Generative AI: novità e riflessioni - #3 / 2025
Nuovi LLM (Google, OpenAI, DeepSeek), nuovi modelli per la generazione di immagini, un grande fermento nel mondo open source, nuove tecniche per migliorare l'inferenza e l'efficienza, nuovi strumenti per sviluppare AI Agent performanti. La crescita continua.


Buon aggiornamento, e buone riflessioni..
Gemini 2.5 Pro: test
Google ha rilasciato Gemini 2.5 Pro, il nuovo modello più potente e dotato di "reasoning". L'ho provato, e nel video ho inserito diversi test.
Alcuni test di Gemini 2.5 Pro
Le azioni di coding sono notevoli. Con un'unica esecuzione ho creato un software con interfaccia grafica in grado di elaborare un PDF, con estrazione di un range di pagine, conversione in immagine, compressione, rotazione, unione.
In pochi minuti (ma con un prompt estremamente dettagliato) ho generato un semplice sistema predittivo basato su una rete neurale che si è dimostrato valido alla prima esecuzione, con training e prediction su un dataset di test.
Il gioco basato in HTML, CSS e JS, è carino, ma soprattutto, l'aderenza al prompt è elevata.
In generale, sui task è velocissimo. L'estrazione dei contenuti dai video è precisa, con trascrizione e suddivisione degli speaker. Anche sui test di logica e matematica, il modello si è comportato bene.
Un'altra novità è la possibilità di inserire un URL di YouTube in AI Studio, e il contenuto diventa contesto per il modello. Questo significa che si potrà avere questa dinamica via API.
Google ormai ha trovato l'equilibrio, e il modello è già primo nella LLM Chatbot Arena Leaderboard.
Come sempre, Google ha dalla sua parte l'integrazione nel suo ecosistema: con uno schiocco di dita può inserire i modelli ovunque. E lo sta già facendo.
Parallelamente a tutto questo, il progetto Astra sta arrivando sull'app di Gemini, trasformandolo in un sistema multimodale in grado di processare lo streaming video della fotocamera in tempo reale.
Ricordiamoci, inoltre, che questi modelli vanno direttamente ad alimentare l'ambito della robotica, quindi, più si evolvono..
Generazione di immagini: il nuovo modello di OpenAI
OpenAI, con il nuovo modello di generazione di immagini su GPT-4o, colma un gap aperto da molto tempo rispetto ai competitor.
L'ho provato.. inutile dire che la qualità è altissima.



Il nuovo modello di generazione di immagini di OpenAI
Oltre al realismo delle immagini, è incredibile l'aderenza al prompt: le istruzioni per l'immagine degli astronauti, ad esempio, è iper dettagliato, con anche le stringhe per i cartelli.
Gli effetti e le modifiche sono semplici da applicare, ma soprattutto.. ora davvero si possono realizzare delle infografiche coerenti.
In questo test, ho dato come input a GPT-4o il post che ho scritto sugli argomenti di un mio talk, le foto dei personaggi della storia (probabilmente qualcuno li riconoscerà) con le loro caratteristiche, e la descrizione dell'ambientazione.




Un fumetto generato con il nuovo modello di OpenAI
Un semplice test per mettere a fuoco il potenziale di prototipazione che abbiamo a disposizione con questi strumenti. Con dell'ulteriore lavoro, e qualche "colpo" di editing (che io non ho messo in atto), è davvero possibile ottenere un POC interessante in poco tempo.
Di certo la concorrenza non manca, ma questo è un bel colpo per OpenAI, che lo porterà anche su Sora per avere un sistema visuale completo.
GPT-4o: una nuova versione
OpenAI ha rilasciato una nuova versione di GPT-4o.
Più creativo, collaborativo, migliore nel coding e nella comprensione dei prompt.
Provandolo su ChatGPT, i miglioramenti sono percepibili nell'interazione e negli output, ma non basta per raggiungere le performance di Gemini 2.5 Pro.
Immagino che tutti si stiano chiedendo il senso di GPT-4.5.. è un'ottima domanda. È sempre più il modello da "guardare ma non toccare".
Google evolve AI Overviews e presenta AI Mode
Google aggiorna AI Overviews con Gemini 2.0, e introduce AI Mode.
AI Mode porta il "reasoning" nella Search per spingere il LLM a rispondere anche a domande più complesse, con la possibilità di follow-up.
Il sistema mette in atto un piano di ricerca, ha accesso ai risultati indicizzati, ma anche ai dati strutturati a disposizione di Google (es. il knowledge graph).
Usa una tecnica di "query fan-out" per creare più ricerche correlate ed esplorare i sotto-argomenti e altre fonti di dati, espandendo le risposte.
AI Overviews e AI Mode
Nel momento del lancio, AI Overviews con Gemini 2.0 era attivo negli USA, mentre AI Mode è in fase sperimentale su Labs. Oggi stanno rilasciando AI Overviews in diversi paesi, tra cui l'Italia.
Pichai aveva annunciato grandi novità per la ricerca quest'anno.. beh, mi sembra che la trasformazione stia iniziando.
Test di AI Mode
Ho fatto alcuni test del sistema, e vediamo alcune osservazioni. Le risposte alle query informative sono ben strutturate e molto più dettagliate rispetto a AI Overviews, e spesso non presenta le stesse fonti.
L'uso delle query di follow-up per espandere la sessione di ricerca è estremamente interessante, e ormai intercetta una modalità sempre più naturale per gli utenti.
I link verso le fonti sono ben in evidenza, ma, visto il dettaglio delle risposte, probabilmente i clic saranno limitati.. direi che possiamo considerare la stessa frequenza con la quale clicchiamo le fonti negli altri sistemi ibridi (Search di ChatGPT, Perplexity, Search di Grok, ecc.). Di certo, quei clic saranno pochi, ma di utenti ben motivati ad approfondire.
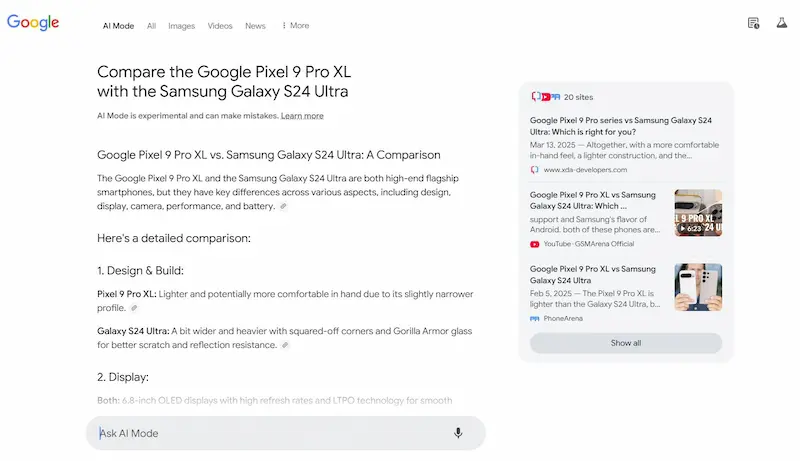
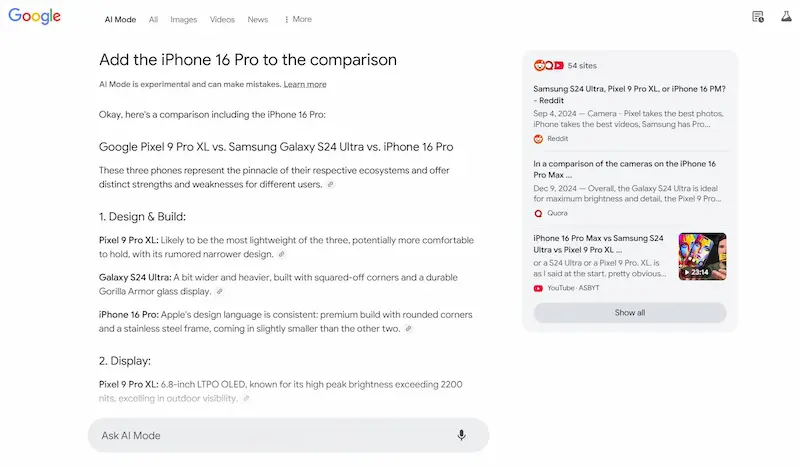
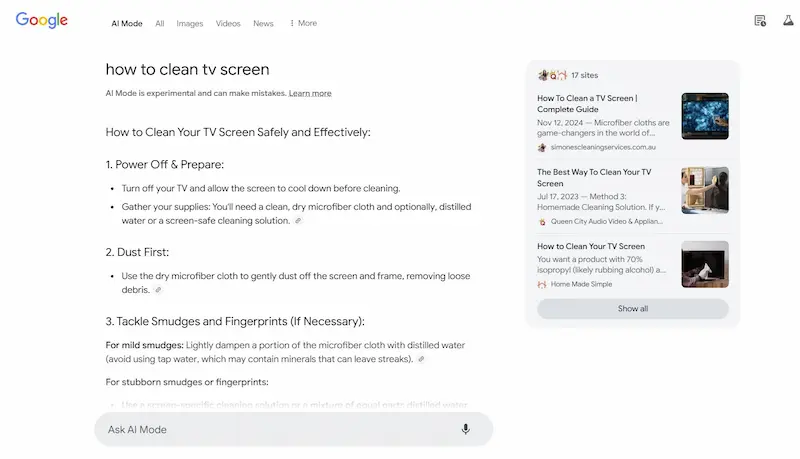
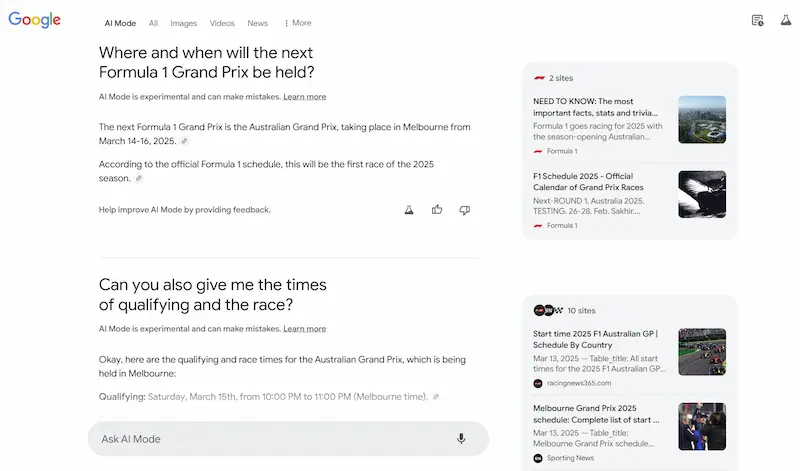
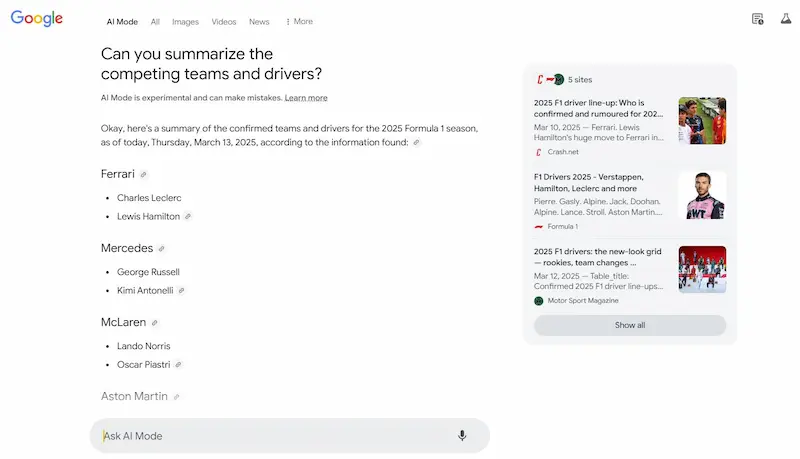
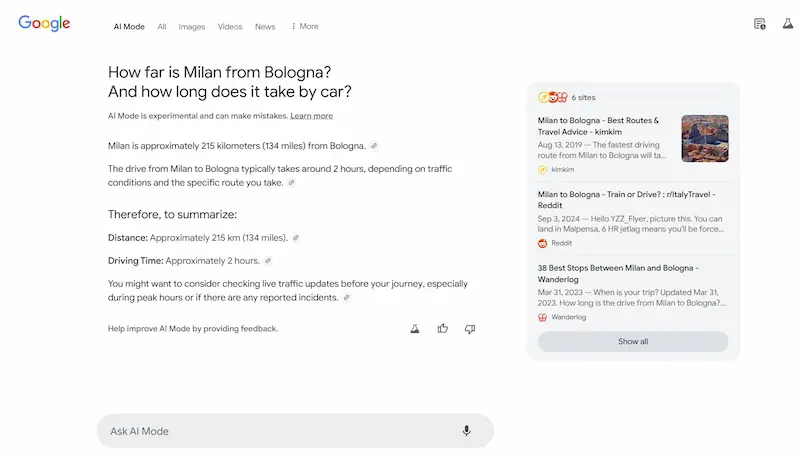
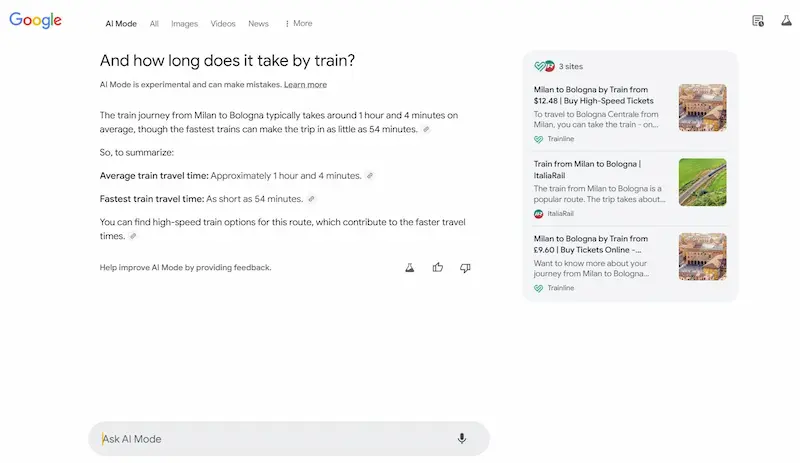
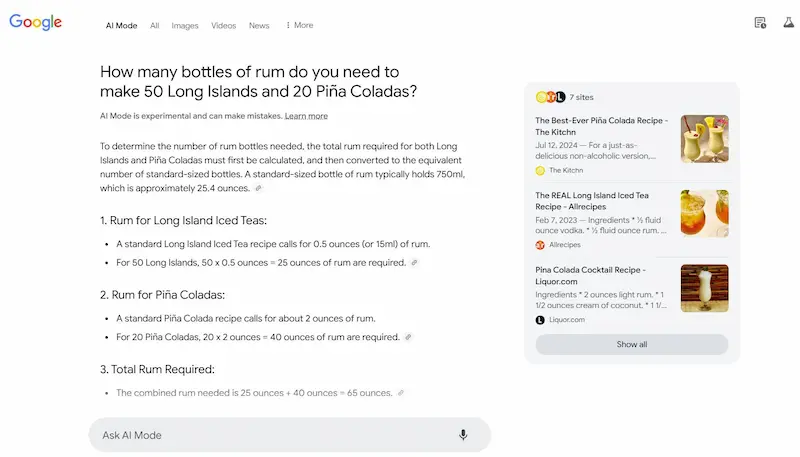
Test di AI Mode di Google
Molti affermano che sarà poco visibile, essendo una nuova Tab nei risultati di ricerca.. ma gli utenti che vorranno quell'esperienza (una risposta strutturata che distilla i risultati) andranno direttamente nella sezione AI Mode.
Con questa nuova funzionalità, Google porta il suo LLM e il "reasoning" nel motore di ricerca.. e lo porterà in molti altri touch point che derivano dal suo ecosistema (app, widget su Android, ecc.).
Oltre all'esperienza consolidata nel campo della ricerca online, mette a disposizione dell'AI un contesto arricchito da un archivio di dati strutturati e funzionalità che nessun altro (oggi) ha a disposizione.
AI Mode è scarsa nelle ricerche transazionali? Sì, ma non è progettato per quel tipo di query. Non a caso, le altre Tab rimangono al loro posto.
Gli AI Agent di OpenAI
OpenAI ha presentato nuovi strumenti dedicati allo sviluppo di AI Agents personalizzati e sistemi multi agente.
Come dicevamo all'AI Festival: avremo framework che ci permetteranno di sviluppare i nostri agenti, e contemporaneamente le piattaforme ci metteranno a disposizione agent per ogni funzionalità (es. Operator e Deep Research).
OpenAI, quindi, ha introdotto una serie di strumenti chiave:
Responses API
L’API più avanzata per la costruzione di agenti, che combina la semplicità della Chat Completions API con le capacità di utilizzo degli strumenti dell’Assistants API. Con una singola chiamata, gli sviluppatori possono orchestrare più strumenti e modelli, rendendo gli agenti più intelligenti e operativi.
Strumenti integrati nella Responses API:
- Web Search Tool – Risultati aggiornati dal web con citazioni verificate, rendendo gli agenti più affidabili per ricerca, assistenti di shopping e informazioni in tempo reale.
- File Search Tool – Recupero rapido di informazioni da documenti, con metadati avanzati e ranking ottimizzato per scenari come supporto clienti e analisi legale.
- Computer Use Tool – Automazione di interfacce grafiche e software legacy, permettendo agli agenti di eseguire azioni reali in ambienti privi di API.
Agents SDK (l'evoluzione di Swarm)
Un framework open-source per orchestrare agenti multipli e gestire flussi di lavoro complessi. Gli sviluppatori possono ora creare agenti che collaborano tra loro con handoff intelligenti, tracciamento avanzato e guardrail di sicurezza integrati.




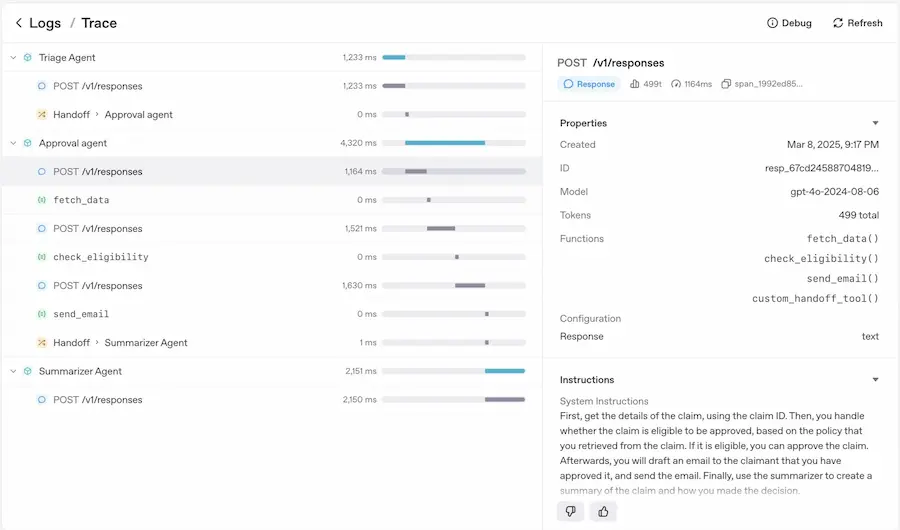
Gli AI Agent di OpenAI: Responses API e Agents SDK
La progettazione è molto simile a AutoGen 0.4, anche se quest'ultimo rimane più evoluto, per ora.
Gli agenti AI non si limitano più a rispondere a domande, ma ora possono agire autonomamente, completando compiti complessi con maggiore efficienza. E nel prossimo futuro, modelli sempre più potenti andranno ad alimentare agenti sempre più autonomi.
Gemini Robotics
Nel mio intervento all'AI Festival ho raccontato di quanto il passaggio dall'AI agentica all'AI fisica non sia così lontano come potremmo immaginare.
Google ha presentato Gemini Robotics, e, come titolo descrittivo ha usato "Gemini for the Physical".
Esempi di utilizzo di Gemini Robotics
Siamo abituati a pensare agli agenti come sistemi confinati nel mondo digitale, ma i progressi dei modelli in termini di multimodalità rendono il passaggio al mondo fisico una questione di "attuatori diversi".
Gemini Robotics, infatti, è un modello basato su Gemini 2.0 (lo stesso che usiamo nella chat!) con l'aggiunta di "azioni fisiche" come tipologia di output allo scopo di controllare direttamente i robot.
Quindi il modello, allo stesso modo con il quale produce output digitali, può generare direttamente azioni nel mondo reale.
Credo che il passaggio all'AI fisica renderà molto più tangibile per tutti il progresso di questi sistemi, perché traccerà lo switch di pensiero da considerarli "giochini che scrivono testo in una chat" a "robot che ci affiancheranno in qualunque mansione".
Chi si ricorda il meme..
"Hey ChatGPT, finish this building.."
Gemma 3: un test
Ho provato Gemma3 27B, il nuovo modello open di Google, che sembra essere uno dei migliori di questa categoria.
Sinceramente, sono rimasto molto colpito dai test, soprattutto perché ho usato prompt strutturati, contesti lunghi, e con precise istruzioni.
Il modello è anche multimodale, supporta contesti fino a 128k token, e output in formati strutturati (JSON, XML e markdown).
Nella LLM Chatbot Arena Leaderboard è secondo solo a DeepSeek tra gli open, ma con dimensioni estremamente inferiori.
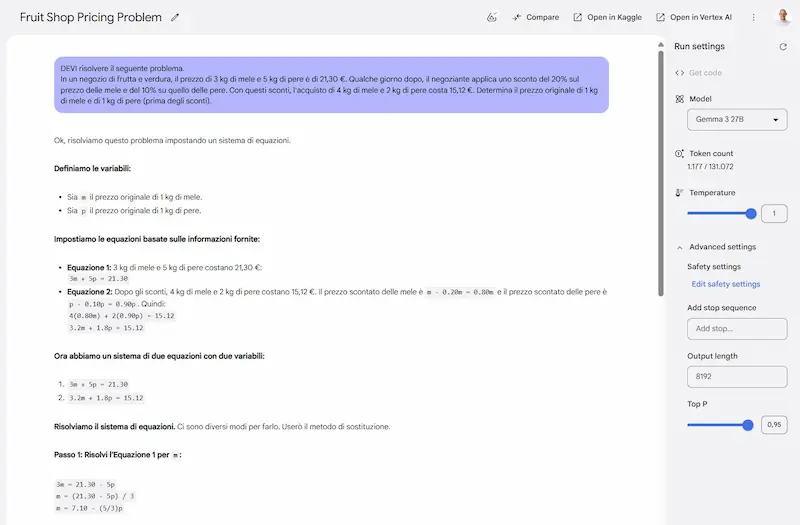
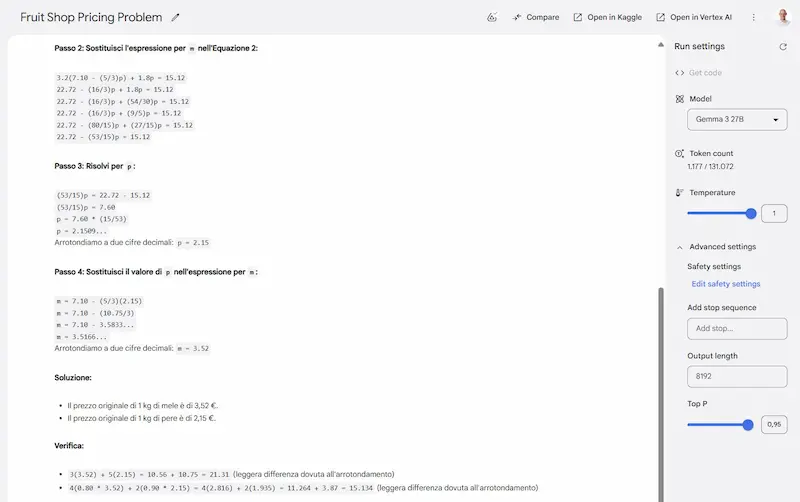
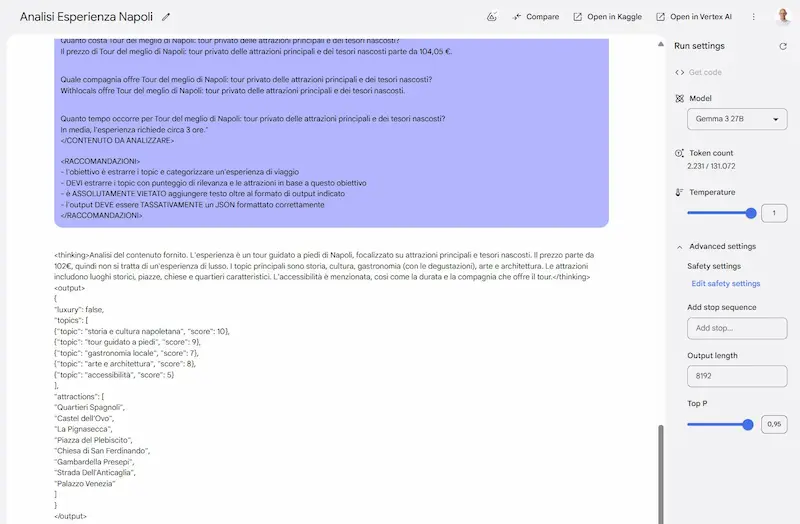
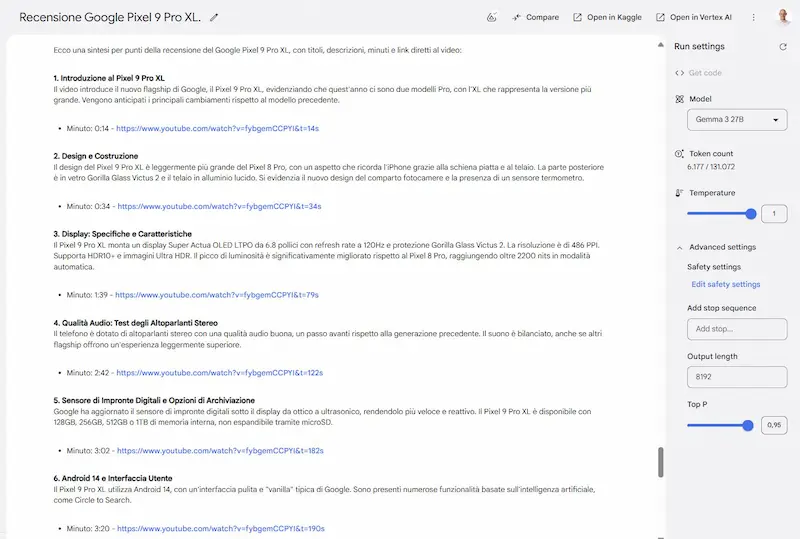
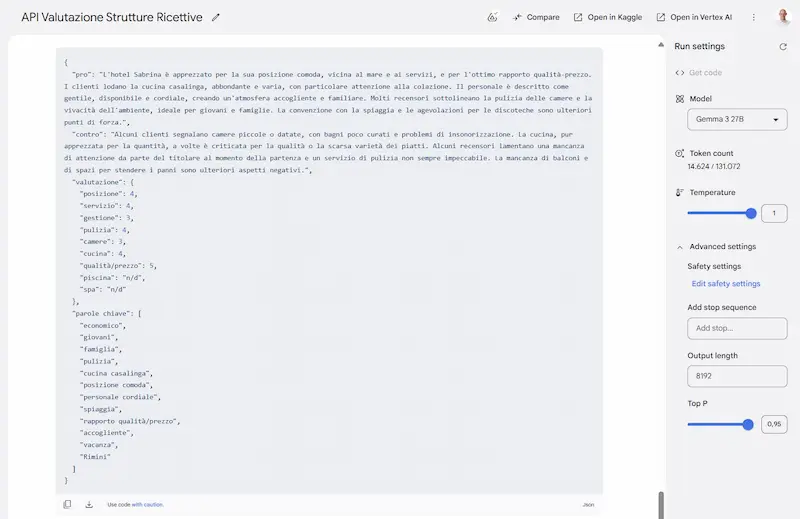
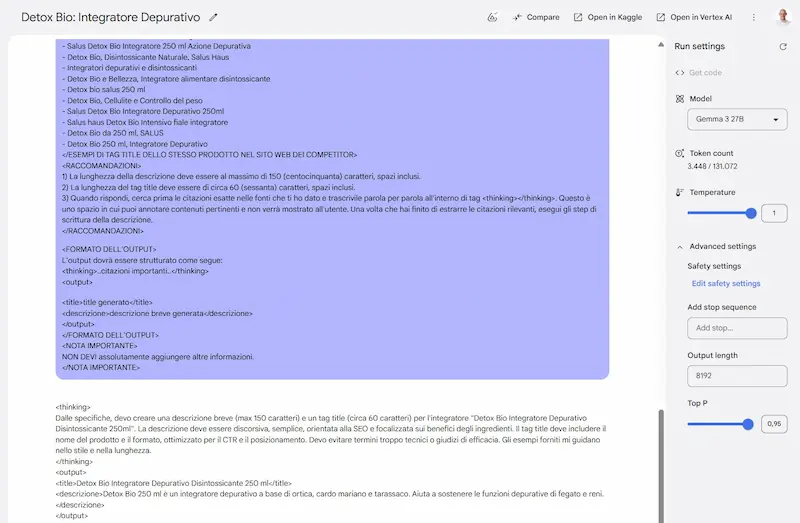
Alcuni test con Gemma 3 di Google
Un'altra dimostrazione di come modelli piccoli, e facilmente usabili anche in locale (è già a disposizione anche su Ollama), possano raggiungere ottime performance su diversi task.
Quando introdurranno meccanismi di reasoning anche su questi modelli (vedi QwQ-32B di Qwen), il potenziale aumenterà di moltissimo.
Canvas su Gemini
Google continua ad aggiungere funzionalità all'interfaccia di Gemini: arriva Canvas.
Come avviene per ChatGPT, si tratta di un sistema che trasforma la chat in un editor interattivo per testo e codice, con la possibilità di modificare gli output manualmente o via prompt (anche contestuali, selezionando blocchi di contenuto).
Tra le funzionalità troviamo i suggerimenti di modifiche, la variazione della lunghezza e del tono. Per il codice, è possibile visualizzare l'anteprima delle applicazioni e la console.
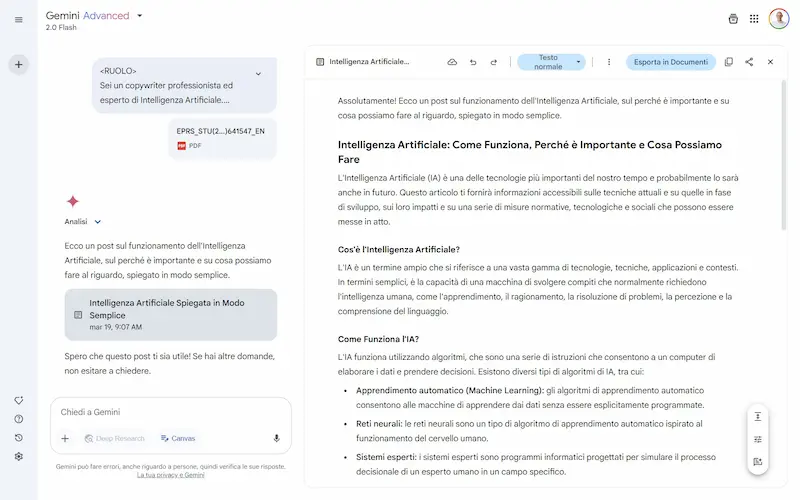
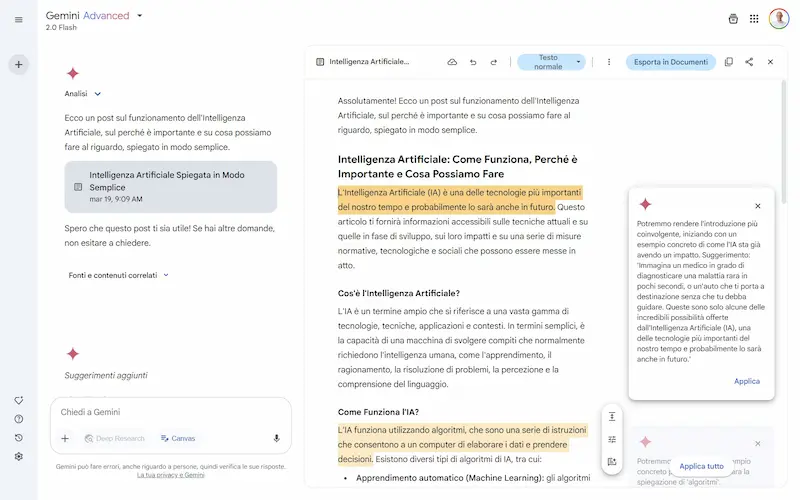
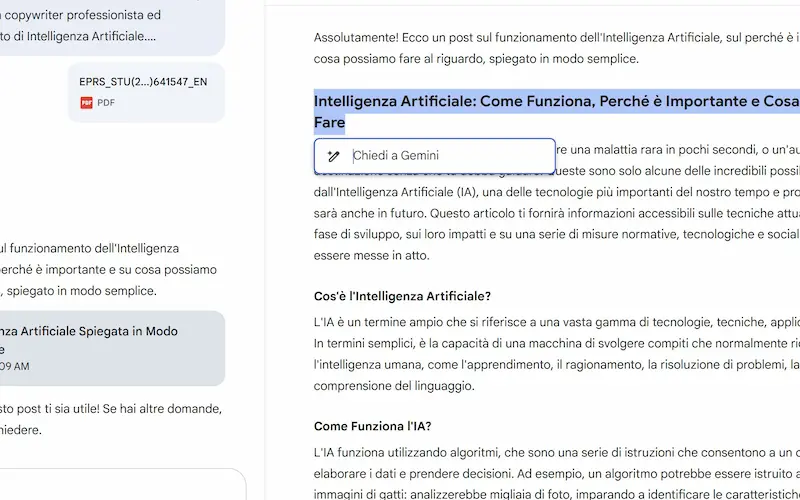
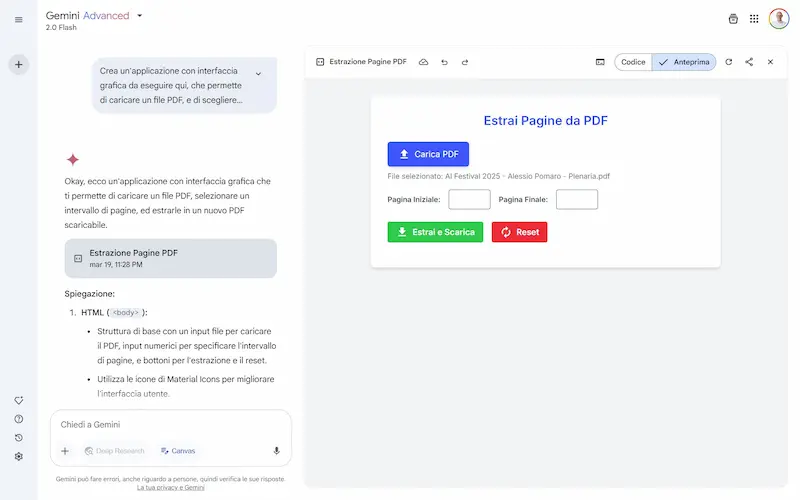
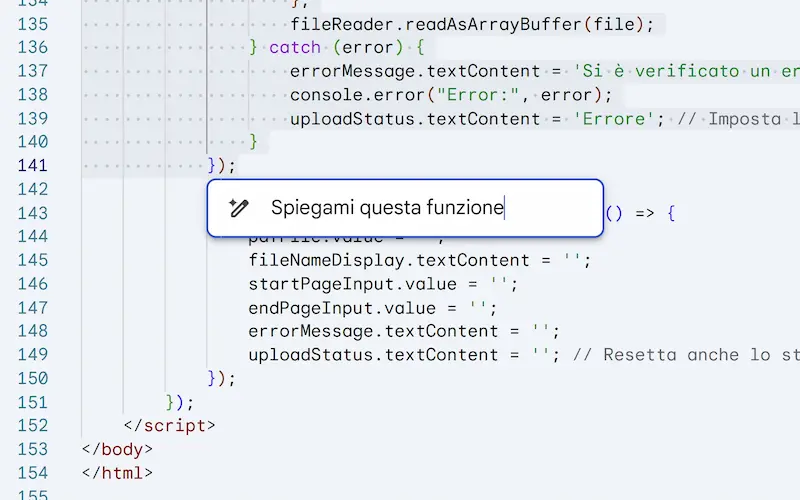
Canvas su Gemini
Comodo il passaggio diretto a Drive e la nuova sidebar che mostra i documenti condivisi nella chat.
Google continua a crescere: il cambio di marcia è evidente.
Un AI Data Science Agent su Google Colab
Google ha integrato su Colab un AI Data Science Agent basato su Gemini.
Come funziona?
È possibile caricare su Colab un dataset, e usare un prompt per descrivere le operazioni da svolgere. L'agente crea autonomamente un piano d'azione che può essere raffinato attraverso altre istruzioni successive. Una volta approvato, Gemini sviluppa il codice Python nel notebook seguendo i task del piano, e lo esegue step by step, fino ad arrivare al risultato.
Ad ogni output dei blocchi usa un sistema di reasoning per valutarlo e agire di conseguenza (es. per risolvere eventuali errori e installare librerie necessarie).
Un AI Data Science Agent su Google Colab: test
Di certo, un sistema integrato in un ambiente come Colab è molto più interessante dell'uso di un LLM su una chat. La fase di prototipazione si semplifica, e il codice rimane in un notebook sul quale lavorare anche manualmente.
Le novità di Qwen
Il team di Qwen ha presentato QwQ-32B, che porta il reasoning dei modelli a un nuovo livello attraverso il Reinforcement Learning (RL).
Con 32 miliardi di parametri, riesce a competere con modelli molto più grandi, come DeepSeek R1 (671B) o Llama 70B.
Un test di QwQ-32B nella chat di Qwen
All'AI Festival ho parlato di scala dei modelli, di efficienza e architetture. Questo modello dimostra proprio come, invece di puntare solo sulla scala, sfruttando il RL in modo strategico sia possibile migliorare il reasoning e le performance.
Modelli più piccoli e ben addestrati, quindi, possono competere con giganti costosi da addestrare e usare.
Il team di Qwen, inoltre, ha lanciato QVQ-Max, un modello che unisce "vision" e "reasoning".
Riesce a comprendere e analizzare immagini e video, può risolvere problemi matematici partendo da diagrammi, analizzare sequenze video per prevedere azioni future, trasformare uno schizzo in un’illustrazione completa.
Nell'esempio carico un video, che diventa contesto per il modello insieme al prompt.
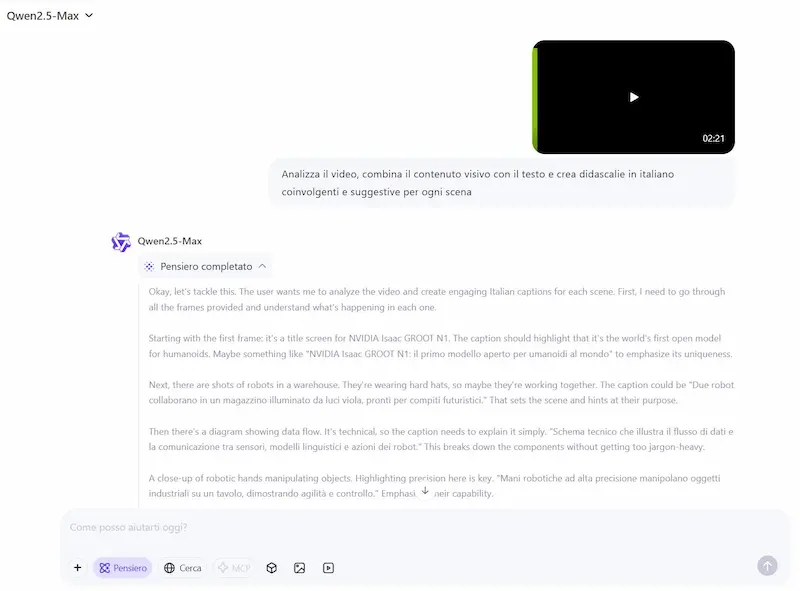
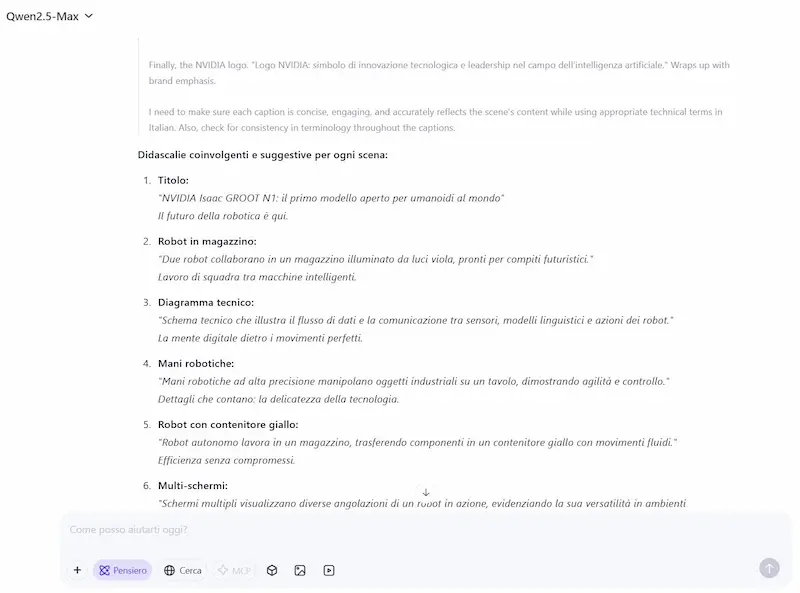
Qwen QvQ-Max nell'elaborazione di un video
Tutti i LLM integreranno questa funzionalità.
DeepSeek V3 open-source
DeepSeek continua a movimentare il mondo dei LLM rilasciando la nuova versione di V3 (v3-0324) open source con licenza MIT, che permette l'uso commerciale gratuito.
Nei benchmark viene confrontato anche con GPT-4.5 e Claude Sonnet 3.7, con risultati notevoli.
È possibile scaricarlo da Hugging Face, dove si trova già anche quantizzato. Oppure può essere usato nella Chat di DeepSeek e via API.

L'ho provato su diversi task.. inutile dire che si tratta di un modello da considerare tra i migliori.
Mistral Small 3.1 24B
Mistral AI ha annunciato il rilascio di Mistral Small 3.1 24B, un nuovo modello open source avanzato.
L'ho provato su task con istruzioni precise e contesti lunghi.
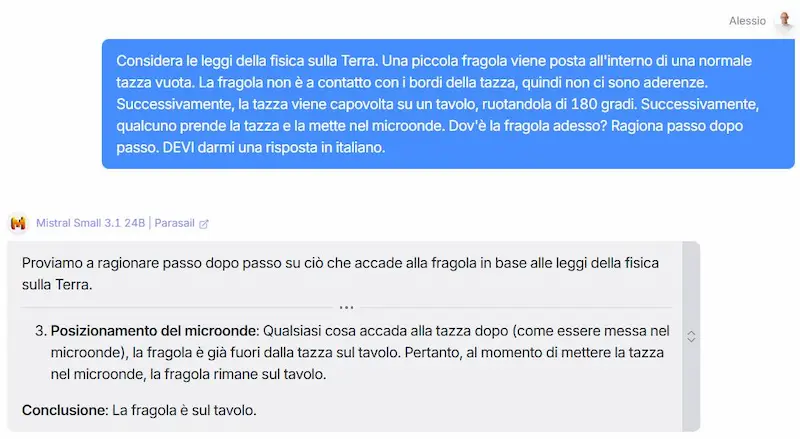

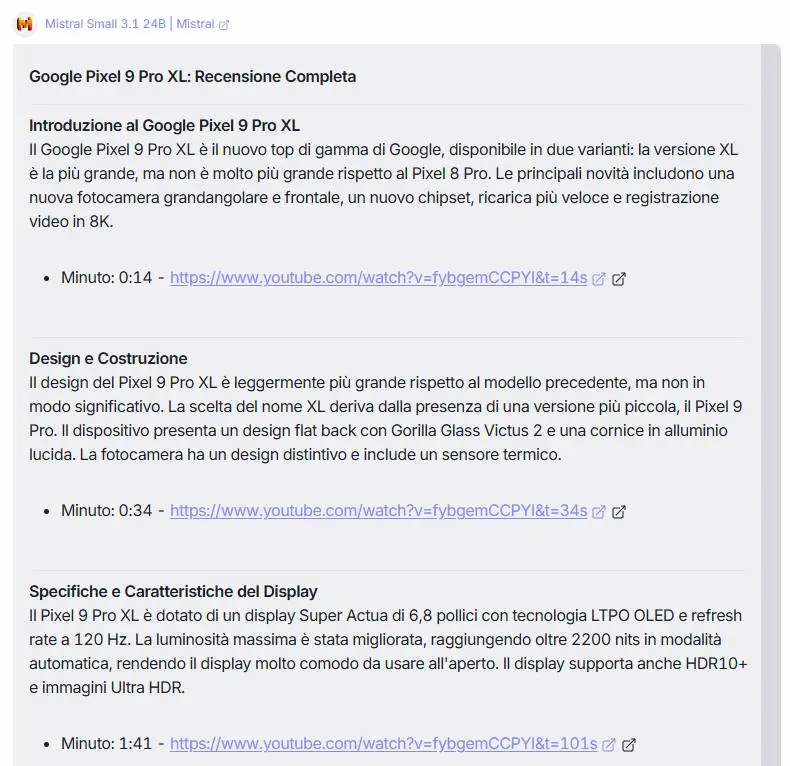
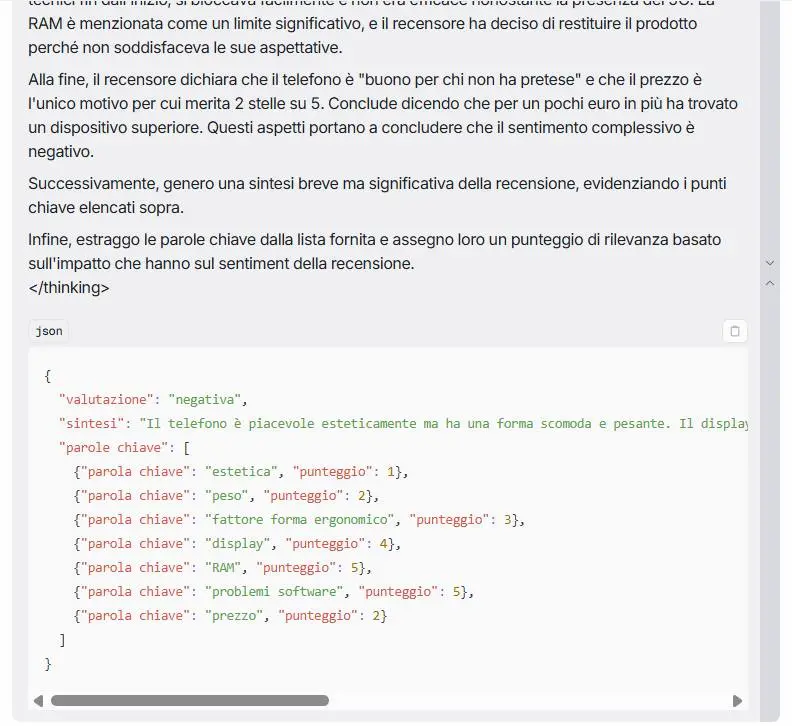
Un test di Mistral Small 3.1 24B
Sono rimasto colpito dagli output e dalla velocità. Questi modelli "piccoli" e open oggi permettono davvero di creare applicazioni di qualità a costi ridotti.
Offre un contesto esteso fino a 128k token, supporto multimodale e multilingua, e supera modelli concorrenti come Gemma 3, GPT-4o mini e Claude 3.5 Haiku.
Manus: un AI Agent "generale"
Manus è un nuovo AI agent "generale" in grado di eseguire compiti attraverso pianificazione e azioni autonome.
Nel video di presentazione vengono fatti diversi esempi nei quali il sistema analizza PDF contenuti in un archivio, sviluppa codice, naviga online attraverso l'interazione multimodale.. il tutto attraverso l'interazione autonoma di un modello con un computer.
La presentazione di Manus
Vederlo in azione è impressionante. Come è impressionante la crescita dei sistemi cinesi evoluti nell'ambito delle applicazioni basate sull'AI.
Isaac GR00T N1 di NVIDIA
NVIDIA ha presentato Isaac GR00T N1, il primo foundation model open e personalizzabile per robot umanoidi, capace di apprendere, ragionare e muoversi con logiche ispirate alla cognizione umana.
Il cuore del modello è una doppia architettura: Sistema 1, rapido e intuitivo, gestisce i movimenti in tempo reale come riflessi; Sistema 2, più lento e deliberativo, interpreta istruzioni e pianifica le azioni.
GR00T N1 è in grado di eseguire compiti comuni (come afferrare, spostare e trasferire oggetti) e operazioni complesse multi-step. Grazie a un’enorme quantità di dati sintetici generati con NVIDIA Omniverse, può essere adattato a diversi robot e scenari, con un post-training minimo. Aziende come 1X, Boston Dynamics, Agility Robotics e altre stanno già sfruttando questo modello per fare crescere la robotica umanoide.
Isaac GR00T N1 di NVIDIA
In collaborazione con Google DeepMind e Disney Research, NVIDIA ha anche annunciato Newton, un motore fisico open-source progettato per ottimizzare l’apprendimento robotico, compatibile con MuJoCo e Isaac Lab. Questo permetterà ai robot di imparare con precisione e velocità senza precedenti.
Per affrontare la scarsità di dati reali, NVIDIA ha lanciato Isaac GR00T Blueprint, un sistema per generare centinaia di migliaia di traiettorie sintetiche da poche dimostrazioni umane.
In 11 ore sono stati prodotti dati equivalenti a 9 mesi di attività, con un miglioramento del 40% nelle prestazioni del modello.
Spunti di riflessione
- GR00T N1 segna un punto di svolta verso robot umanoidi realmente adattivi e autonomi.
- I motori di simulazione diventano il cuore dell’apprendimento robotico.
Le performance di Groq
Le performance di Groq con i modelli open-source di ultima generazione sono impressionanti. Nel video uso Qwen QwQ-32B e DeepSeek distillato su task di logica e matematica, che vengono svolti in pochi secondi a 430 Token/s.
Un test di Groq con Qwen QwQ-32B e DeepSeek
Il potenziale di modelli piccoli e ben addestrati su un hardware adeguato è enorme.
Groq usa processori specifici per accelerare l'inferenza dei LLM: le LPU (Language Processing Unit).
Un'intervista a Dario Amodei
Amodei, in una recente intervista, ha affermato che Claude 3.7 rappresenta uno step evolutivo, ma non abbastanza da giustificare la versione "4".
Stanno lavorando su modelli più grandi e costosi, con sistemi di "reasoning" migliorati, che saranno in grado di gestire autonomamente il tempo di elaborazione.
Intervista a Dario Amodei
Mi sembra esattamente il percorso di OpenAI. Io credo che anche in casa Anthropic si stiano facendo i conti con l'attenuazione dell'incremento delle performance derivante dalla scala dei modelli.
Ad oggi, il "reasoning" è la via per migliorare le prestazioni, ma per veri passi significativi serviranno nuove architetture.
"Stop & Think" di Anthropic
Anthropic ha condiviso un'interessante tecnica di "reasoning" che può essere applicata a qualunque modello (anche in locale).
Mostra come, nei task più complessi, viene aggiunto un tool definito "think" all'agente basato sul LLM.
Cosa fa il tool? Guidato da istruzioni nel system prompt, mette in atto una catena di pensiero, in cui, ad esempio, annota i dati a disposizione, verifica di avere tutto il necessario per dare una risposta e delinea un piano d'azione.
In pratica è un modo per fare "ragionare" il modello durante la generazione, in una sorta di "stop and think".


Esempi di implementazione della tecnica di "Stop & Think"
Di certo, in un'applicazione multi agente, potrebbe esserci un agent dedicato a questi processi. Ma è anche un modo per rendere più "intelligente" ogni agente.
Sono contento del fatto che, nei nostri seminari dell'Accademia condividiamo tecniche simili da molto tempo per migliorare la qualità dell'output.
La gestione dei PDF di OpenAI
OpenAI aggiunge la possibilità di gestire i PDF come input via API per i modelli dotati di "vision".
Il modello estrae il testo e crea un'immagine per ogni pagina dei documenti. Tutto questo viene aggiunto al contesto a disposizione del LLM, permettendo di elaborare le informazioni dei contenuti testuali e visuali.
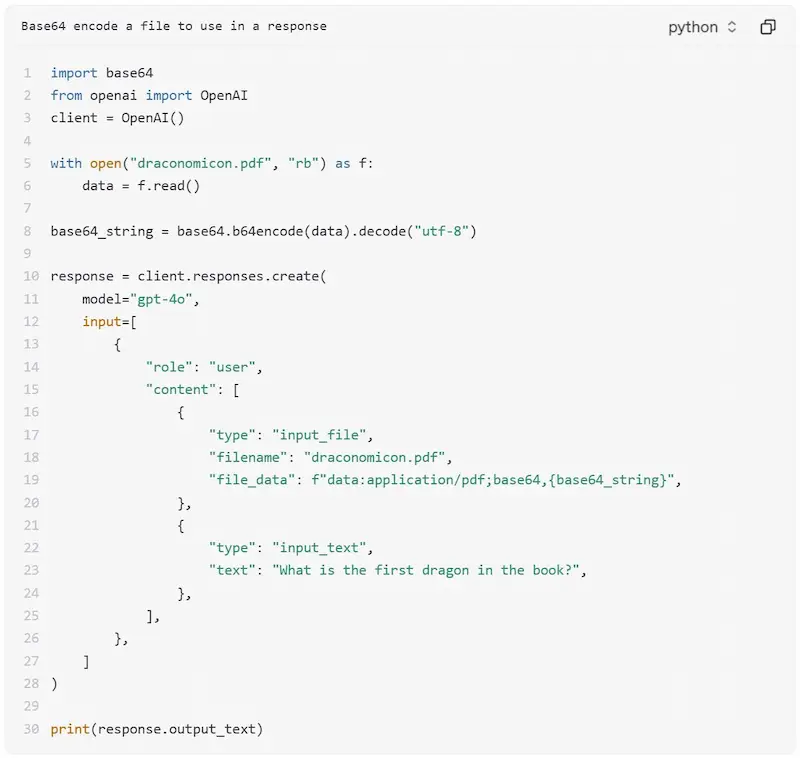
Limiti: i PDF possono essere al massimo di 32MB e di 100 pagine per richiesta.
Web Search su Claude
Finalmente arriva anche su Claude la ricerca per estrarre informazioni in tempo reale che danno contesto al modello.
La Web Search di Claude
Le informazioni del Trust Center di Anthropic sembrano suggerire che il motore utilizzato si quello di Brave.
La funzionalità sarà disponibile prima per gli utenti paid negli USA, ma arriverà per tutti.
Ernie 4.5 di Baidu
La battaglia dei prezzi dei LLM continua.. Baidu ha rilasciato Ernie 4.5 e X1.
Si tratta dell'ultima generazione del loro modello, e della versione con "reasoning".
Ernie X1 ha performance paragonabili a DeepSeek R1, ma con costi dimezzati.
La versione 4.5 costa 0.55$/2.2$ per 1M di token (circa l'1% di GPT-4.5 con performance simili). X1 costa 0.28$/1.1$ per 1M di token.
Ernie 4.5 di Baidu
Si arriverà a costo zero? Secondo me, sì.
Browser Operator di Opera
Opera introduce Browser Operator: un AI Agent dedicato all'automazione del browser integrato direttamente al suo interno.
A differenza di altre soluzioni basate su cloud (es. Operator di OpenAI), lavora direttamente all’interno del browser, sfruttando le risorse locali del dispositivo. Questo non solo garantisce un’esperienza più veloce ed efficiente, ma anche una maggior sicurezza: nessun dato di accesso o informazione sensibile viene inviato a server esterni.
Opera Browser Operator
L’utente rimane sempre in controllo, con la possibilità di intervenire in ogni momento e monitorare l’intero processo.
Può acquistare prodotti online, prenotare eventi o raccogliere informazioni da un sito web per compilare un documento. Il tutto senza dover cliccare manualmente su ogni elemento, grazie alla sua capacità di comprendere la struttura delle pagine web (DOM Tree) e interagire direttamente con esse, senza bisogno di screenshot o registrazioni video.
Mercury: un nuovo LLM che si basa sulla diffusione
Ho provato Mercury, un nuovo LLM di Inception Labs che sfrutta un nuovo metodo per generare l'output. È impressionante.
Si basa sul concetto di diffusione (dLLM), come i modelli di generazione delle immagini, ma applicato al testo: invece di costruire una frase un token alla volta, la raffina progressivamente, rendendo la generazione più veloce e precisa.
Risultato? Mercury è fino a 10 volte più veloce rispetto ai modelli autoregressivi e raggiunge oltre 1k token/sec su GPU standard, senza bisogno di hardware speciale. Mercury Coder genera interi blocchi in pochi passaggi e supera modelli come GPT-4o Mini e Claude 3.5 Haiku in diversi benchmark.
Cosa lo rende speciale
- Generazione parallela invece che sequenziale.
- Maggiore accuratezza e capacità di correzione degli errori.
- Perfetto per RAG, agenti autonomi e tool avanzati.
Project Starlight: l'ottimizzazione video attraverso l'AI
Topaz Labs presenta Project Starlight, un sistema basato su un modello di diffusione in grado di trasformare video a bassa risoluzione e degradati in qualità HD. Secondo quanto riportato, il modello raggiunge la piena coerenza temporale, garantendo un movimento fluido da un fotogramma all'altro.
Un test di Project Starlight (Topaz Labs)
L'ho provato con due vecchi video.. davvero notevole!
I LLM nell'attività di OCR
Come se la cavano i LLM usati per l'attività di OCR (Optical Character Recognition)?
Ho ottenuto i migliori risultati con Gemini 2.0 Pro e LlamaParse.
Nel video si vede un esempio di elaborazione di una scheda tecnica in PDF, che viene trasformata in un dato strutturato.
Alcuni esempi di OCR attraverso i LLM
Con questa accuratezza, i sistemi RAG possono diventare performanti anche su documenti complessi.
DeepGEMM di DeepSeek
DeepSeek continua a innovare per rendere più efficienti il training e l’inferenza dei LLM.
Con DeepGEMM ha rilasciato una libreria ottimizzata per accelerare le moltiplicazioni di matrici in FP8 sulle GPU NVIDIA Hopper.
Perché è importante?
Le reti neurali usano enormi quantità di moltiplicazioni di matrici per elaborare i dati. DeepGEMM rende questi calcoli più veloci ed efficienti, riducendo il tempo e il costo computazionale del training e dell’inferenza dei modelli di intelligenza artificiale.
Un esempio pratico. Immagina un modello AI che genera testo o riconosce immagini. Con DeepGEMM, il modello può rispondere più rapidamente e consumare meno energia, migliorando l’esperienza degli utenti e abbassando i costi per le aziende.
Un passo avanti per l’AI open-source!
L'efficientamento dell'inferenza di DeepSeek
DeepSeek rivela il suo metodo per efficientare l'inferenza dei suoi modelli.
Per massimizzare velocità e prestazioni, il sistema DeepSeek-V3/R1 utilizza Expert Parallelism (EP), una tecnica che distribuisce il carico di lavoro tra più GPU, ottimizzando sia il throughput che la latenza.
Il modello lavora in due fasi: prefill (pre-caricamento delle informazioni) e decode (generazione della risposta), sfruttando strategie avanzate per sovrapporre calcolo e comunicazione, evitando tempi morti.
Per garantire un equilibrio tra le GPU, il sistema implementa meccanismi di bilanciamento del carico, prevenendo rallentamenti dovuti a sovraccarichi su singole unità.
DeepSeek-V3/R1 è operativo su GPU H800, con una capacità di elaborare oltre 608 miliardi di token al giorno, generando 168 miliardi di token in output. Il costo giornaliero dell’infrastruttura è stimato in 87k dollari, mentre il potenziale guadagno massimo teorico potrebbe superare i 500k dollari.
Evo 2, un modello di AI per la biologia
L'Arc Institute, in collaborazione con NVIDIA e un gruppo di ricercatori di Stanford, UC Berkeley e UC San Francisco, ha sviluppato Evo 2, il più grande modello di AI dedicato alla biologia.
Evo 2 è un modello generativo di nuova generazione in grado di leggere, scrivere e progettare il codice genetico su scala genomica. Addestrato su 9,3 trilioni di nucleotidi provenienti da oltre 128k genomi, può individuare mutazioni patogene, generare nuove sequenze di DNA coerenti con la natura e supportare la ricerca in genetica, medicina e biotecnologie.
A differenza dei tradizionali LLM, sfrutta StripedHyena 2, un'architettura ibrida convoluzionale ottimizzata per analizzare fino a 1 milione di nucleotidi contemporaneamente, superando i limiti dei modelli precedenti. Questo gli permette di riconoscere strutture genetiche complesse, prevedere l’effetto delle mutazioni e persino controllare la regolazione genica a livello epigenetico.
Il sistema è open source, e rappresenta un nuovo paradigma per la biologia computazionale, offrendo strumenti senza precedenti per la ricerca e l'ingegneria genetica.
Queste sono le direzioni che fanno comprendere meglio perché è fondamentale portare avanti il percorso sul miglioramento dell'AI, unendo le forze e condividendo esperienze.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂