Generative AI: novità e riflessioni - #2 / 2025
xAI ha lanciato Grok 3, Anthropic Claude 3.7 Sonnet, e OpenAI GPT-4.5: il panorama dei LLM si amplia, mentre il mondo open source cresce, con DeepSeek che continua a rilasciare sistemi di efficientamento. Gli AI Agent diventano sempre più concreti, con corsi e documentazione.

Buon aggiornamento, e buone riflessioni..
Un corso gratuito sugli AI Agents
Microsoft ha rilasciato un corso gratuito dedicato agli AI Agents.
Un percorso in 10 lezioni che parte dalla comprensione del concetto di agente fino allo sviluppo e alla produzione.

Un corso gratuito sugli AI Agents
Include anche esempi di implementazione di workflow multi-agent usando Autogen.
È un contributo davvero interessante. Insieme al corso "Generative AI for beginners" lo terrei tra le risorse da consultare di casa Microsoft.
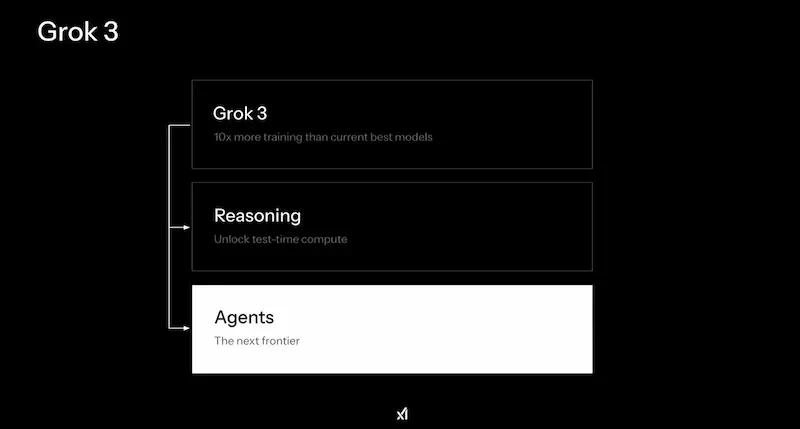
Grok 3 di xAI
Il team di xAI ha presentato Grok 3, e ha annunciato che renderà open source Grok 2 una volta che il 3 sarà "maturo".
Il modello è in due varianti (standard e mini) per bilanciare velocità e accuratezza, e ha la componente di "reasoning", simile a quella di o3, di Gemini e DeepSeek. La modalità "Big Brain", invece, è una versione ancora più potente, che usa più potenza di calcolo per task complessi.
Non potevano mancare gli Agenti, con l'integrazione dell'ormai immancabile "Deep Search", che recupera informazioni su X e online per creare report dettagliati.
Secondo il team, i modelli superano quelli di OpenAI su diversi benchmark.
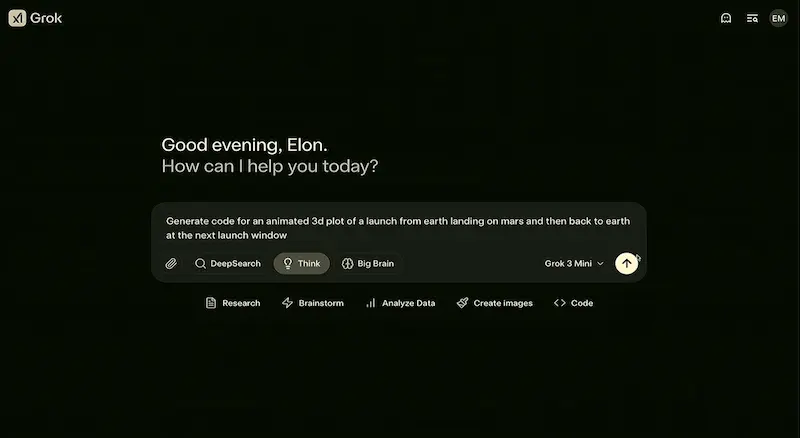
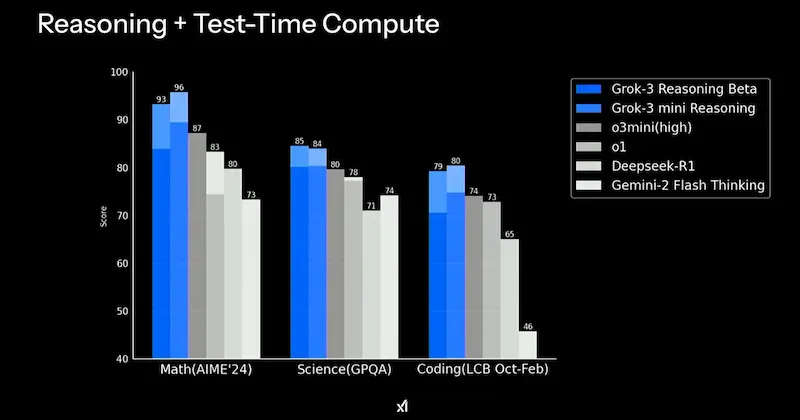
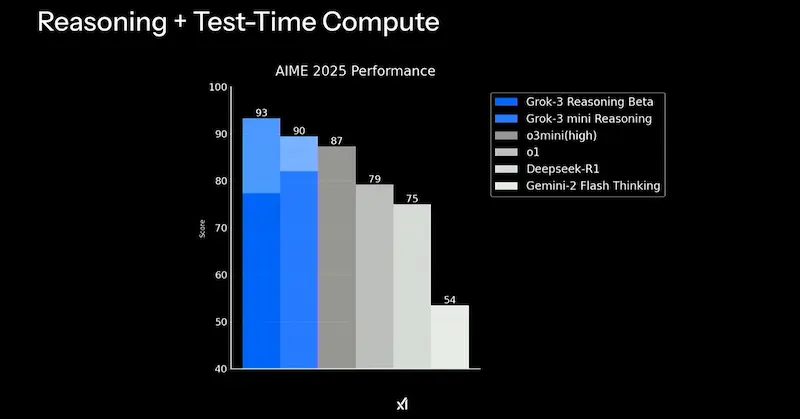
Grok 3 di xAI
Ormai il livello generale delle performance dei LLM è elevato, mentre il riferimento continua a rimanere GPT-4x (una costante da oltre un anno). I modelli stanno diventando sempre di più una commodity per creare applicazioni ibride (agenti) verticali.
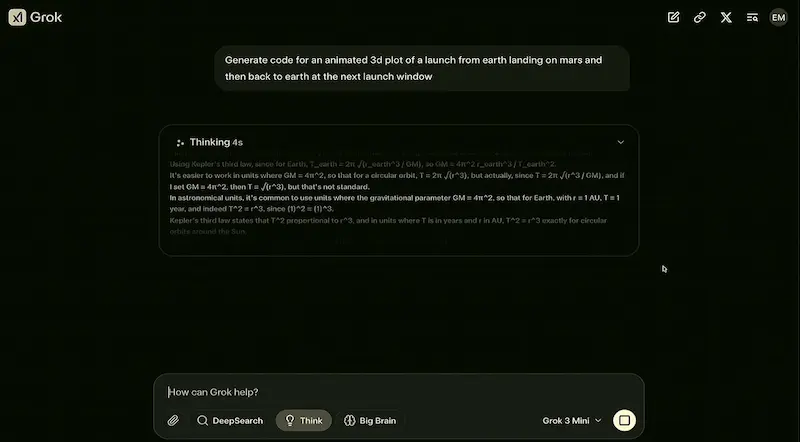
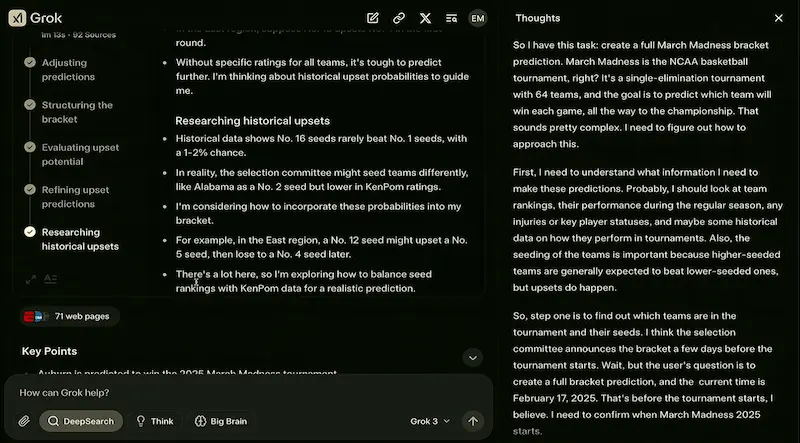
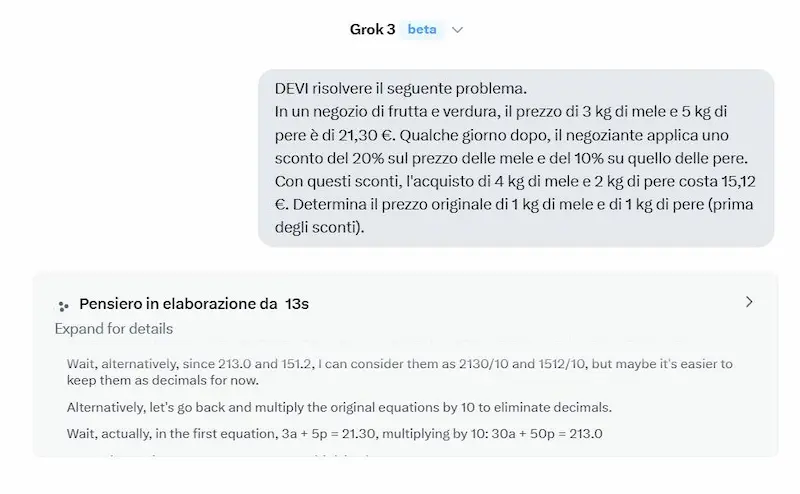
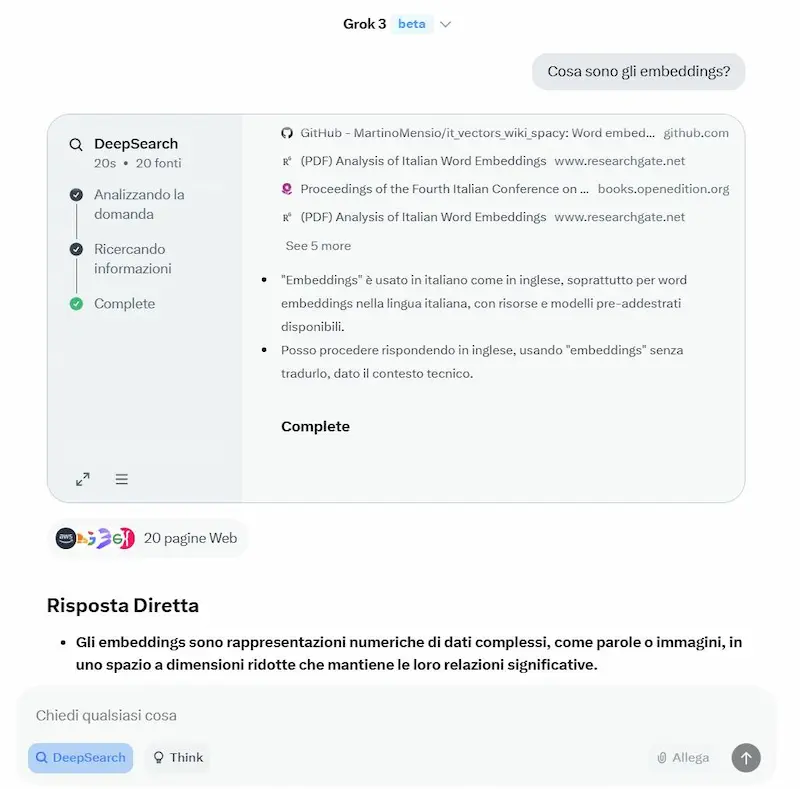
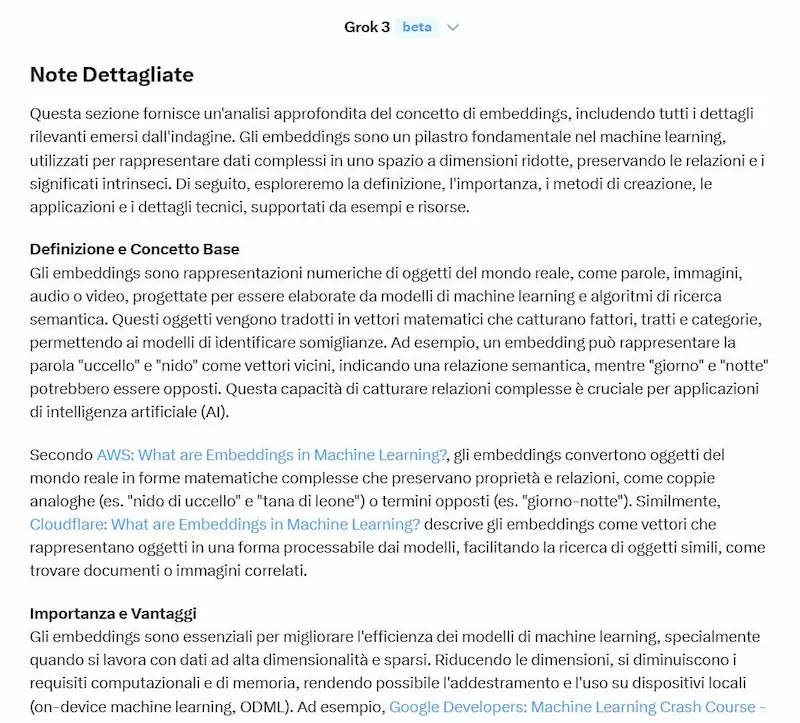
Un test del modello
Ho fatto alcuni test usandolo anche in configurazione di "reasoning", Deep Search e generazione di immagini.

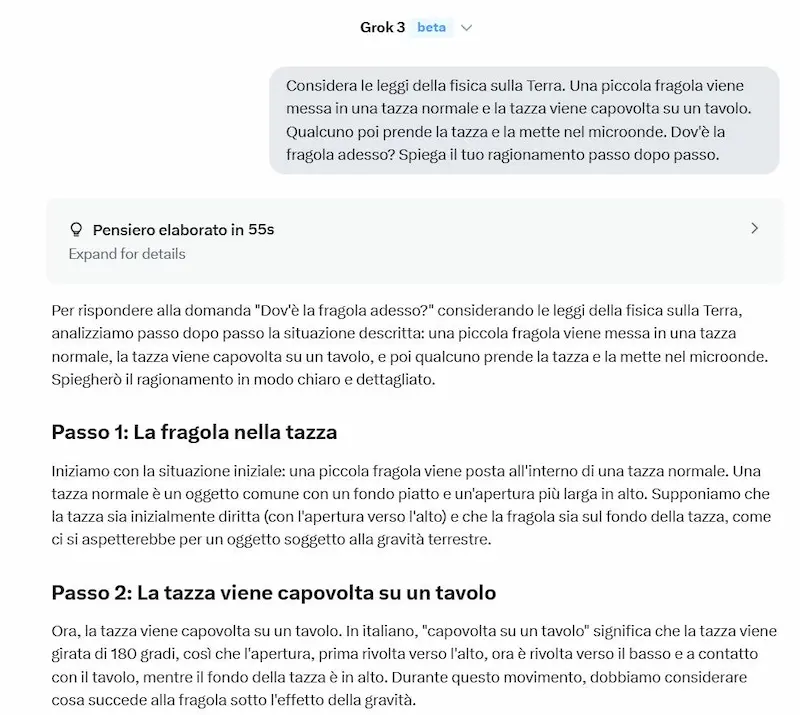
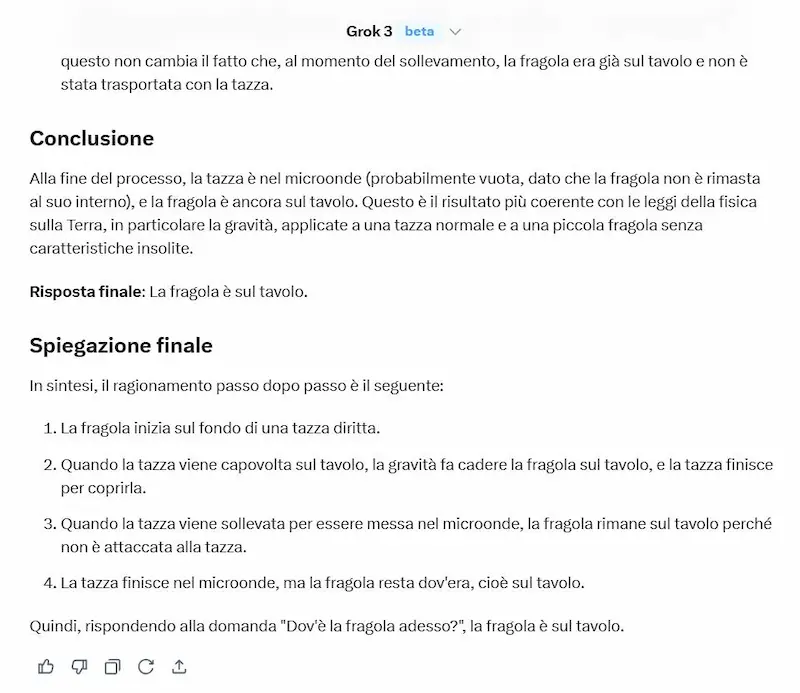
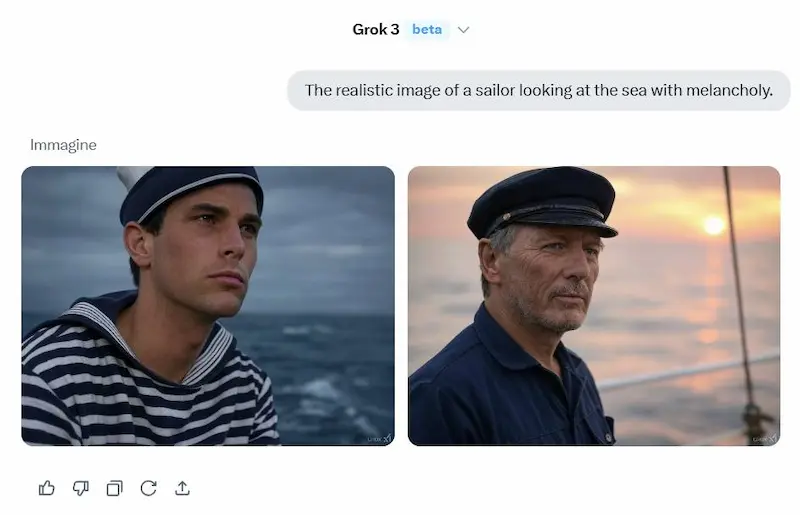

Un test di Grok 3
Il modello è senza dubbio performante, ma ho l'impressione che o3 abbia una marcia in più nel reasoning.
La Deep Search è più veloce di quella di Gemini, ma anche meno approfondita: probabilmente è una scelta. Quella di OpenAI rimane la più dettagliata.
Interessante la suddivisione tra risposta diretta e note dettagliate.
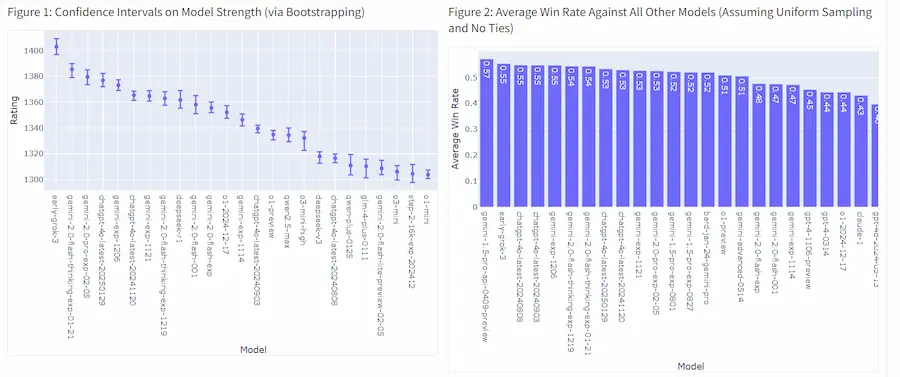
Attualmente il modello è primo nella LLM Chatbot Arena Leaderboard.
Le novità di OpenAI
OpenAI ha fatto diversi rilasci nell'ultimo mese. Vediamo i più importanti.
Il lancio di GPT-4.5
OpenAI annuncia GPT-4.5, ma non ha convinto. Altman non ha partecipato alla presentazione, e ha lasciato un post su X abbastanza "sulla difensiva".
Il modello è ampio, e necessita di molta potenza di calcolo. Per questo, ha API costosissime: x30 (input) e x15 (output) rispetto a GPT-4o, e x3 rispetto a o1..
Mi chiedo in quale caso potrebbe aver senso usarle, considerando che non sembra che ci sia stato un forte balzo evolutivo. Anche perché, altrimenti, l'avrebbero definito GPT-5.
Scrivono, addirittura: "we’re evaluating to continue serving it in the API long-term as we balance supporting current capabilities with building future models".
Sembra quasi un rilascio di risposta ai competitor, utile a riprendere la leadership, in attesa degli sviluppi successivi. Infatti il modello ha raggiunto Grok-3 nella LLM Chatbot Arena Leaderboard.
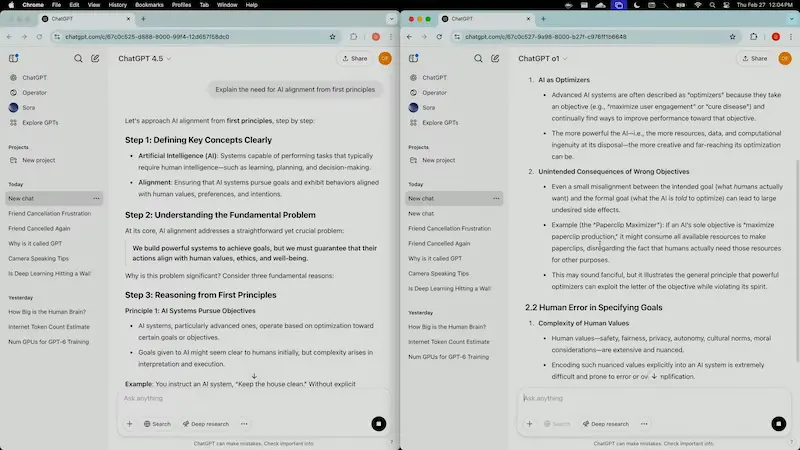
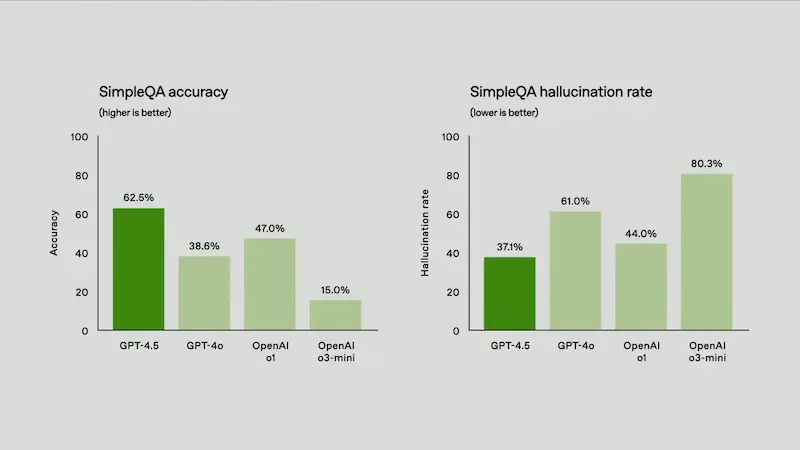
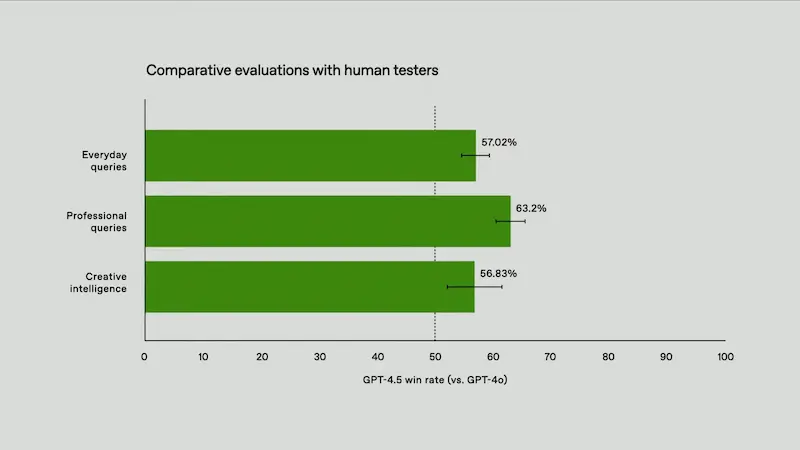

Il lancio di GPT-4.5
Caratteristiche
GPT-4.5 viene descritto come il modello più potente di casa OpenAI. Sarà disponibile per ChatGPT Pro e via API (per gli utenti Plus arriverà in seconda battuta).
Grazie a un apprendimento non supervisionato avanzato, offre migliore comprensione, minori allucinazioni e interazioni più naturali.
- Maggiore accuratezza e affidabilità nelle risposte.
- Interazioni più fluide, empatiche e contestualizzate.
- Eccellenza in scrittura, programmazione e risoluzione di problemi complessi.
- Riduzione significativa degli errori e delle informazioni inesatte.
Il fatto che la "scala" OGGI non sia più una leva di crescita delle performance è sempre più evidente. Questo sembra davvero un rilascio dimostrativo solo per "guardare" (su ChatGPT) ma "non toccare" (via API).
Deep Research disponibile anche per gli utenti Pro
L'agent di Deep Research è stato rilasciato anche per gli utenti Plus.
L'ho provato. Il sistema, inizialmente, fa domande di follow-up se la richiesta è troppo generica, e successivamente fa partire il lavoro di "scoperta".
- Inizia con una ricerca, e man mano che analizza risultati, espande l'approfondimento degli argomenti.
- Mostra sia il flusso di ragionamento, sia la lista delle fonti.
- Lavora in maniera leggermente diversa dall'agent di Google: mentre Gemini crea un piano d'azione sugli argomenti e chiede conferma prima di iniziare, l'agent di OpenAI costruisce il piano in base all'esplorazione.
- Il risultato di OpenAI sembra più curato ed esteso, infatti è anche più lento: la stessa ricerca ha impegnato qualche minuto Gemini e quasi 17 minuti ChatGPT.
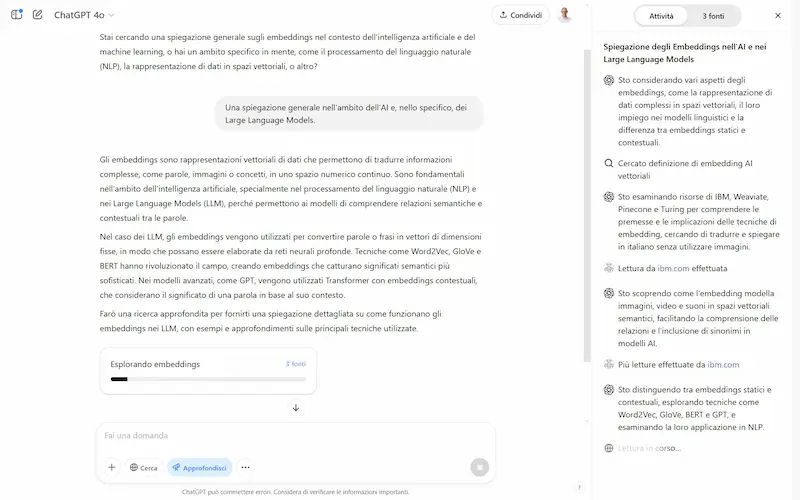
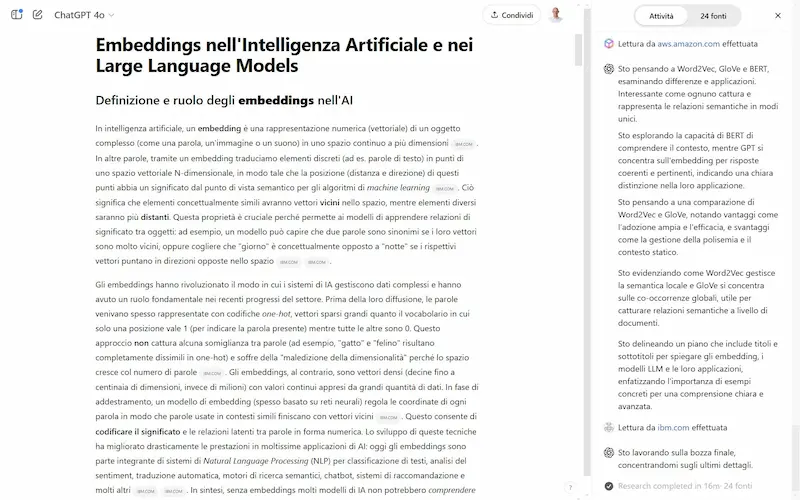
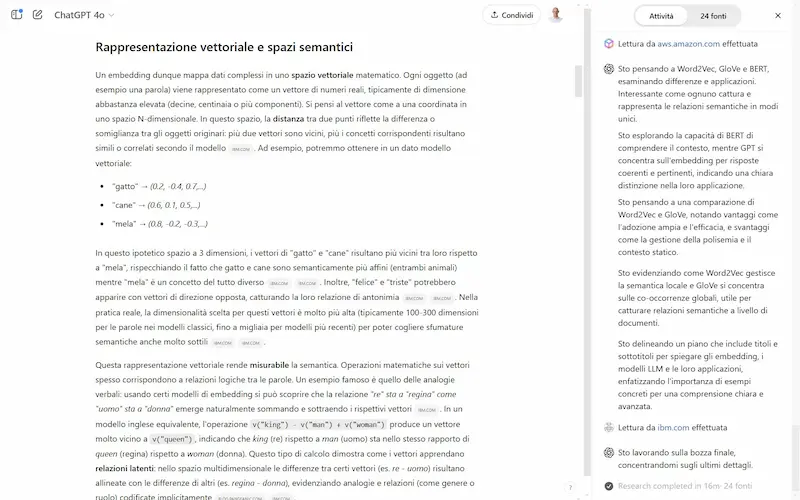
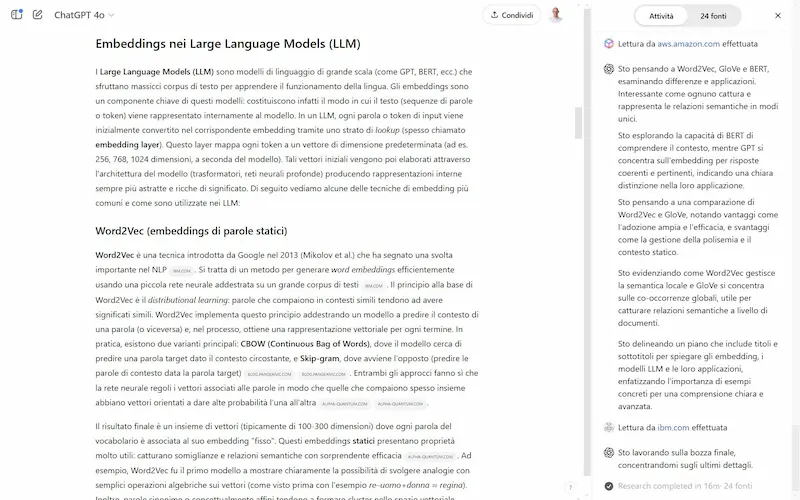
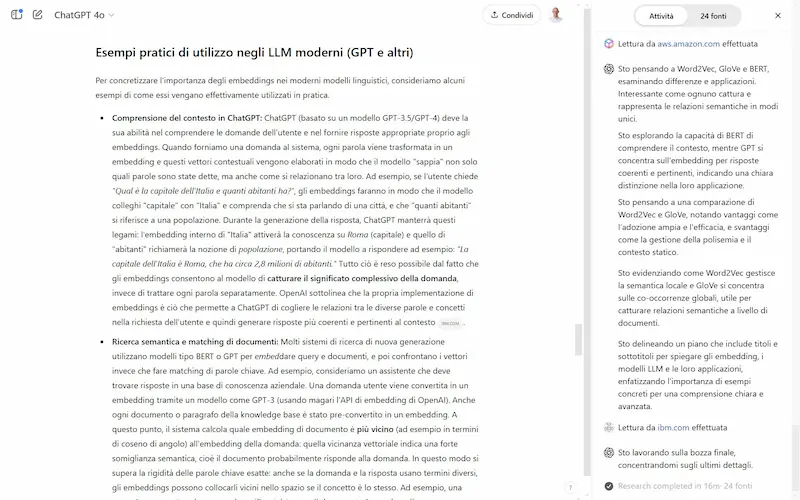
Un test di Deep Research su ChatGPT
È affascinante vedere questi sistemi in esecuzione, e permettono di creare dei report finali che fanno risparmiare grandi quantità di lavoro in fase di analisi.
o1 e o3 ora supportano il caricamento di file e immagini
Un passo in avanti è stato fatto, ora manca Code Interpreter per l'analisi dei dataset.
Nell'esempio, carico un documento tecnico e fornisco istruzioni a ChatGPT per estrarre tutti i dati in modo strutturato.
o3-mini: l'elaborazione di documenti
Con o3, ultimamente, sono riuscito a eseguire operazioni che mi hanno davvero fatto risparmiare molto tempo.
L'interazione con ChatGPT via WhatsApp
Si evolve l'interazione di ChatGPT via WhatsApp, con la possibilità di caricare immagini e interagire attraverso messaggi vocali.

L'interazione con ChatGPT via Whatsapp
Sembra un aggiornamento banale, ma intercetta esattamente le dinamiche delle interazioni tra le persone, rendendo il sistema usabile da chiunque.
Claude 3.7 Sonnet di Anthropic
Anthropic lancia Claude 3.7 Sonnet, con la funzionalità di "reasoning" (nella versione estesa solo per utenti Pro).
Nel post di presentazione viene descritto come un approccio diverso dai competitor: un unico modello che può essere sfruttato con o senza ragionamento avanzato.
Sinceramente, credo che la base sia la stessa anche per i competitor. Grok, ad esempio, funziona allo stesso modo, e anche GPT-5 uniformerà completamente i modelli di OpenAI.
L'ho provato, e chiaramente è molto performante, e, come sempre, lato coding è tra i migliori.


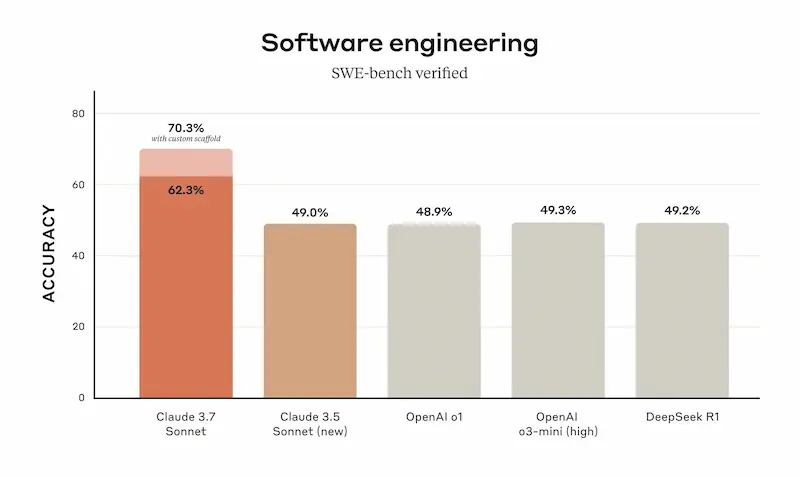
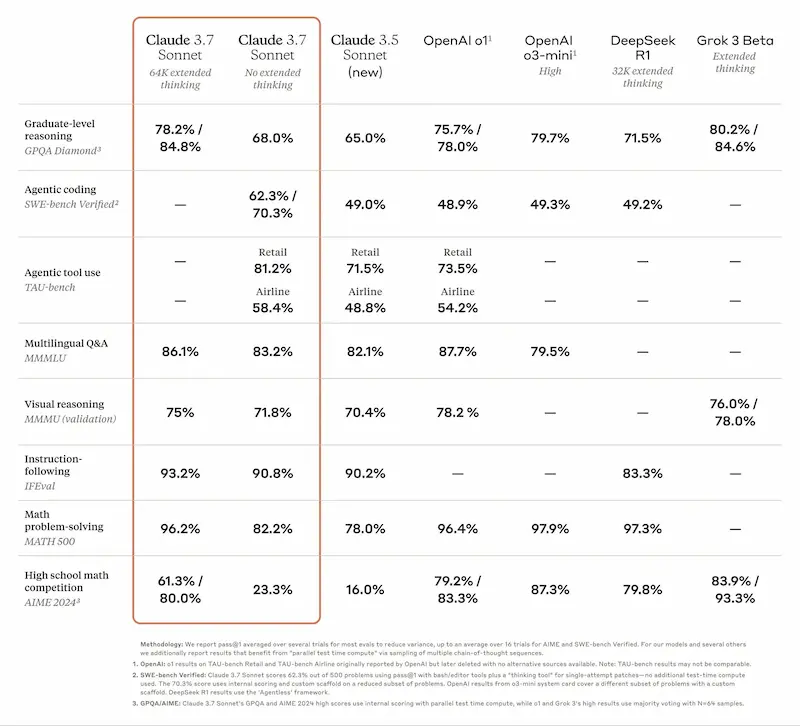
Un test di Claude 3.7 Sonnet
Ormai siamo a un punto di convergenza nelle performance: ogni nuovo modello supera leggermente i competitor, fino a un nuovo rilascio di questi ultimi.
Il modello di "reasoning" di Gemini
Anche in casa Google è arrivato il modello di "reasoning" nella chat di Gemini.
In due versioni: "2.0 Flash Thinking" e "2.0 Flash Thinking with apps". La differenza è che il secondo può accedere anche alla Search, a YouTube e a Maps.
Gemini 2.0 Flash Thinking
Nel video si vedono alcuni test dei due sistemi. È davvero molto interessante l'unione tra la ricerca online e il reasoning.
Tra i nuovi modelli, è a disposizione anche Gemini 2.0 Pro (Experimental).
Tutti questi modelli sono già nelle prime posizioni nella Chatbot Arena LLM Leaderboard.
Ora manca un'integrazione solida in Workspace e il cerchio sarà chiuso.
Gemini Code Assist
Google ha annunciato il rilascio gratuito di Gemini Code Assist, un potente assistente AI per la programmazione basato su Gemini 2.0.
Ora disponibile per tutti gli sviluppatori, supporta tutti i linguaggi di programmazione pubblici e offre suggerimenti avanzati per la scrittura e revisione del codice.
Gemini Code Assist
Rispetto ad altri strumenti gratuiti, offre fino a 180k completamenti di codice al mese.
Integrazione diretta con GitHub per revisioni AI-powered: rileva errori, migliora la qualità del codice e si adatta a linee guida personalizzate.
Compatibile con Visual Studio Code, JetBrains IDEs, Firebase e Android Studio, permette agli sviluppatori di lavorare in modo più efficiente con AI direttamente nei loro ambienti di sviluppo.
La Deep Research di Perplexity
Perplexity introduce diversi sistemi a supporto della ricerca, tra cui "Deep Research".
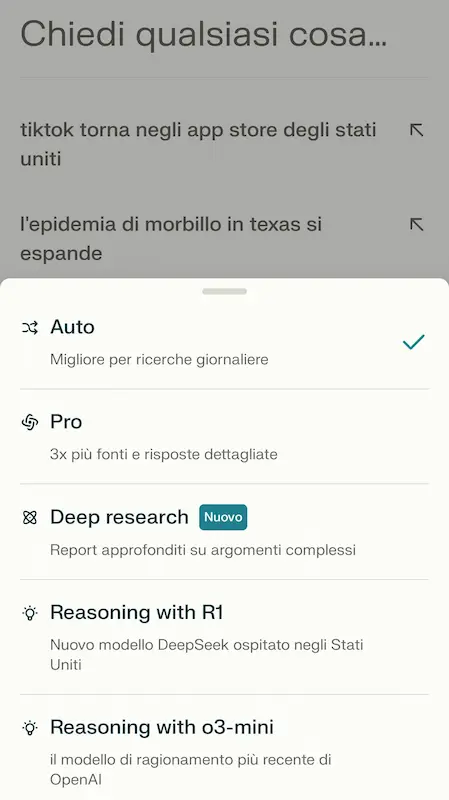




La Deep Research di Perplexity
Il funzionamento è in linea con gli omonimi agenti di Google, OpenAI e con i numerosi progetti open source simili: viene delineato un piano d'azione, avviate le ricerche, e viene restituito un report dettagliato (anche ascoltabile). Le fonti e il materiale multimediale (immagini e video) sono consultabili.
Agenti di questo tipo diventano sempre più integrabili e personalizzabili facilmente.
Quantizzazione dinamica di DeepSeek
La quantizzazione, cioè la tecnica usata per ridurre le dimensioni e il consumo di memoria di un LLM senza perdere troppa precisione, non è un processo standard.
Il team di Unsloth, ad esempio, ha ridotto le dimensioni di DeepSeek R1 dell'80% mantenendo buone performance ed efficienza.
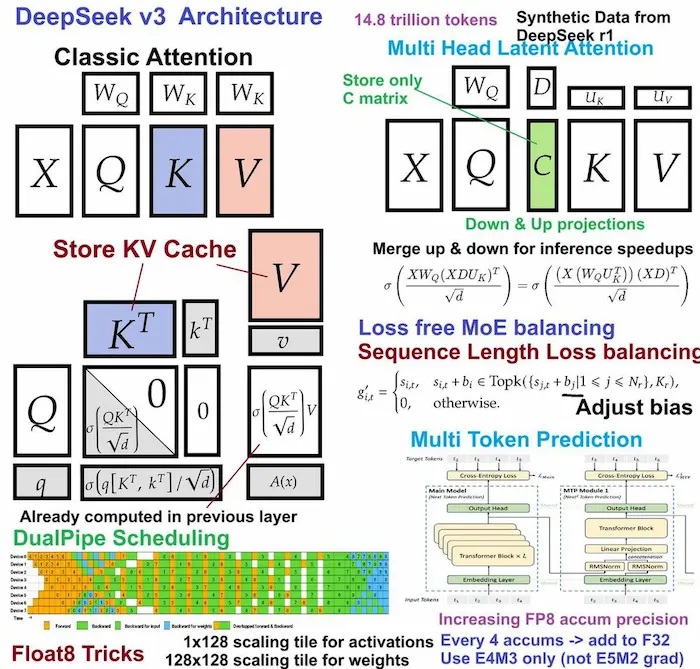
Hanno usato una quantizzazione dinamica mantenendo alcune parti più precise (ad esempio, i primi tre strati densi e alcune proiezioni MoE a 4 o 6 bit), mentre altre vengono ridotte fino a 1.58-bit.
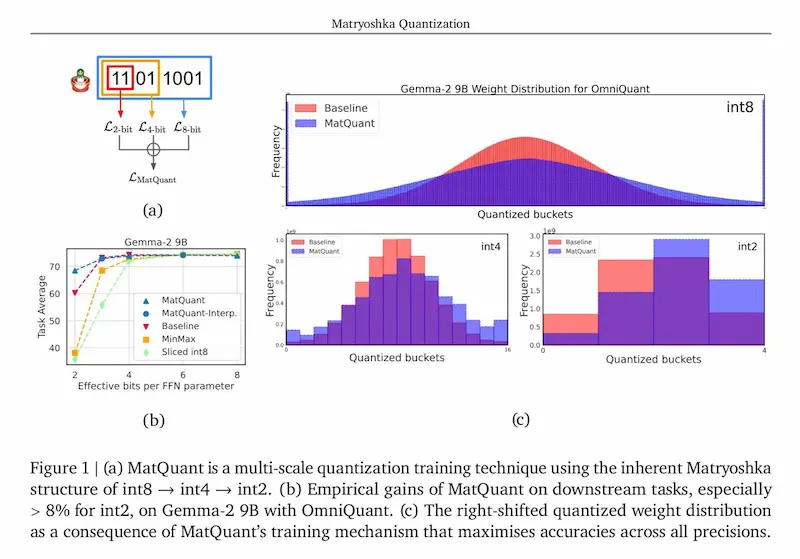
MatQuant di Google DeepMind
Google DeepMind presenta MatQuant: una nuova tecnica di quantizzazione multi-scala che sfrutta la struttura nidificata degli interi (Matryoshka structure) per ottimizzare modelli a diverse precisioni (int8 → int4 → int2) senza sacrificare l'accuratezza.
Alcuni risultati
- Gemma-2 9B (int2) con MatQuant è +8% più accurato rispetto alla quantizzazione tradizionale.
- Mistral 7B (int2) migliora di +6,3%, riducendo la perdita di qualità nei modelli ultra-compressi.
- Performance di int4 e int8 comparabili ai baseline, con maggiore efficienza.
- Interpolazione tra bit-widths (int6, int3) senza ulteriore addestramento.
- Mix'n'Match per combinare diverse precisioni nei layer, ottimizzando costi e latenza.
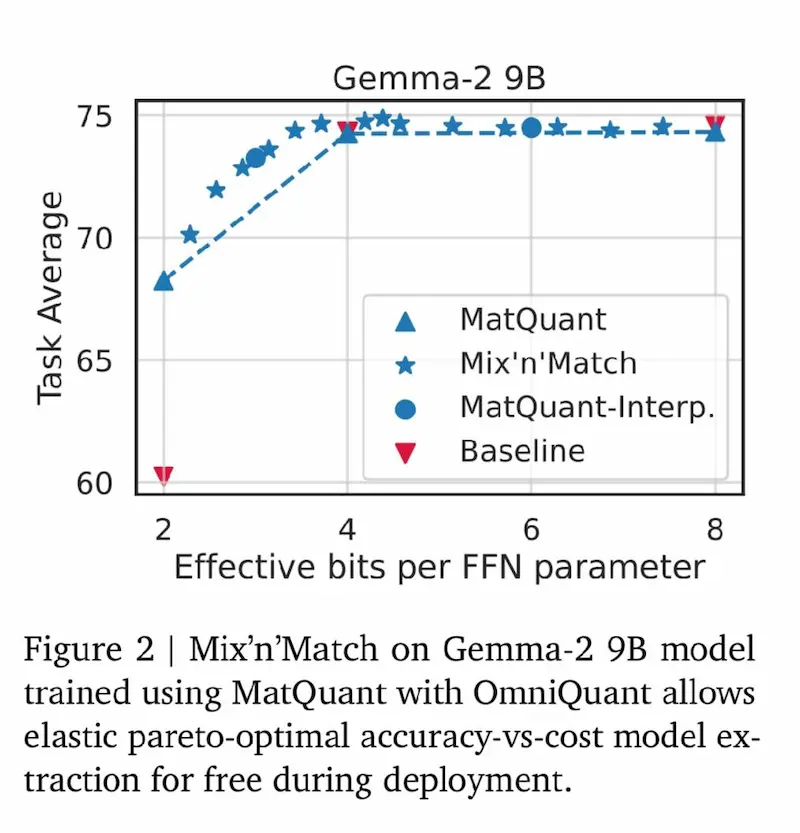
MatQuant di Google DeepMind
Un passo avanti per l’efficienza dell’AI, con modelli flessibili e adatti a diverse configurazioni hardware.
NSA (Natively trainable Sparse Attention)
DeepSeek pubblica un nuovo paper dedicato all'efficientamento dei LLM.
NSA (Natively trainable Sparse Attention) è un nuovo meccanismo che introduce un'architettura di attenzione sparsa che:
- riduce il numero di operazioni di attenzione senza sacrificare la qualità delle predizioni;
- è ottimizzata per l'hardware moderno, migliorando l'efficienza;
- può essere allenata end-to-end, evitando il pre-training su "full attention".
Il sistema è più veloce di 9-11x su sequenze di 64k token, e ottiene performance uguali o superiori su diversi benchmark.
L'evoluzione dei modelli di reasoning
Un paper molto interessante che esplora l'evoluzione dei modelli di reasoning attraverso il concetto di recurrent depth.
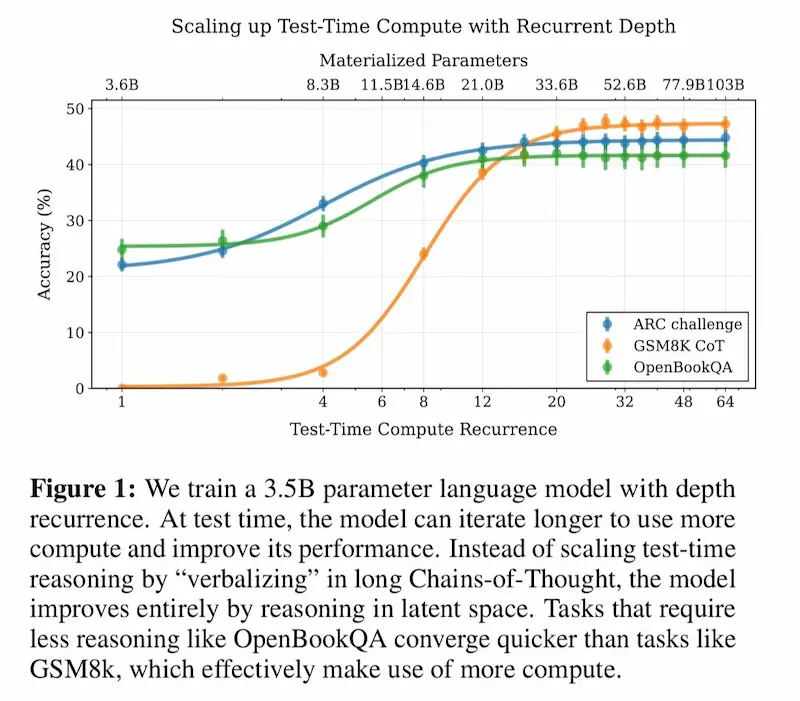
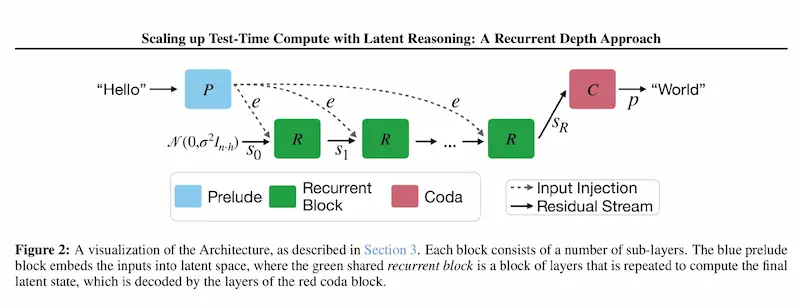
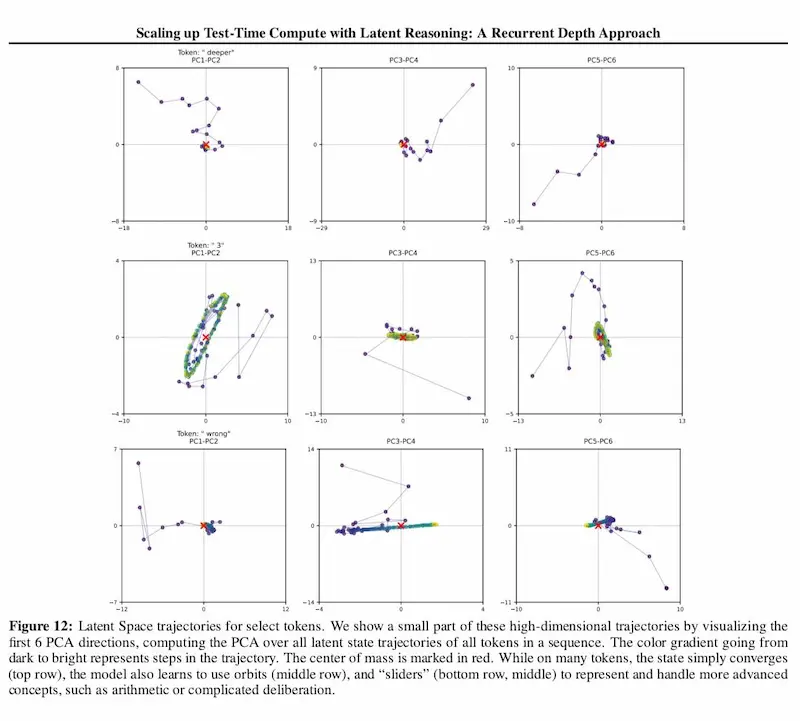
Recurrent depth: l'evoluzione dei sistemi di reasoning
Come funziona?
Invece di generare lunghe Chain-of-Thought esplicite, il modello ripete i calcoli internamente, ottimizzando il ragionamento in uno spazio latente. Questo gli permette di adattare il numero di iterazioni a test-time in base alla complessità del problema, senza bisogno di addestramento su dati specializzati.
- Migliore efficienza computazionale
- Migliori capacità di ragionamento senza contesti lunghi
- Test-time scaling: più iterazioni = migliori risposte
Un nuovo approccio per rendere l’AI più efficiente senza aumentarne le dimensioni.
Un'interazione multimodale tra AI Agent
Un esempio in cui Operator di OpenAI usa l'agent di Replit per creare un'applicazione in modo autonomo.
Gli agenti possono interagire in diversi modi, ad esempio orchestrati in un framework connesso a diversi tool.
In questo caso vediamo un'interazione in cui un agente sfrutta il browser e la multimodalità per usarne un altro, agendo come farebbe un essere umano.
this is wild 🤯🤯🤯
— Lamar (@LamarDealMaker) February 15, 2025
just paired openai operator with replit agent to build an app
watch as two ai agents team up, exchange credentials, and start testing
ai agent 🤝 ai agent
the future is here and it’s insane! pic.twitter.com/jIZnqW4fJD
Per il flusso sono stati usati 5 prompt.
AI co-scientist di Google
Google ha sviluppato AI co-scientist, un sistema avanzato basato su Gemini 2.0 che funge da collaboratore virtuale per i ricercatori.
Utilizzando un approccio multi-agente, il sistema genera ipotesi originali, pianifica esperimenti e migliora iterativamente i propri risultati, aiutando gli scienziati a navigare tra enormi quantità di dati e a identificare nuove direzioni di ricerca.
AI co-scientist di Google
Applicato in ambito biomedico, AI co-scientist ha già dimostrato il suo potenziale proponendo nuovi bersagli terapeutici per la fibrosi epatica, identificando farmaci riproposti per il trattamento della leucemia mieloide acuta e formulando ipotesi innovative sui meccanismi della resistenza antimicrobica.
Questo significa accelerazione nel processo di scoperta e ricerca. Ma, essendo un sistema completamente "neurale" rimane fondamentale una validazione umana altamente qualificata, in veste della componente "simbolica".
Il piano dell'Europa dedicato all'Intelligenza Artificiale
L'Europa presenta un piano per mobilitare circa 200 miliardi in investimenti per l’AI.
Il proposito è interessante, con l'idea di creare una sorta di "CERN dedicato all'intelligenza artificiale".
Criticità: il piano c'è, ed è in linea con l'obiettivo, ma non si parla di tempi. Inoltre, in Europa, sono presenti centri di ricerca e università d'eccellenza, ma mancano aziende che si occupano di intelligenza artificiale a livello delle Big Tech.

Three Observations
Sam Altman, in un nuovo post, afferma che l'AI cresce in modo logaritmico rispetto alle risorse investite. Concetto che richiama un comportamento previsto dalle leggi di scala.
Afferma, inoltre, che il costo dell'AI diminuisce drasticamente (di 10x ogni 12 mesi).
Il fatto è che si basa su trend attuali, ma non è garantito che la crescita dell’IA seguirà le stesse leggi di scala per sempre. Se il costo del computing continua a scendere, potremmo assistere a un’accelerazione senza precedenti, oppure a un cambio di paradigma che renderà le attuali previsioni obsolete.
Il vero test sarà capire se la qualità e la capacità dell’IA continueranno a migliorare al ritmo previsto una volta che il costo computazionale diventerà quasi trascurabile (i dati di qualità, la scarsità di chip avanzati, il costo energetico saranno trascurabili?).
Attualmente credo che architetture basate su agenti ibridi specializzati (es. sistemi neuro-simbolici) siano più interessanti e "immediate" della rincorsa verso la chimera dell'AGI basata su LLM.
Majorana 1 di Microsoft
Microsoft ha presentato Majorana 1, il primo chip quantistico basato sull’innovativa architettura Topological Core. Questo nuovo approccio sfrutta materiali chiamati topoconduttori per rendere i qubit più stabili e scalabili, aprendo la strada a computer quantistici con un milione di qubit.
Questa tecnologia potrebbe trasformare settori chiave come la chimica, la scienza dei materiali e l'AI, risolvendo problemi impossibili per i computer tradizionali. Un passo avanti decisivo verso il futuro del quantum computing.
Majorana 1 di Microsoft
Oggi ci stiamo accorgendo che ragionare solo sulla scala non ha più molto senso per l'evoluzione dell'AI. Ma "domani" nuove tecnologie potrebbero azzerare i limiti hardware e permettere di ottenere dati sintetici di qualità. Dovremo arrenderci all'amara lezione (rif. "The Bitter Lesson", Rich Sutton)? Lo scopriremo insieme.
OmniParser V2 di Microsoft
Microsoft ha rilasciato OmniParser V2: un sistema open source in grado di compiere azioni nell'interfaccia utente.
Non solo sul browser, ma si tratta di un sistema che usa un LLM in un Computer Use Agent.
OmniParser V2 di Microsoft
Il panorama di questa tipologia di agenti si sta arricchendo di giorno in giorno. E probabilmente saranno sempre più efficaci.
Un test di OmniParser V2
Come fanno questi sistemi a eseguire azioni sui browser e su qualunque interfaccia grafica?
Questo è un esempio di utilizzo di OmniParser V2 in esecuzione in locale. Il sistema elabora ciò che "vede" nello schermo, e lo converte in dati strutturati che mappano e classificano ogni elemento.
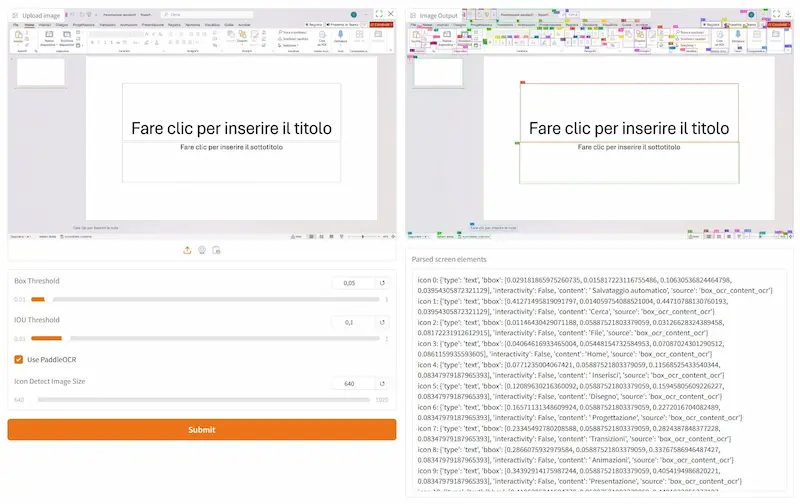
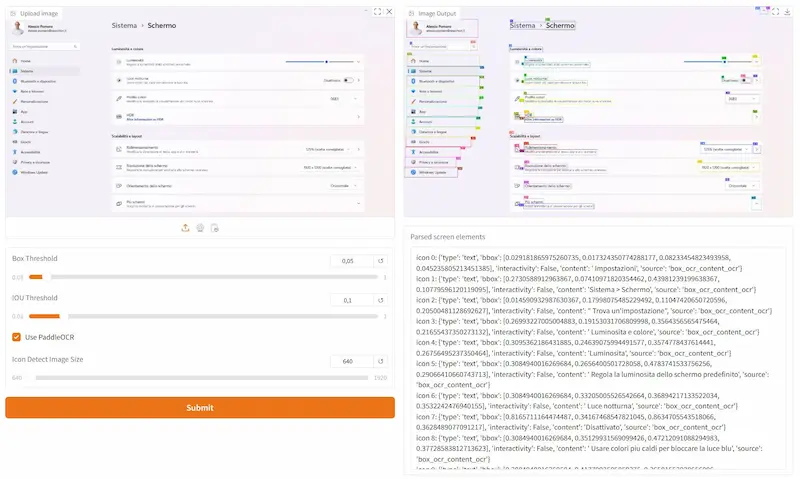
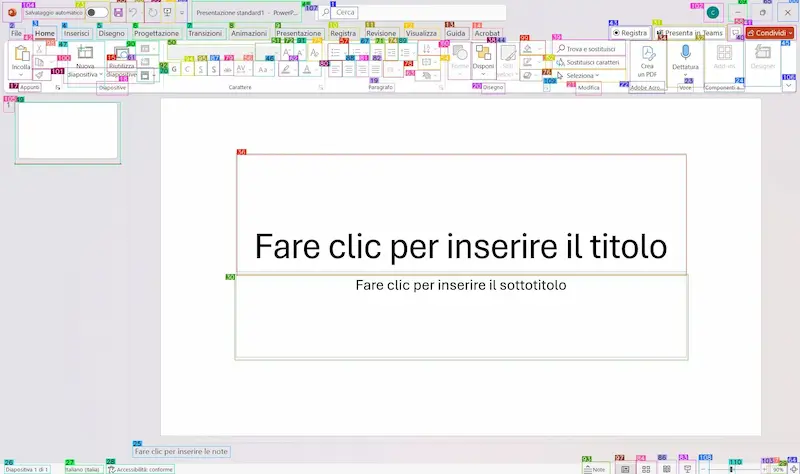
Un test di OmniParser V2
I dati diventano contesto per un LLM, che può eseguire operazioni sugli elementi.
Animate Anyone 2
Il Tongyi Lab di Alibaba Group ha presentato Animate Anyone 2: un modello avanzato in grado di animare immagini di personaggi.
Rispetto ai metodi precedenti, introduce un'importante innovazione: l'integrazione dell'ambiente circostante nella generazione dell'animazione.
Animate Anyone 2
Non si limita a estrarre segnali di movimento da un video sorgente, ma analizza anche il contesto ambientale (le aree senza personaggi) per creare animazioni più coerenti.
OpenDeepResearcher
Vedremo nascere diversi sistemi open source come "Deep Research" di OpenAI e Google.
OpenDeepResearcher è un esempio. Riceve in input un topic, effettua ricerche online, approfondisce l'argomento sviluppando e usando nuove query di ricercae; infine fornisce un report dettagliato.
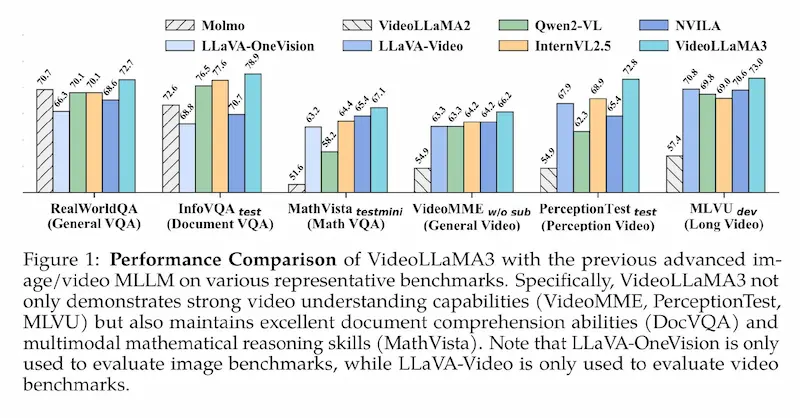
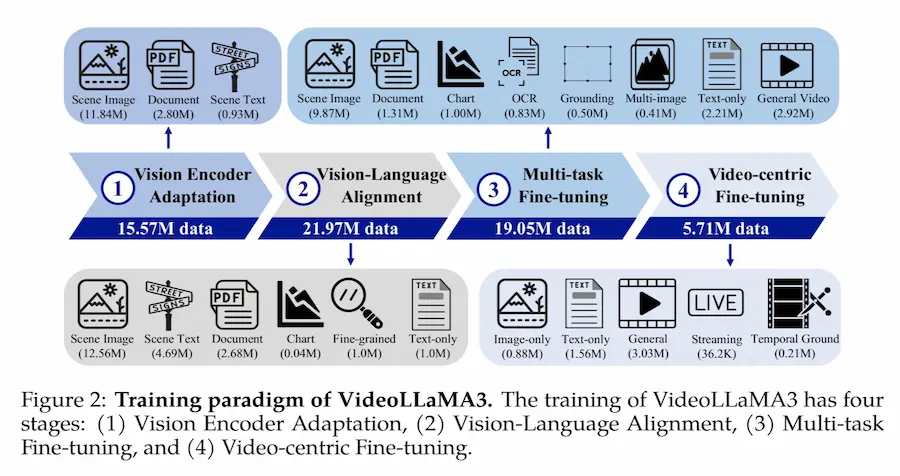
VideoLLaMA3 di Alibaba
Alibaba introduce VideoLLaMA 3, un modello vision-centric, costruito per migliorare la comprensione visiva attraverso immagini di alta qualità invece di enormi dataset video-text meno precisi.
Le principali innovazioni
- Any-Resolution Vision Tokenization (AVT): elabora immagini e video a risoluzioni variabili senza perdita di dettagli.
- Differential Frame Pruner (DiffFP): riduce i frame ridondanti nei video, migliorando efficienza e precisione.
- Vision-Language Alignment: allena il modello con descrizioni dettagliate per una comprensione più profonda.
- Dataset VL3-Syn7M: immagini accuratamente selezionate per garantire qualità nei dati di addestramento.
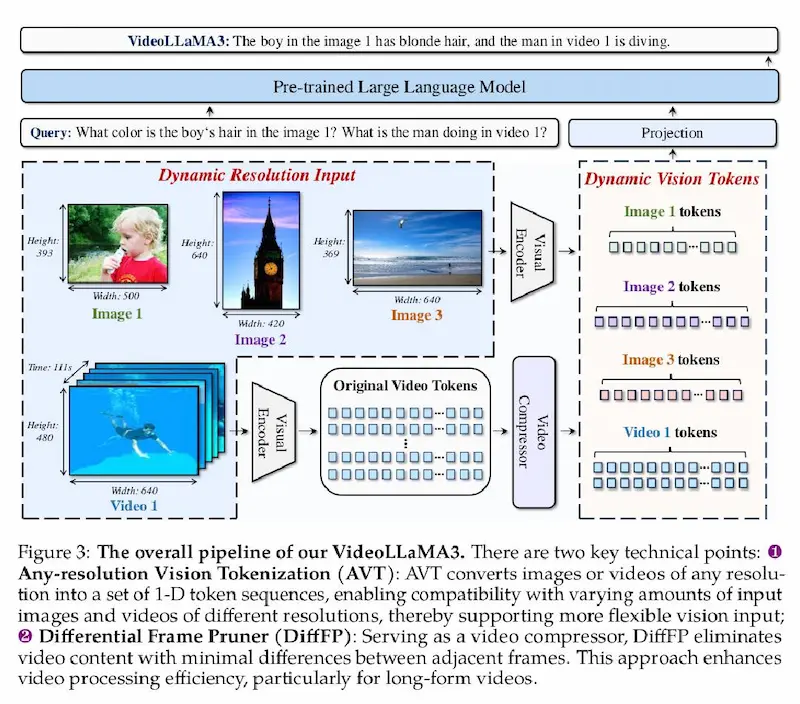
VideoLLaMA 3 di Alibaba
Performance
VideoLLaMA 3 supera i modelli precedenti in:
- OCR e documenti (InfoVQA, DocVQA)
- Ragionamento matematico visuale (MathVista)
- Comprensione multi-immagine (MMMU)
- Analisi avanzata dei video (VideoMME, MLVU)
Grazie alla sua architettura ottimizzata e alla gestione più intelligente dei video, VideoLLaMA 3 rappresenta un nuovo punto di riferimento nell’intelligenza artificiale multimodale.
Workflow multi-agent: la gestione dei flussi
Nella costruzione di workflow multi-agent, i framework come Autogen permettono di creare delle regole di intervento per gli agenti.
In questo modo, possiamo gestire in quali momenti serve iterazione, e in quali momenti sequenzialità nelle azioni.
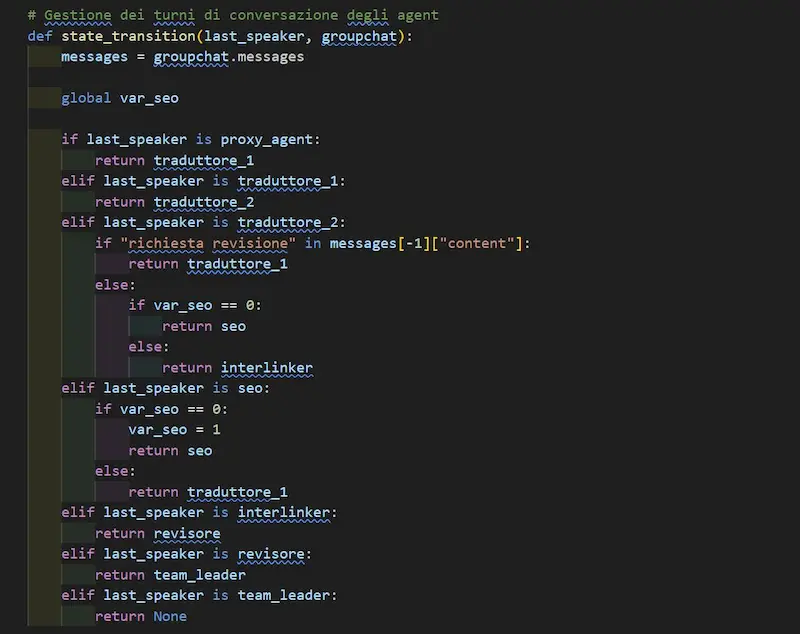
La funzione dell'esempio determina logiche di intervento degli agenti (StateFlow pattern), e viene usata dall'orchestratore per concedere i turni durante le interazioni.
AlphaGeometry 2: le performance
AlphaGeometry 2 di Google DeepMind ha superato i risultati di una medaglia d'oro medio nelle Olimpiadi Internazionali di Matematica (IMO), raggiungendo un tasso di soluzione dell'84% sui problemi di geometria (contro il 54% della prima versione).
Per quanto si ragioni su "chatbot" generici in grado di affrontare qualunque problema, gli agenti specializzati, secondo me, sono quelli che oggi possono raggiungere performance e affidabilità per affiancarci nella crescita in diversi ambiti.
AlphaGeometry, infatti, è un sistema neuro-simbolico, e funziona in questo modo:
- un LLM (Gemini) traduce il problema in un linguaggio più adeguato al sistema;
- il motore simbolico analizza i dati iniziali e mette a disposizione tutti i teoremi applicabili;
- se la soluzione non è immediata (in un problema delle IMO di certo non lo è), usa una combinazione di reti neurali (Gemini) e ricerca simbolica avanzata per individuare costruzioni ausiliarie (deduzione);
- il motore simbolico verifica la correttezza, e se la soluzione non è dimostrabile si torna a fare nuove deduzioni;
- il sistema restituisce la dimostrazione con i diagrammi necessari.

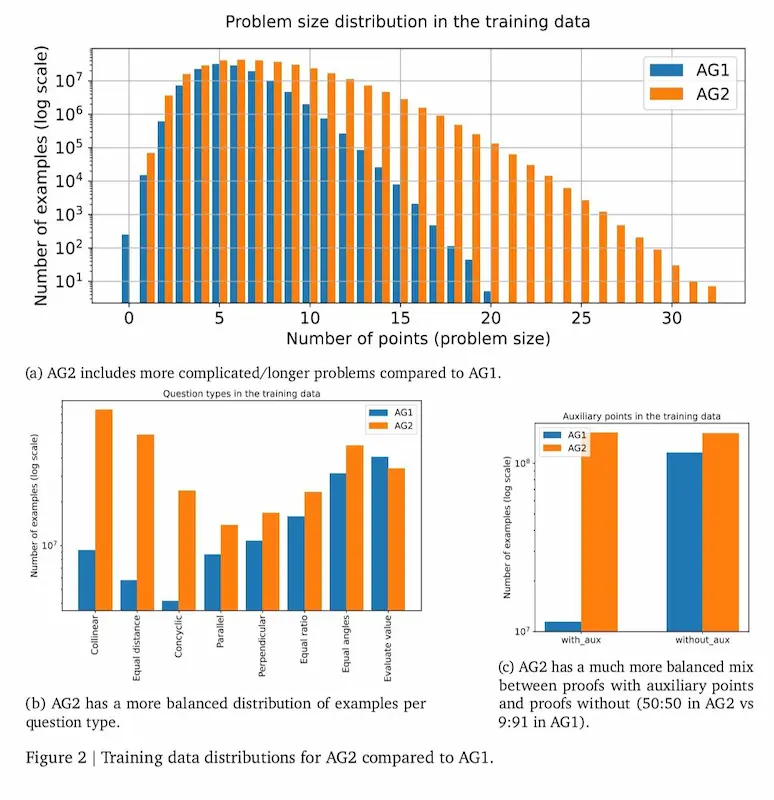
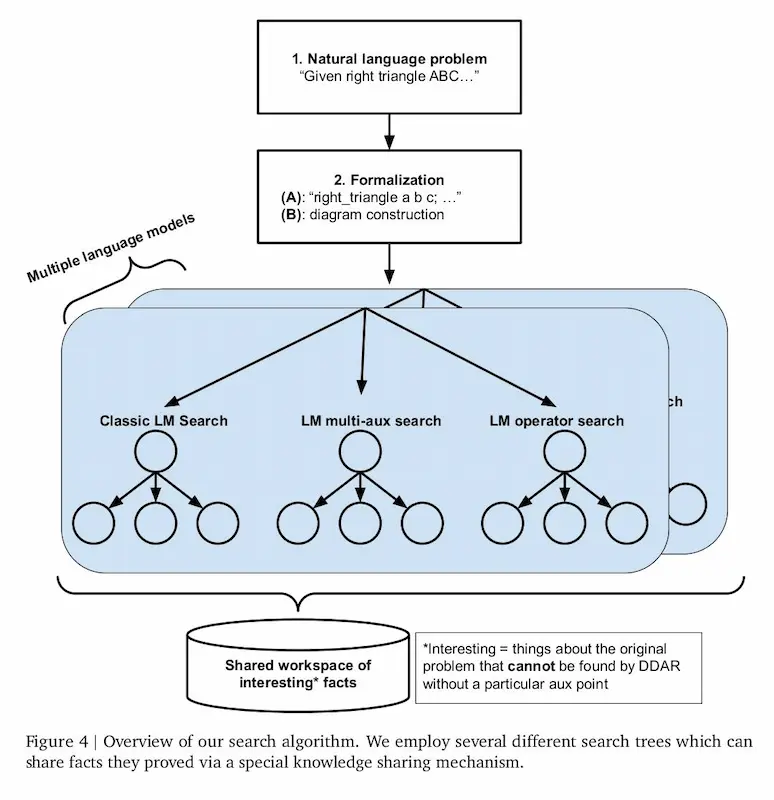
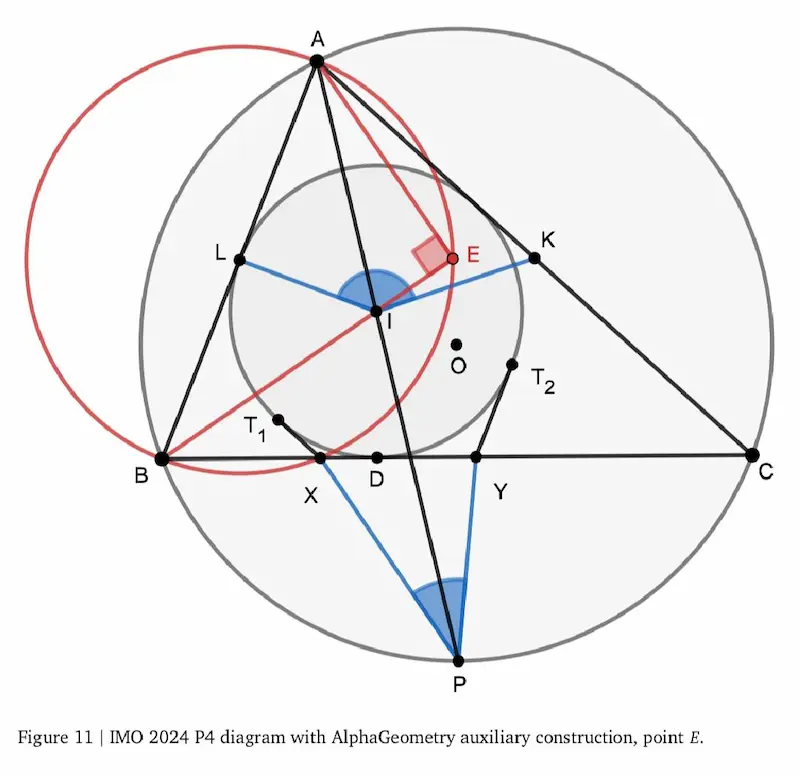
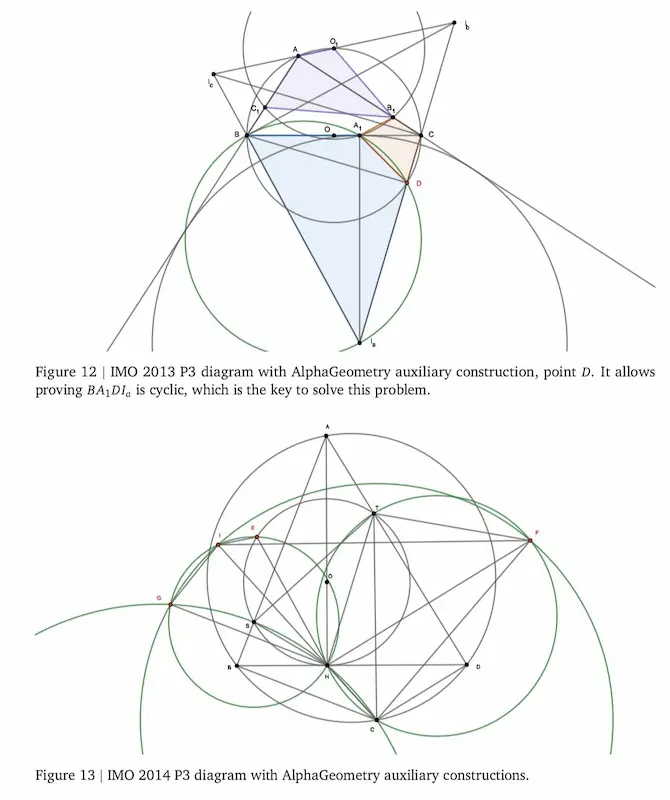
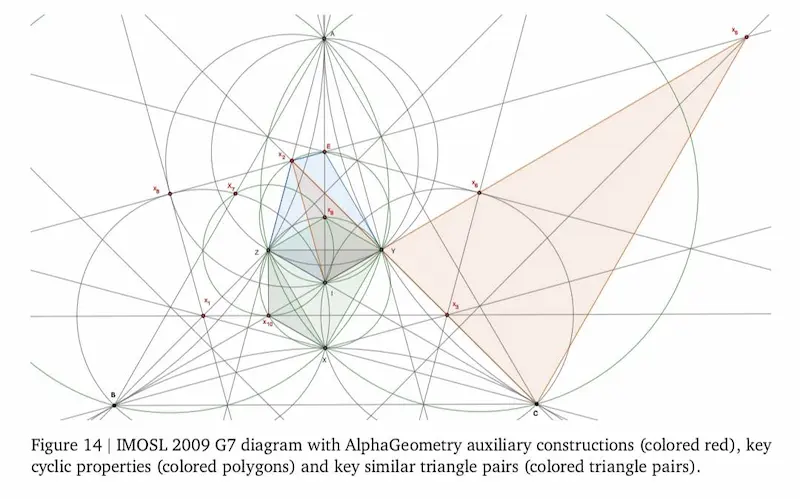
Le performance di AlphaGeometry 2 di Google DeepMind
In pratica unisce il ragionamento simbolico (rigore e affidabilità) alla velocità e flessibilità delle reti neurali (intuizioni).
Di certo si tratta di sistemi che non scalano velocemente e che sono più difficili da costruire, ma l'affidabilità, in certi contesti, vince.
AI Mode di Google
Secondo 9to5Google, Google starebbe lavorando all'AI Mode: una nuova esperienza che unisce la ricerca a un'interfaccia generata da Gemini 2.0.
Sundar Pichai aveva annunciato che il 2025 sarebbe stato un anno importante per l'innovazione in Search.. sarà questo l'inizio?
E sarà un inizio deciso o un "vorrei, ma non posso"? Di certo, per vincere la concorrenza con gli ibridi di questo tipo dovranno puntare su quello che sanno fare meglio: la ricerca potenziata dai dati strutturati che hanno a disposizione.
Cos'è AI mode?
Progettata per rispondere a domande più aperte, esplorative o molto specifiche (es. i confronti), offrirà risposte più strutturate, con collegamenti per approfondire sulle pagine web.
Un'interfaccia in stile chatbot permetterà di interagire in modo più dinamico, con possibilità di follow-up e input vocale nell’app di Google.
Attualmente sarebbe in test per i dipendenti negli USA.
Muse di Microsoft Research
Microsoft Research ha presentato Muse, un avanzato modello di AI generativa progettato per supportare la creazione di gameplay. È basato sul World and Human Action Model (WHAM), ed è in grado di generare ambienti di gioco e azioni dei controller, simulando sequenze di gameplay realistiche.
Muse di Microsoft Research
È stato addestrato con dati raccolti dal gioco Bleeding Edge, e ha analizzato oltre un miliardo di immagini e azioni di giocatori (più di sette anni di gameplay).
Il modello offre agli sviluppatori uno strumento potente per esplorare nuove idee, migliorando la creatività e l’iterazione nei processi di sviluppo.
Microsoft ha reso il modello open-source, insieme ai pesi, ai dati di esempio e a WHAM Demonstrator, un’interfaccia che consente di sperimentare direttamente le sue capacità.
L'evoluzione della chat di Mistral
Mistral evolve la sua chat con diverse novità.
- Velocità: può rispondere fino a 1k parole/s con la funzione Flash Answer.
- Ricerca online: combina fonti di qualità, tra cui pagine web, editoriali, social media.
- Multimodale: elaborazione di immagini, documenti e fogli di calcolo.
- Generazione di immagini: usa Flux Ultra, per ottenere output di qualità.
- Code interpreter: può sviluppare codice Python ed eseguirlo a supporto delle risposte all'utente.
- Mobile: disponibile per iOS e Android via app.

L'ho provato. Quello che posso dire è che attualmente siamo lontani dalle performance dei competitor.
OmniHuman-1 di Bytedance
Bytedance, l'azienda cinese che possiede TikTok, ha presentato OmniHuman-1, un framework avanzato per la generazione di video umani basato su un'unica immagine e segnali di movimento come audio e video.
OmniHuman-1 di Bytedance
Grazie a una tecnica di addestramento multimodale, il modello supera i limiti delle precedenti tecniche end-to-end, migliorando la qualità e il realismo dei video generati.
Le anteprime sono tecnicamente sbalorditive, ma aprono inevitabilmente diversi ambiti di riflessione.
VideoJAM di Meta
Meta introduce VideoJAM: un framework progettato per migliorare la generazione di movimento nei modelli video.
VideoJAM di Meta
Il sistema mira a risolvere un limite dei modelli di generazione video: la rappresentazione di movimenti realistici.
L'aspetto più interessante? Il framework può essere applicato a qualsiasi modello di generazione video con minime modifiche, senza richiedere nuovi dati di addestramento o maggiori risorse computazionali.
Qwen-2.5 Max: generazione video
Attraverso la chat di Qwen è ora possibile generare video.
Un esempio di generazione video con la chat di Qwen
La qualità generale di questo modelli è sempre più elevata.
- GRAZIE -
Se hai apprezzato il contenuto, e pensi che potrebbe essere utile ad altre persone, condividilo 🙂