Facebook AI presenta GSLM: un modello NLP non basato sul testo
Facebook AI presenta un modello di NLP non basato su testo. È il primo passo verso un nuovo approccio all'elaborazione del linguaggio naturale che sembra avere enormi vantaggi.


I modelli linguistici basati sul testo come BERT, RoBERTa e GPT-3 hanno fatto passi da gigante negli ultimi anni. Fornendo frasi scritte come input, possono generare un testo estremamente realistico praticamente su qualsiasi argomento.
Inoltre, danno vita anche ad utili modelli pre-addestrati che possono essere messi a disposizione di una grande varietà di complesse applicazioni di elaborazione di linguaggio naturale (NLP), come la sentiment analysis, sistemi di traduzione, il riconoscimento di entità e di informazioni, inferenze e riassunti, utilizzando poche etichette ed esempi.
Queste applicazioni, tuttavia, mettono in evidenza un'importante limitazione: possono essere utilizzate efficacemente solo su lingue dotate di grandi set di dati testuali, in grado di addestrare i modelli di intelligenza artificiale.
Generative Spoken Language Model (GSLM)
Cos'è GSLM? Si tratta di un progetto di Facebook AI, ed è l'acronimo di Generative Spoken Language Model, ovvero il primo modello NLP che si libera dalla dipendenza dal testo. Un modello che apre le porte a una nuova era di applicazioni NLP potenzialmente in grado di essere impiegate per tutte le lingue parlate sulla Terra, anche quelle prive di corposi set di dati testuali.
GSLM consente inoltre lo sviluppo di modelli di NLP che incorporano l'intera gamma di espressività del linguaggio orale. Fino ad oggi, il collegamento di un'applicazione NLP agli input vocali passava per l'addestramento di un sistema di riconoscimento vocale automatico (Automatic Speech Recognition - ASR), un'operazione caratterizzata da un elevato effort e dall'introduzione di potenziali errori, con un rendimento non ottimale nella codifica, e disponibile per un numero limitato di lingue.
Con questi nuovi modelli, l'obiettivo è quello di rendere l'ASR obsoleto, passando in modalità "end-to-end" dall'input all'output vocale.
Il video che segue mostra come l'AI, grazie a GSLM, riesce a continuare un input vocale di una persona che legge un frammento di un noto libro.
È impressionante il fatto che il parlato generato dal modello è assolutamente allineato, e difficilmente un ascoltatore percepirebbe il cambio.
Tutto questo si ispira alla capacità dei bambini in età prescolare di apprendere il linguaggio esclusivamente da input sensoriali grezzi ed interazioni audio, e questo rappresenta un modello entusiasmante per i progressi futuri che questa ricerca potrebbe consentire.
La struttura del modello
GSLM, nella sua versione di base ha 3 componenti:
- un codificatore che converte il parlato in unità discrete che rappresentano suoni ricorrenti nella lingua parlata;
- un modello linguistico addestrato nel prevedere il prossimo "elemento" in base a ciò che ha avuto precedentemente in input;
- un decodificatore che converte gli "elementi" in parlato.
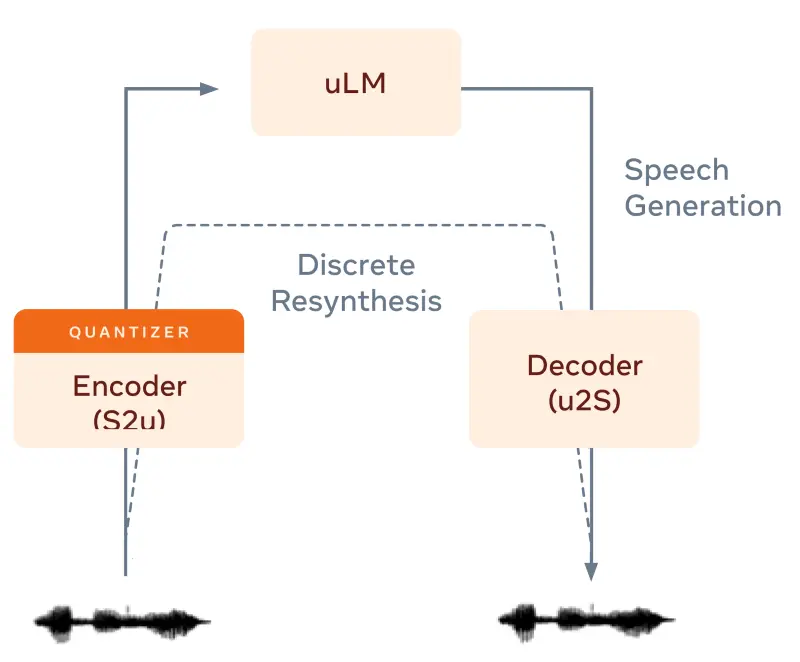
Attraverso i riferimenti indicati nell'area di approfondimento nella parte finale del post, è possibile approfondire in dettaglio il funzionamento del modello.
I vantaggi della NLP "textless"
Come dicevo, i modelli basati su testo funzionano molto bene per lingue come l'inglese, caratterizzate da enormi set di dati testuali adatti al training. Ma la maggior parte delle lingue non li possiede, e questo significa che molte di queste non hanno ancora potuto beneficiare totalmente della tecnologia NLP.
Capovolgere questa dinamica è stata una sfida entusiasmante che ha richiesto il lavoro di un team multidisciplinare di ricercatori di Facebook AI con esperienza nell'elaborazione del segnale, nell'elaborazione del linguaggio, nella NLP e nella psicolinguistica.
L'importanza della ricerca
Questa ricerca apre nuovi orizzonti.. infatti, addestrando modelli linguistici su input senza testo, è di fondamentale importanza per diversi motivi.
- In primo luogo dovrebbe rendere l'IA più inclusiva e in grado di modellare una varietà di lingue più ricca di quanto sia possibile oggi.
- In secondo luogo, avendo accesso alla piena espressività del linguaggio orale, i modelli dovrebbero incorporare sfumature e intonazioni, codificare ironia, rabbia e incertezza, risate, sbadigli e i rumori caratteristici della bocca in movimento. Grazie a tutto questo, la NLP textless può effettivamente non solo essere una soluzione per le lingue con meno dati a disposizione, ma rappresentare un significativo miglioramento anche per le lingue che hanno dati testuali a sufficienza.
- In terzo luogo, i ricercatori saranno in grado di addestrare modelli su esperienze audio-first, come podcast, programmi radiofonici e social audio, senza intervenire o addestrare un sistema di ASR. Si apre la possibilità di una serie di applicazioni mai immaginate prima, come la traduzione espressiva online per videogiochi multilingue, ad esempio, o la ricerca e il riepilogo di contenuti da audio archiviato.
- Infine, questi modelli possono aiutare la scienza a prevedere come la capacità dei bambini di imparare a parlare e a comprendere il linguaggio, sia influenzata dalle variazioni nell'input linguistico disponibile nelle diverse lingue.
Oltre a tutto questo, GSLM offre vantaggi concreti a coloro che oggi lavorano in ambito della NLP. I ricercatori saranno in grado di pre-addestrare i modelli in maniera molto più semplice, e di perfezionarli per attività end-to-end senza bisogno di testo. Ad esempio, questo lavoro ha reso possibile il primo sistema di traduzione vocale basata solo su audio. Ulteriori lavori riguarderanno l'analisi del sentiment, il recupero dei documenti, i sistemi di summarization, e altro ancora.
Gli obiettivi per il futuro di GSLM
La ricerca del team di Facebook AI in questo ambito è in continua evoluzione e il prossimo step sarà quello di applicare GSLM a set di dati che comprendono dialoghi casuali e spontanei, ovvero dove i modelli basati sul testo e l'ASR sono maggiormente in difficoltà.
Inoltre proseguiranno gli studi per dimostrare che GSLM può essere un metodo efficace per effettuare, con pochi dati, operazioni come la sintesi vocale, la sentiment analysis basata sulla voce e le attività di estrazione di entità ed informazioni dal parlato.
L'obiettivo macro è quello di sfruttare le sfumature e l'espressività che il parlato offre rispetto al testo scritto e di riuscire ad addestrare modelli in qualunque lingua del mondo, e questo apre una raccolta quasi infinita di dati potenziali per la comprensione del pensiero umano.
Per approfondire


 Alessio Pomaro
Alessio Pomaro