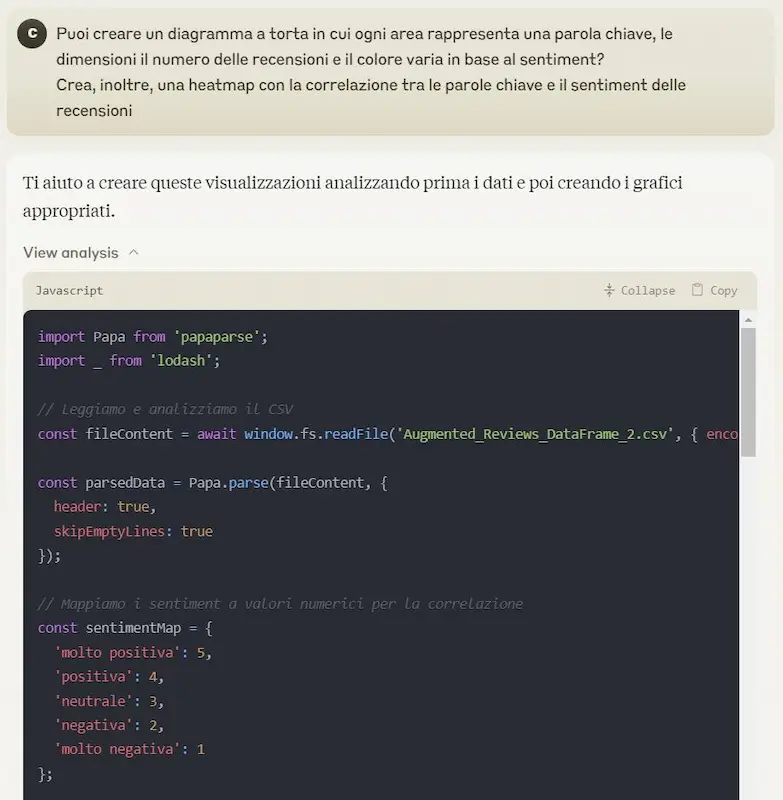
Il "code interpreter" di Anthropic
Chissà perché hanno scelto JavaScript come linguaggio.. forse perché è più orientato a generare un'interfaccia interattiva, ma preferisco la scelta di OpenAI di usare Python per l'analisi e lo sviluppo, per poi agganciare l'interattività al front end.
Flux 1.1 [pro] "blueberry"
Black Forest Labs a rilascia Flux 1.1 [pro] "blueberry", e la beta delle API.
Una release che, secondo Black Forest Labs, segna in passo in avanti significativo nell'ambito della generazione delle immagini.
L'ho provato, e la qualità è oggettivamente sempre migliore.
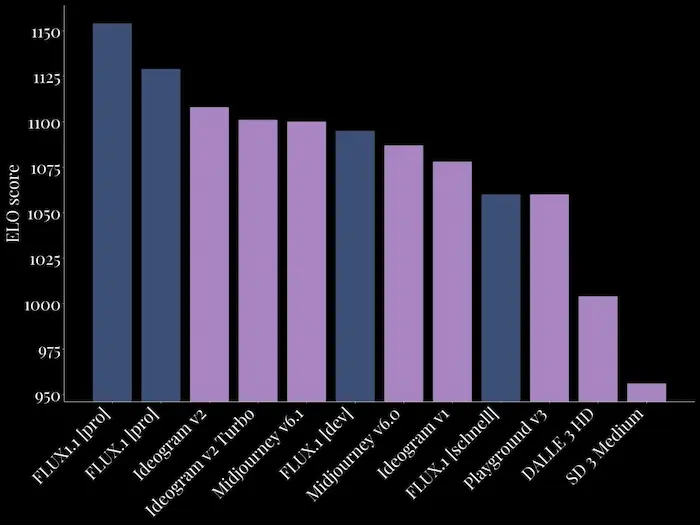



Immagini generate con Flux 1.1 Pro
6 volte più veloce, più aderente al prompt e con qualità di immagine superiore. È già primo nell'Artificial Intelligence Image Arena.
Come provare Flux 1.1 Pro per la generazione di immagini
- Attraverso le API di Black Forest Labs: https://docs.bfl.ml/
- Su FAL: https://fal.ai/models/fal-ai/flux-pro/v1.1.
- Su Replicate: https://replicate.com/black-forest-labs/flux-1.1-pro
- Su Freepik: https://www.freepik.com/pikaso/ai-image-generator
- Su Together: https://api.together.ai/playground/image/black-forest-labs/FLUX.1.1-pro
Come addestrare Flux con immagini di prodotti e/o soggetti
- Su Flux Labs: https://www.fluxlabs.ai/
- Su Flux AI: https://www.useflux.ai/
- Su Replicate: https://replicate.com/lucataco/ai-toolkit/train
L'evoluzione di questi sistemi è davvero interessante, e merita una sperimentazione.
[test] Flux 1.1 pro + Hailuo AI di MiniMax
Ho fatto qualche test con Hailuo AI, un nuovo prodotto della startup cinese MiniMax.
Ho generato i video partendo da immagini create con Flux 1.1 Pro, e aggiungendo prompt testuali per descrivere l'azione.
HailuoAI + #Flux 1.1 Pro + prompt testuale per la generazione video
La qualità è notevole, ma lo è soprattutto l'aderenza dei video alla descrizione testuale. Le azioni dei soggetti sono esattamente quelle che ho descritto negli input.
AI Festival - 26 e 27 febbraio 2025
"Non esiste innovazione senza integrazione. Serve un lavoro sartoriale, di integrazione nei processi. Ed è proprio chi è a conoscenza dei processi aziendali, potenziato da questa tecnologie, che può cogliere i punti strategici dove l'AI può fare la differenza".
Il 26 e 27 febbraio vi aspetto a Milano per l'AI Festival, dove parleremo di questo, ed esploreremo insieme il futuro dell'intelligenza artificiale, scoprendo tutte le novità e tendenze più recenti.
Act-One di Runway
La nuova funzionalità di Runway è impressionante.
Si tratta di Act-One, e consente di creare video con personaggi espressivi attraverso Gen-3 Alpha utilizzando un singolo video come guida e un'immagine del personaggio.
È possibile, ad esempio, creare una scena come questa senza attrezzature sofisticate (nella parte finale del video si può comprendere la tecnica).
Act-One di Runway: un esempio di utilizzo
Le potenzialità sono elevate, come la necessità di gestire gli eventuali "utilizzi negativi".
[test] L'evoluzione di Imagen 3 di Google
Dopo qualche test su Imagen 3 su Gemini Advanced, devo dire che la qualità è cambiata di molto.
Il livello medio dei modelli di generazione di immagini si sta alzando, ma soprattutto sta crescendo l'aderenza al prompt.



L'evoluzione di Imagen 3 di Google
Le immagini sono state generate con istruzioni semplicissime e in italiano.
Non permette ancora output in cui sono presenti persone.
[test] Imagen 3 + Hailuo AI di MiniMax + ElevenLabs Sound Effects
Test di generazione immagini + video + audio.
Ho generato le immagini attraverso Imagen 3 di Google (Text-To-Image), i video con MiniMax (Image-To-Video), l'audio con ElevenLabs Sound Effects (Text-To-Audio).
Imagen 3 + Hailuo AI di MiniMax + ElevenLabs Sound Effects
Ancora una volta, non è tanto la qualità a stupirmi, ma l'aderenza degli output ai prompt.
Spesso la domanda è: quanto tempo serve per generare gli output? Pochi minuti. Ma la vera domanda è: come avrei potuto crearli senza questi mezzi!?
AI Assistant su Chrome DevTools
AI Assistant è una nuova funzionalità sperimentale di Chrome DevTools davvero notevole.
Permette di usare Gemini per applicare prompt alla pagina web o a elementi specifici, per spiegazioni o suggerimenti di implementazione, con la possibilità di applicarli direttamente.
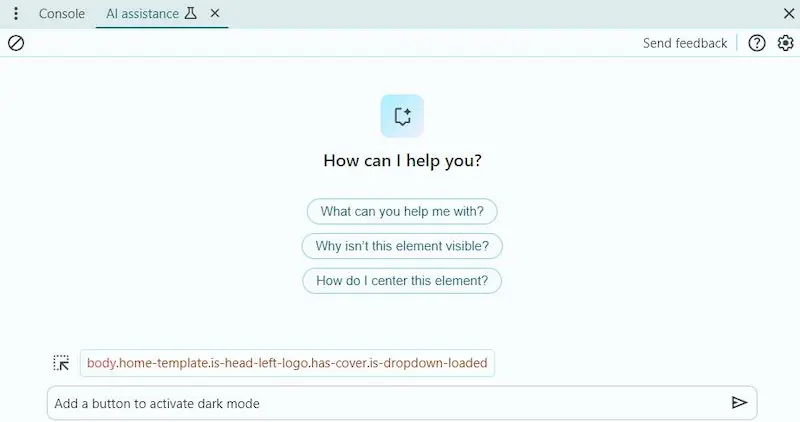
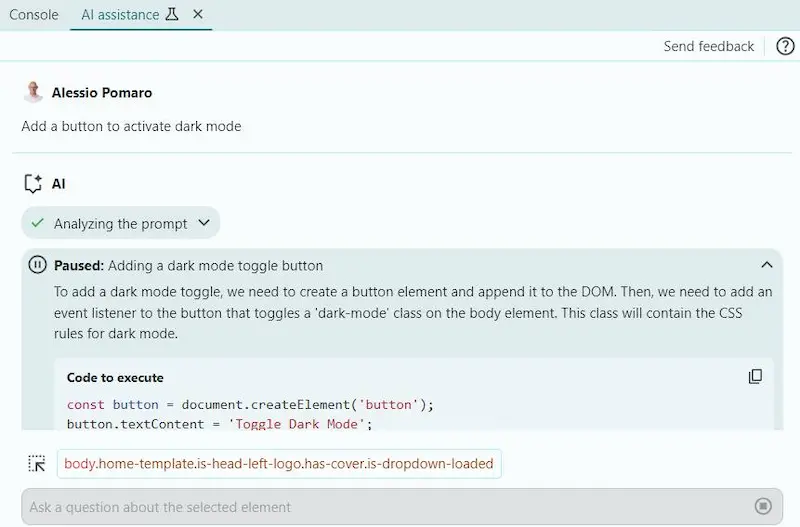
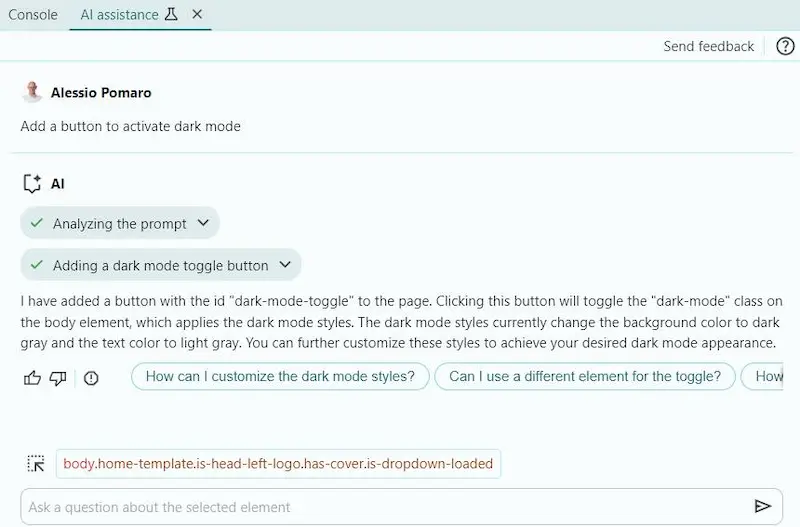
AI Assistant su Chrome DevTools
Nelle immagini lo uso per fare alcune azioni che modificano la pagina, con generazione di JS e CSS. Creo il bottone per la "dark mode".
Advanced Voice Mode di ChatGPT
Prime impressioni sull'Advanced Voice Mode di ChatGPT..
- Anche se sono stati fatti grandi passi, in italiano, non siamo ancora a livelli di fluidità della versione USA.
- Il comportamento dell'agente non è il massimo: per una "chiacchierata", un mio GPT addestrato per questo scopo, dà un'esperienza migliore. Infatti, quando questa modalità sarà attiva anche per GPT custom, tutto diventerà molto più interessante. Ricordate le applicazioni vocali di Alexa e Google Assistant?
- Non accede al web per reperire informazioni.
- L'interruzione del parlato dell'assistente, non funziona benissimo, ma credo sia una questione di hardware.

Advanced Voice Mode di ChatGPT
Insieme a Gemini Live, siamo di fronte a un nuovo capitolo dell'interazione vocale. Un salto importante rispetto al precedente, ma il percorso verso la naturalezza non è concluso.
Atlas di Boston Dynamics
Boston Dynamics ha pubblicato un video impressionante sull'evoluzione di Atlas, il suo robot umanoide.
E specifica che le azioni NON sono pre-programmate o teleguidate: il robot esegue le azioni di spostamento dei componenti autonomamente, eseguendo un compito.
L'evoluzione di Atlas Boston Dynamics
Il tutto, due settimane dopo l'accordo epocale dell'azienda (di proprietà di Hyundai) con Toyota Research Institute.
Questa partnership è un esempio di due aziende con una solida base di ricerca e sviluppo che si uniscono per lavorare su molte sfide complesse, e costruire robot utili che risolvono problemi del mondo reale.
Spark di GitHub Copilot
Non solo GitHub Copilot integrerà tutti i LLM più potenti, che gli sviluppatori potranno scegliere anche in base alle attività (Claude 3.5 Sonnet di Anthropic, Gemini 1.5 Pro di Google, GPT-4o e o1 di OpenAI), ma è stato presentato anche Spark: uno strumento per creare applicazioni interamente in linguaggio naturale.
Spark di GitHub Copilot
Gli "spark" sono micro app completamente funzionali che possono integrare funzionalità AI e fonti di dati esterne.
SynthID-Text di Google DeepMind
SynthID-Text di Google DeepMind è un nuovo metodo per aggiungere una filigrana ai testi generati da LLM, senza degradare la qualità dell'output.
Il sistema, che ha come obiettivo quello di riconoscere i testi generati, è stato reso open-source per proporre uno standard di integrazione.
La filigrana, successivamente può essere rilevata da un algoritmo.
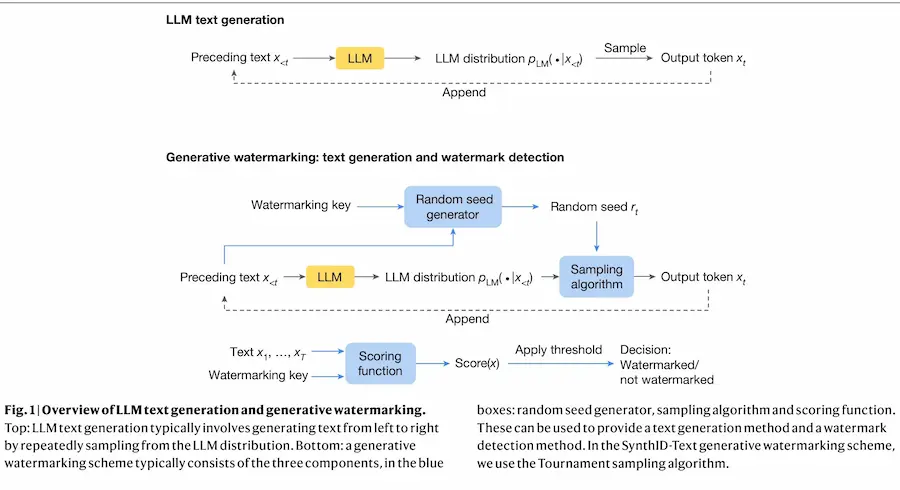
Qual è il problema!? Una rielaborazione o una traduzione invalideranno la filigrana.
Il percorso per sistemi di questo tipo è necessario, ma rimane lungo e difficile, con soluzioni ancora fragilissime.
Microsoft introduce gli agenti autonomi in Copilot Studio
Grazie a questa funzionalità, i developer possono creare assistenti in grado di usare dati di diverse fonti (es. Microsoft 365 Graph, Dataverse e Fabric), e di automatizzare i processi aziendali.
Gli agenti autonomi in Copilot Studio
Gli agenti operano autonomamente su attività ripetitive o complesse, consentendo di ridurre i tempi di esecuzione e i costi, migliorando al contempo l'efficienza complessiva.
Computer Use di Anthropic
Anthropic introduce la funzionalità "Computer Use" con i nuovi modelli 3.5.
La nuova capability è sperimentale e consentirà a Claude di interagire con un dispositivo via API (muovere il cursore, cliccare, digitare, ecc.). Sarà disponibile nei prossimi mesi.

I nuovi modelli Sonnet e Haiku 3.5 hanno performance migliori, raggiungendo la versione Opus in alcune funzioni.
Sono molto curioso delle applicazioni che nasceranno dalla possibilità di interfacciarsi con i device.
Le versioni quantizzate per Llama 3.2
Meta ha lanciato versioni quantizzate di Llama 3.2 1B e 2B, progettate per funzionare direttamente sui dispositivi mobile.
Consentono l'implementazione diretta su smartphone e tablet con performance comparabili alle versioni più grandi.
Alcuni dati di performance: velocità maggiore di 2-4 volte, riduzione delle dimensioni del 56%, riduzione del 51% dell'uso di memoria.


I modelli piccoli diventano sempre più interessanti per gli sviluppi in locale sui device, con una competizione al pari dei modelli più grandi.
Multimodal Embed 3 di Cohere
Cohere lancia una novità davvero interessante: un nuovo modello di AI che crea uno spazio di incorporamento unificato per testo e immagini.
Si chiama Multimodal Embed 3, e consente il confronto diretto tra testo e contenuto visivo senza pipeline di elaborazione separate.
Immaginiamo, ad esempio, le potenzialità nella ricerca in ambito e-commerce combinando query visive e testuali, oppure nel recupero delle informazioni da una knowledge.

Più si evolve questa capacità di rappresentazione attraverso gli embeddings, e più la ritengo una piccola opera d'arte tecnologica.
Firefly Video: l'integrazione su Premiere Pro
Adobe, durante la conferenza MAX ha presentato Firefly Video, e l'integrazione su Premiere Pro.
La funzionalità "Generative Extend", infatti, permette di creare prolungamenti delle clip senza la necessità di di ulteriori riprese.
Oltre a questo, hanno anche presentato l'interfaccia web per azioni di Text-To-Video e Image-To-Video.
Firefly Video: l'integrazione su Premiere Pro
La qualità, ormai, non stupisce più.. ma l'integrazione nei software più usati dai creator è una carta vincente.
L'AI generativa a supporto dell'e-commerce
L'AI può essere uno strumento utile a mettere in atto strategie con un effort ridotto. In questo caso, ha permesso operazioni che sarebbero state insostenibili per il progetto.
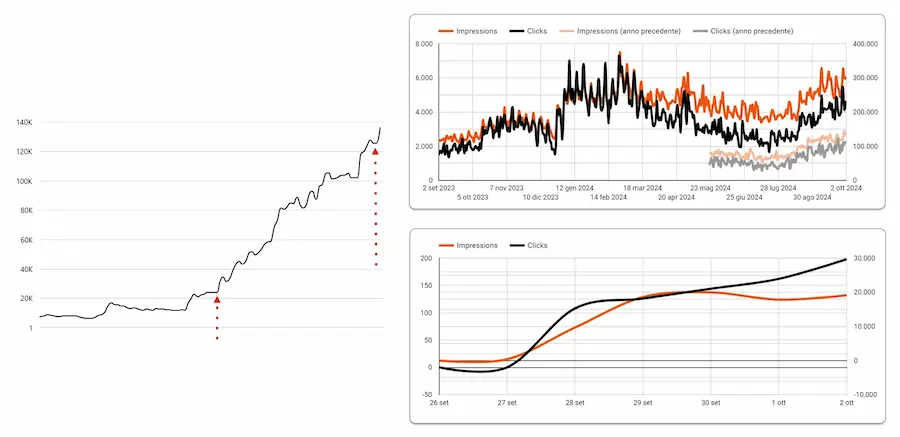
I diagrammi, infatti, mostrano i risultati di azioni di ottimizzazione su un e-commerce, basate sui dati, e messe in atto attraverso un LLM.
Un ingranaggio nei flussi operativi in grado di avvicinare la strategia agli obiettivi.
La trappola delle allucinazioni dei LLM
In realtà, cadere nella trappola delle "allucinazioni" che i LLM possono produrre è più facile di quanto si pensi.
Un esempio di allucinazione prodotta da un LLM
Nella prima parte del video, uso Llama 3.1 senza accesso al web.
Quindi come genera l'output? Usa il contenuto che ha a disposizione per completare il task: il nome del prodotto, le parole che compongono lo slug dell'URL, e ciò che deriva dal training del modello.
È convincente? Insospettabile, direi.. ma fuori controllo! Si tratta di un'allucinazione.
Nella seconda parte, uso uno scraper che va ad estrarre il testo dall'URL, quindi l'output aderisce alle informazioni nella pagina.
Takeaway: i LLM producono "allucinazioni" quando non hanno contesto sufficiente per poter completare il task. È necessario un "contesto controllato".
Serve questa consapevolezza per usarli con maggior sicurezza, e servono strumenti come Opik, o sistemi multi-agent, per effettuare test e controlli approfonditi degli output prima di andare in produzione.
La supervisione umana e il pensiero critico
Un paper molto interessante di Harvard Business School che sottolinea l'importanza di sviluppare competenze di interazione dell'AI nei processi di valutazione creativi che combinano il giudizio umano con le intuizioni dell'Intelligenza Artificiale.

Mentre l'AI può standardizzare il processo decisionale per criteri oggettivi, la supervisione umana e il PENSIERO CRITICO rimangono indispensabili nelle valutazioni soggettive, dove l'AI dovrebbe integrare, non sostituire, il giudizio umano.
Ministral 3B e 8B
La competizione sui LLM "piccoli" inizia a diventare interessante quanto quella sui modelli "grandi".
Mistral rilascia due nuovi modelli destinati all'elaborazione on-device e a casi d'uso at-the-edge: Ministral 3B e 8B.
Offrono prestazioni avanzate in ambiti come la comprensione del contesto, il "ragionamento" e l'efficienza, con contesti fino a 128k token.
Sono pensati per applicazioni come traduzione on-device, assistenti intelligenti offline e robotica autonoma.
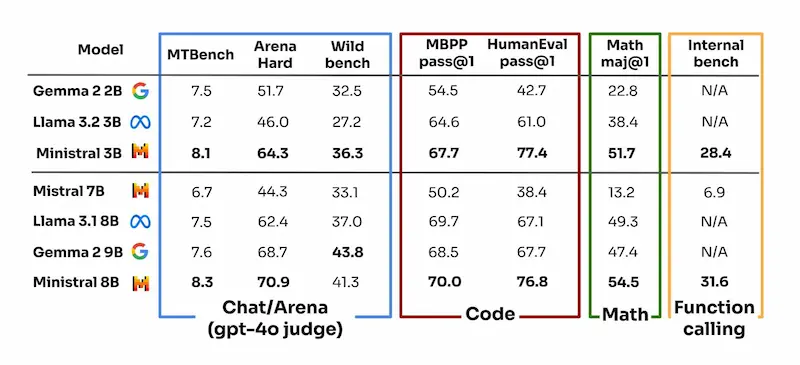
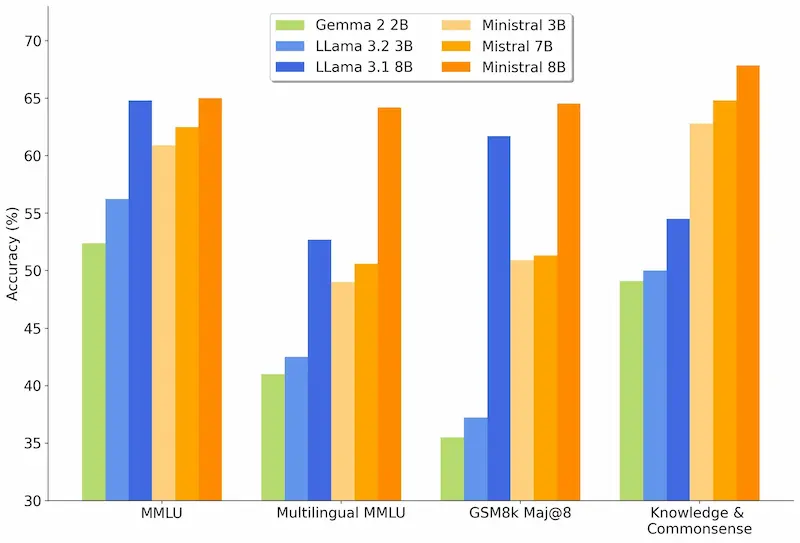
Ministral 3B e 8B: performance
Le performance sono migliori rispetto ai concorrenti, con un'attenzione particolare alla privacy e alla latenza ridotta.
State of AI 2024: una sintesi
Una sintesi dei punti chiave del report "State of AI" 2024.



State of AI 2024: una sintesi
- Convergenza delle prestazioni dei modelli. I modelli open-source, come Llama 3.1 405B, hanno ormai raggiunto le prestazioni dei modelli proprietari. Llama 3.2 espande le capacità in modalità multimodale, dimostrando la crescente competitività dei modelli open-source.
- Avanzamenti dell'AI cinese. Nonostante le sanzioni statunitensi, i modelli AI cinesi continuano a scalare le classifiche, sfruttando hardware stoccato, accesso cloud e soluzioni alternative. Ciò evidenzia la resilienza del settore AI cinese.
- Miglioramenti in efficienza. Tecniche di pruning e distillazione hanno migliorato significativamente l'efficienza dei modelli di testo e immagini, mostrando che alte prestazioni possono essere raggiunte con modelli più piccoli e meno dispendiosi.
- Espansione delle applicazioni AI. I modelli di linguaggio (LLMs) stanno dimostrando capacità in campi scientifici come la progettazione di proteine e l'editing genetico, aprendo nuovi orizzonti per l'AI in biologia e genomica.
- Sfide per hardware e infrastrutture. Nvidia continua a dominare l'hardware AI, ma l'incremento della domanda energetica per le infrastrutture AI sta creando pressioni sulle risorse e minacciando gli impegni di sostenibilità delle aziende tecnologiche.
Movie Gen di Meta
Meta presenta Movie Gen, un nuovo modello per la generazione di video e audio di alta qualità da prompt multimodale.
Le funzionalità principali:
- generazione video da una descrizione testuale;
- video personalizzati;
- editing video;
- generazione di audio (musica ed effetti sonori).
Movie Gen di Meta
È stato addestrato su dataset pubblici e con licenza, e punta a diventare un riferimento per registi e i content creator.
I nuovi tool di HuggingChat
HuggingChat, oltre alla possibilità di usare i migliori LLM open source, mette a disposizione una serie di tool molto interessanti (es. scraping, analisi dei file, generazione di immagini).
Nell'esempio, uso il sistema con Llama 3.1, e aggiungo Flux Realism Lora per la generazione di immagini.
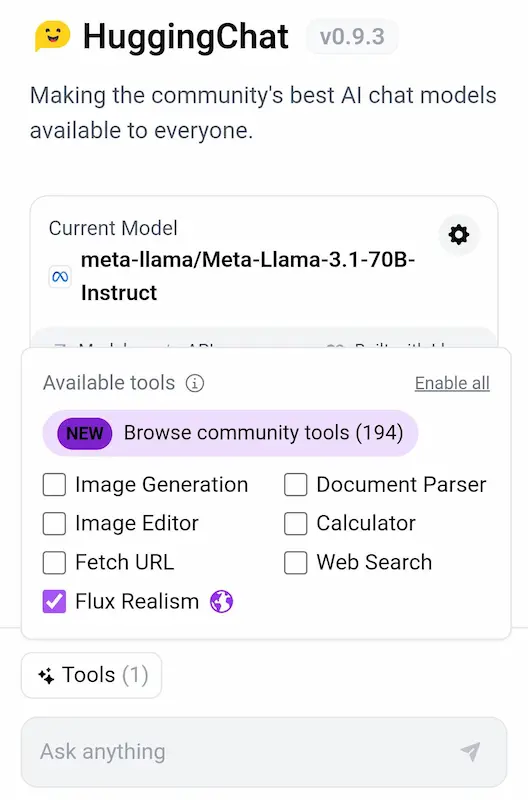
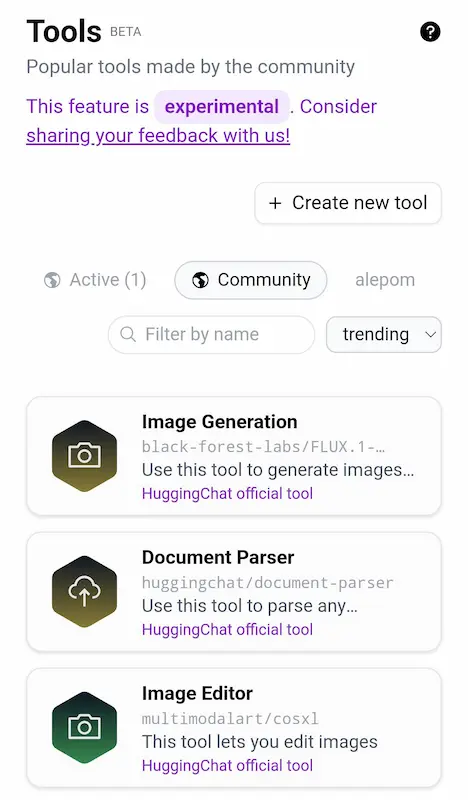
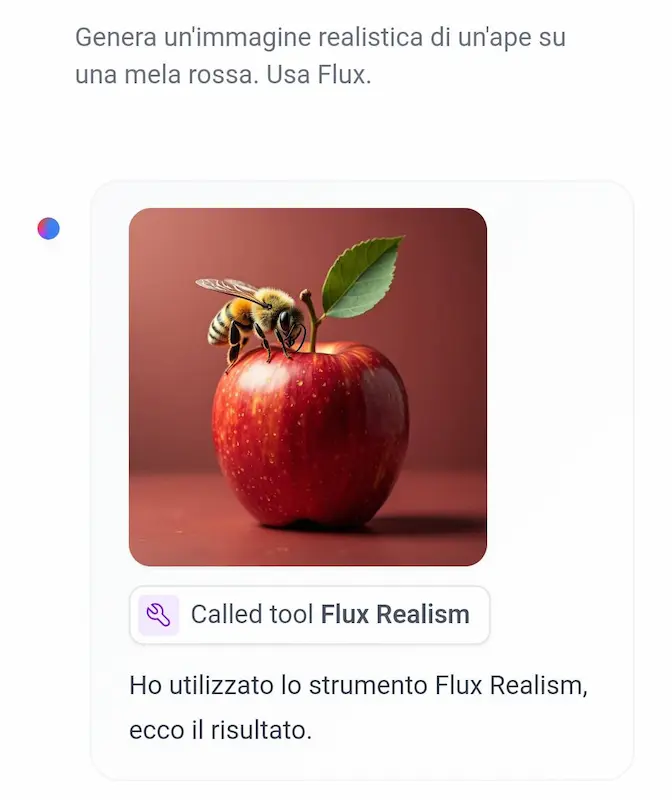
I nuovi tool di HuggingChat
Il parco strumenti è molto ampio, e possono essere attivati più tool contemporaneamente.
Leo AI di Brave
Brave sta introducendo il suo assistente basato su AI generativa: Leo AI, che può interagire direttamente con le pagine web che si navigano dal browser.
Un aspetto interessante, è che il sistema può lavorare con un LLM locale, sfruttando Ollama.
Questo, ad esempio, consente di far elaborare anche dati personali al modello, senza che questi lascino il dispositivo.
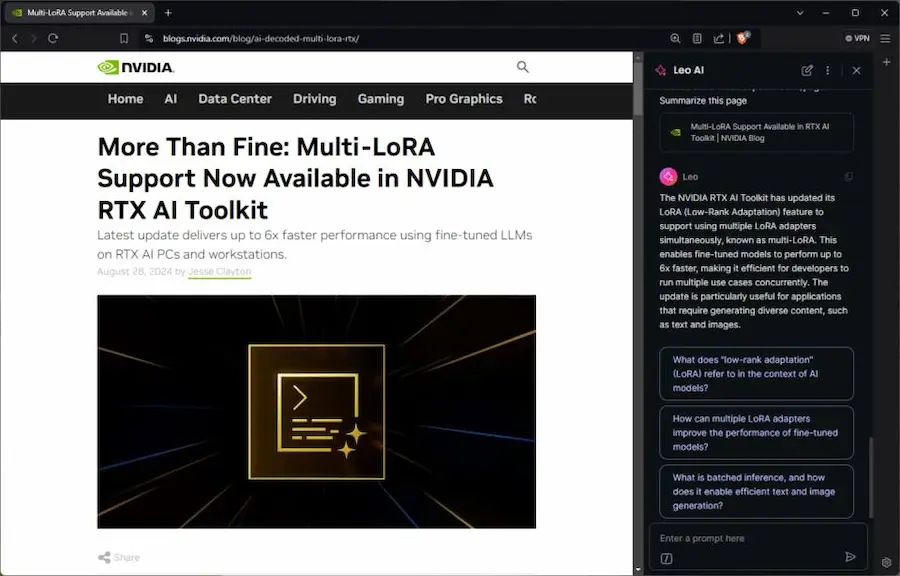
Sfruttando un hardware Nvidia RTX è possibile ottenere altissime performance anche in locale. Con Llama 3 8B, ad esempio, si può ottenere la velocità di 149 token/secondo.
L'utilizzo dei LLM in locale è sempre più "possibile".
Llama Stack di Meta
Meta rilascia un componente davvero interessante: Llama Stack.
Si tratta di un framework open source per semplificare e standardizzare lo sviluppo e il rilascio di applicazioni basate sui LLM.
Facilita l'integrazione di azioni come inferenza, gestione della memoria, moderazione / sicurezza.
 meta-llama
meta-llamaAd esempio, usando le API di inferenza, memoria e sicurezza si possono creare assistenti che rispondono in modo contestuale e sicuro.
Standard e linee guida è quello che serve per facilitare l'integrazione di questi sistemi in modo più sicuro ed efficiente.
Semantic Cache di Redis
Semantic Cache di Redis è un esempio di componente che permette di ottimizzare le applicazioni RAG (Retrieval Augmented Generation).
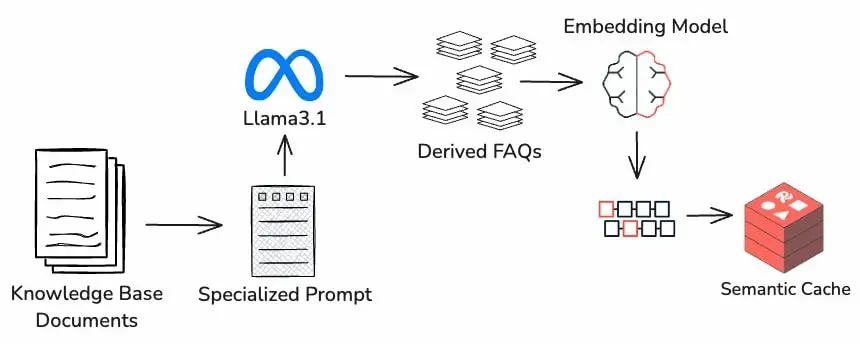
È un sistema che salva, vettorializza e indicizza le richieste degli utenti e le risposte. In questo modo, se vengono poste domande simili dal punto di vista semantico, non ci sarà bisogno di usare nuovamente il LLM.
Risultato: abbattimento dei tempi di risposta e dei costi.
SciAgents: l'AI al servizio della scoperta scientifica
SciAgents è un sistema di Intelligenza Artificiale che automatizza la scoperta scientifica combinando grafi ontologici della conoscenza, modelli di linguaggio (LLM) e sistemi multi-agent.
Ogni agente ha un ruolo specifico, come creare ipotesi, espanderle o criticarle.
Gli agenti lavorano insieme per esplorare dati scientifici, identificare nuove connessioni e generare proposte di ricerca innovative.
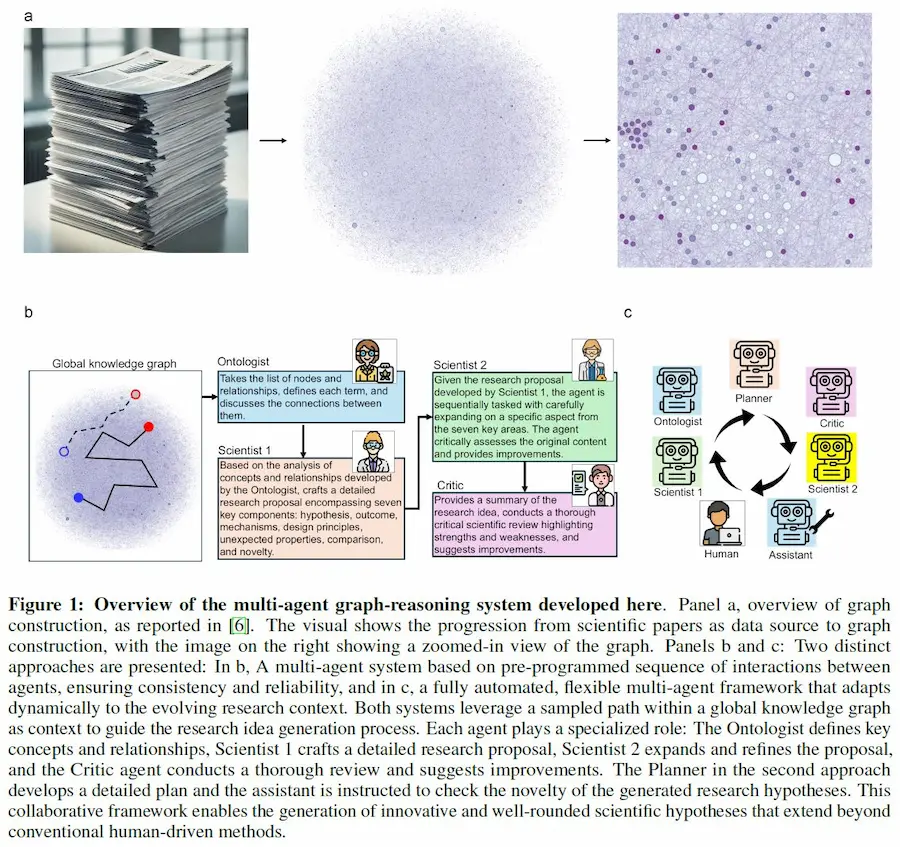
Il sistema ha rivelato relazioni interdisciplinari nascoste e prodotto scoperte significative, superando i metodi di ricerca tradizionali per precisione e scala, accelerando così la scoperta scientifica.
DevDay di OpenAI
Cosa è stato condiviso durante il DevDay di OpenAI di San Francisco?
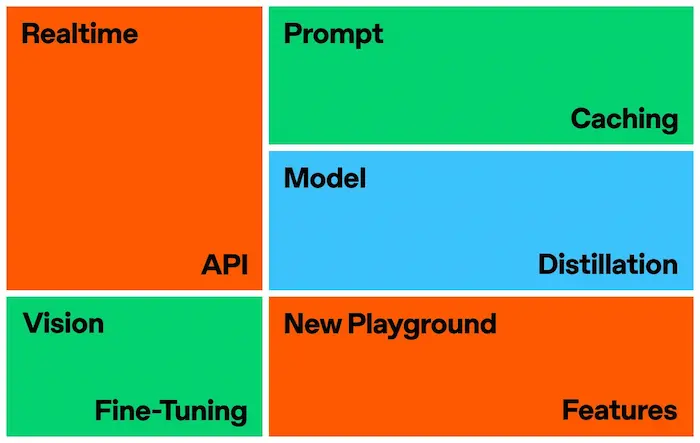
Vediamo una sintesi per punti.
- Realtime API: consente esperienze di voice-to-voice a bassa latenza, simili a ChatGPT Advanced Voice, con 6 voci preimpostate. Beta disponibile per tutti gli sviluppatori.
- Prompt Caching: disponibile per tutti, riduce i costi del 50% e la latenza riutilizzando i token di input recenti.
- Model Distillation: nuovo workflow per addestrare modelli più piccoli ed efficienti basati su modelli più grandi. Include Stored Completions ed Evals (beta).
- Vision Fine-Tuning: possibilità di fine-tuning di GPT-4o con testo e immagini, migliorando la ricerca visiva e l'analisi delle immagini.
- Aggiornamento di GPT-4o: nuovo modello gpt-4o-2024-08-06 con costi di input ridotti del 50% e output ridotti del 33%.
- Disponibilità OpenAI o1: accesso API esteso ai modelli di ragionamento o1-preview e o1-mini per gli utenti di livello 3. Limiti di velocità aumentati per livelli 4 e 5.
- Generazione nel Playground: nuovo pulsante "Generate" per creare automaticamente prompt, definizioni di funzioni e schemi strutturati.
Il toolkit per l'implementazione di applicazioni basate sui LLM di OpenAI si amplia notevolmente!
Assistant Editor di LangChain
LangChain ha annunciato "Assistant Editor", una nuova potente funzionalità di LangGraph Studio che rende più facile la configurare e la personalizzazione degli agenti basati su modelli di linguaggio.
Assistant Editor di LangChain
Questo strumento di editing visivo consente sia agli sviluppatori che agli utenti non tecnici di mettere a punto il comportamento degli agenti senza usare codice.
Pika 1.5
Pika presenta la versione 1.5, con clip più lunghe, nuovi effetti, riprese cinematografiche e movimenti più realistici.
Il video è l'unione di clip di alcuni creator che stanno testando il nuovo modello.
Pika 1.5
La generazione di video fa costanti passi in avanti, e le clip diventano sempre più usabili in ambito professionale.
Edge Runner di Nvidia
EdgeRunner è una nuova tecnologia di Nvidia in grado di generare mesh 3D di alta qualità con fino a 4.000 facce e una risoluzione spaziale di 512, partendo da immagini e point-clouds.
Utilizza un innovativo algoritmo di tokenizzazione per comprimere le mesh in sequenze di token 1D, migliorando l'efficienza e la qualità della generazione.
Edge Runner di Nvidia
Il sistema può creare varianti diverse da un singolo input, garantendo una grande varietà di risultati.
Immaginiamo questi sistemi al servizio di videogiochi e realtà virtuale (VR), effetti speciali e animazione nella produzione cinematografica e televisiva, architettura e design, additive manufacturing e stampa 3D, medicina e biotecnologie.
Liquid Foundation Models
Liquid AI introduce una nuova architettura per LLM che "sfida" i Transformer, superando le performance di Llama 3.2 (a parità di dimensioni), con ingombro di memoria ridotto e maggior efficienza nell'inferenza.
Ho provato la versione più grande (40.3B Mixture of Experts - MoE) sul mio benchmark di test.
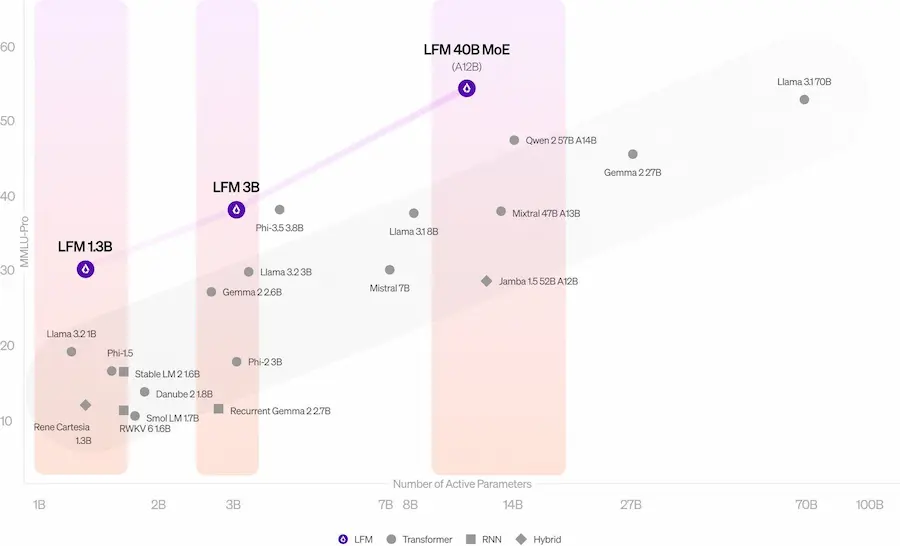



Un test del LLM di Liquid AI
Considerando le dimensioni, il sistema promette benissimo, e ha una velocità degna di nota.
Open NotebookLM
Continuano a nascere progetti che trasformano documenti e pagine web in podcast.
Open NotebookLM è un sistema basato su modelli AI open source: Llama 3.1 405B, MeloTTS, e Bark.
Dall'interfaccia di Hugging Face, è possibile caricare file e specificare URL per creare il contesto al modello.
Un test di Open NotebookLM
Il podcast viene generato dal LLM e ottiene la voce dal TTS.
La qualità non è enorme, ma è un esempio di applicazione semplice per questo scopo.
- GRAZIE -
Se hai apprezzato il contenuto, e pensi che potrebbe essere utile ad altre persone, condividilo 🙂