Embeddings e GPT-4 per clusterizzare le recensioni dei prodotti sfruttando l'AI
Come si possono raggruppare automaticamente centinaia di migliaia di recensioni per poterle analizzare? L'intelligenza artificiale ci può aiutare! Possiamo generate gli embeddings e clusterizzarli attraverso K-means. GPT-4, infine, può descriverli automaticamente. Vediamo come.

Prima di tutto un piccolo ripasso.
Nel campo della statistica, il clustering si riferisce a un insieme di metodi di esplorazione dei dati che mirano a identificare e raggruppare elementi simili all'interno di un dataset.
Raggruppare stringhe attraverso ChatGPT o le API di OpenAI (con i modelli di GPT-3, gpt-3.5-turbo o gpt-4) è relativamente semplice.
La tabella che segue, mostra un esempio di clusterizzazione di alcune recensioni di prodotti di Amazon ottenuta da ChatGPT attraverso GPT-4.
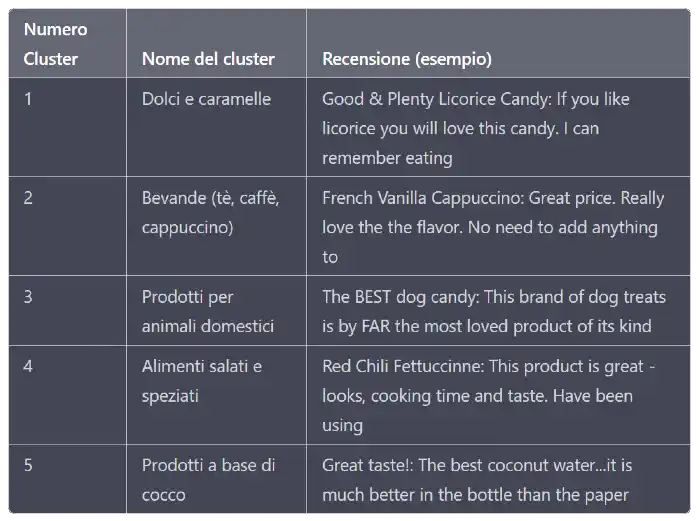
Il prompt? Quello che segue è esattamente l'input che ho utilizzato.
Clusterizza le seguenti recensioni in base all'argomento e al sentiment.
Crea una tabella con le seguenti colonne: "Numero Cluster", "Nome del cluster", "Recensione (esempio)".
Crea 5 cluster. Nella colonna "Recensione (esempio)" indica una recensione d'esempio.
RECENSIONI
<recensione 1>
<recensione 2>
< ... >
Chiaramente si tratta di un esempio: il prompt potrebbe essere ottimizzato e molto più dettagliato nelle istruzioni.
Tuttavia, anche se il modello "32k" di GPT-4 (gpt-4-32k) consente di elaborare un input molto ampio, procedere in questo modo non sarebbe consigliabile se dovessimo processare decine di migliaia o centinaia di migliaia di recensioni. La soluzione migliore, prevede l'utilizzo degli embeddings.
Cosa sono gli embeddings
Gli embeddings, di fatto rappresentano una vettorializzazione di stringhe. Per dirlo in termini più semplici, possiamo dire che si tratta di rappresentazioni numeriche (sequenze) di una o più parole che facilitano alle macchine la comprensione delle relazioni tra i concetti espressi.
Sono utili per lavorare con il linguaggio naturale e il codice, perché possono essere facilmente utilizzati e confrontati da altri modelli e algoritmi di machine learning per effettuare operazioni come:
- la ricerca, dove i risultati vengono ordinati in base alla pertinenza rispetto a una query di ricerca;
- il clustering, dove le stringhe di testo vengono raggruppate per somiglianza (e ne vedremo un esempio in questo post);
- le raccomandazioni, per suggerire elementi correlati in base ai contenuti che li caratterizza;
- la similarità, in cui dove vengono analizzate le distribuzioni di somiglianza;
- la classificazione, dove le stringhe di testo vengono etichettate in base alle loro caratteristiche.
La distanza tra due vettori (le sequenze numeriche) misura il loro legame. Piccole distanze suggeriscono un legame forte, mentre grandi distanze suggeriscono un legame debole.
Gli embeddings che sono numericamente simili, inoltre, sono anche semanticamente simili.
Ad esempio, il vettore che corrisponde alla frase "i nostri amici cani amano" sarà più simile al vettore della parole di "abbaiare" rispetto a quello del termine "miagolare".
La creazione degli embeddings con OpenAI
La generazione degli embeddings con i modelli OpenAI è abbastanza semplice: esiste un endpoint dedicato. Utilizzando la libreria Python ufficiale (OpenAI Python Library), si tratta di poche righe di codice. Quello che segue è l'esempio della documentazione.
import openai response = openai.Embedding.create( input="porcine pals say", model="text-embedding-ada-002" ) print(response)
La risposta conterrà proprio la sequenza di valori numerici corrispondenti.
{
"data": [
{
"embedding": [
-0.0108,
-0.0107,
0.0323,
...
-0.0114
],
"index": 0,
"object": "embedding"
}
],
"model": "text-embedding-ada-002",
"object": "list"
}
La clusterizzazione delle recensioni
Quello che vedremo è un semplice esempio di utilizzo degli embeddings per raggruppare le recensioni degli utenti ai prodotti di un e-commerce.
Userò un set di dati pubblico, che raccoglie circa 500.000 recensioni di Amazon in ambito food (Amazon fine-food reviews dataset), dal quale ho estratto le 1000 più recenti a scopo dimostrativo.
Ogni recensione ha un codice del prodotto (ProductId), l'id dell'utente (UserId), la valutazione (Score), il riepilogo (Summarize) e il testo (Text).
Per la valutazione di tutti i dati, è stata aggiunta una colonna che combina il riepilogo al testo; l'embedding verrà calcolato su quel testo.
Preparazione del dataset e generazione degli embeddings
La pagina web che segue, illustra gli step per preparare il dataset in Python. Le librerie necessarie sono: pandas, openai, transformers, plotly, matplotlib, scikit-learn, torch (transformer dep), torchvision, scipy.
Le operazioni che vengono svolte sono le seguenti:
- caricamento e lettura del file CSV vi partenza con le 1000 recensioni;
- concatenazione del riepilogo al testo nella colonna combined;
- generazione degli embeddings e creazione del file CSV con la nuova colonna dedicata.
 openai
openaiL'immagine mostra un'estrazione del file che si ottiene dall'elaborazione.
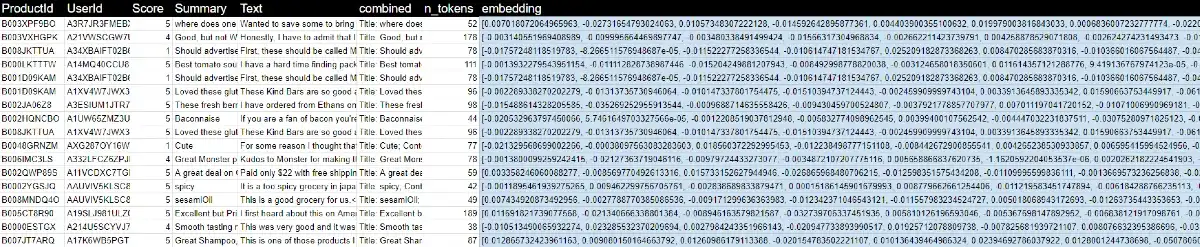
Cliccando o toccando il bottone che segue è possibile creare una copia su drive del file contenente le mille recensioni con gli embeddings.
Clusterizzazione attraverso K-means
Come detto in precedenza, la similarità tra vettori (tra embeddings) determina la similarità semantica tra le stringhe che rappresentano. Questo significa che, a questo punto, possiamo usare un semplice algoritmo di clusterizzazione per raggruppare gli embeddings, e di conseguenza le recensioni. In questo caso, viene utilizzato K-means. e la seguente pagina web ne spiega i diversi step sfruttando le molto note librerie Python numpy, pandas, sklearn e matplotlib. Nello specifico, vengono effettuate le seguenti operazioni:
- lettura del file CSV preparato;
- impostazione dei parametri di K-means, tra i quali il numero dei cluster che si desiderano produrre;
- riduzione della dimensionalità attraverso T-SNE;
- rappresentazione grafica dei cluster,
- stampa dei cluster con una selezione di recensioni per ognuno.
openaiQuella che segue è la rappresentazione dei cluster in un piano cartesiano, in cui i pallini dello stesso colore corrispondono alle recensioni dello stesso cluster. Eseguendo il codice nella pagina indicata in precedenza, si otterrà anche questa visualizzazione.
A differenza del codice proposto, in cui vengono generati 4 cluster, nel mio caso ne ho prodotti 5.
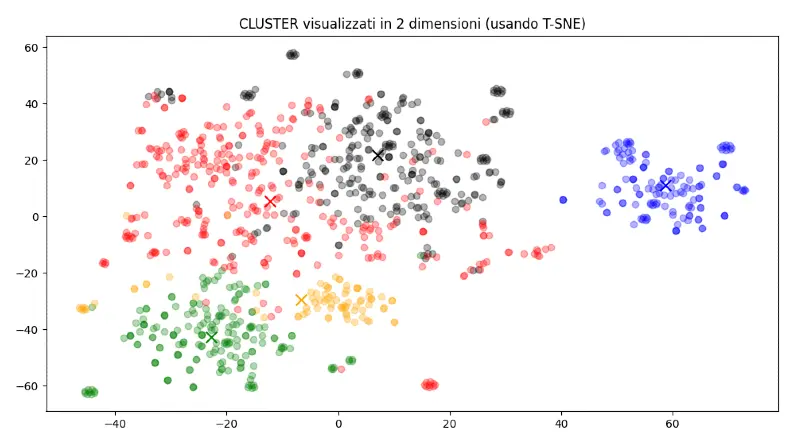
L'argomento dei cluster determinato da GPT-4
Una volta ottenuti i cluster, quindi i gruppi delle recensioni, per completare l'analisi possiamo sfruttare GPT-4 per ottenere una descrizione automatizzata di ognuno.
La tecnica è molto semplice. Per ogni cluster vengono estratte alcune recensioni, le quali vengono usate per comporre un prompt che richiede a GPT-4 di analizzare la similarità e di generare, di conseguenza, un titolo o una descrizione.
Quelli che seguono sono le descrizioni che ho ottenuto nella mia elaborazione (che si può visualizzare integralmente nel video).
- CLUSTER 1: Recensioni positive su dolciumi e snack vari
- CLUSTER 2: Recensioni miste su varietà di K-cups per macchine Keurig
- CLUSTER 3: Recensioni prevalentemente positive su cibi e bevande di vario genere
- CLUSTER 4: Recensioni miste su cibo e snack per animali domestici
- CLUSTER 5: Recensioni variegate su tè e bevande calde
L'esecuzione degli script
Nel video, si può vedere l'esecuzione delle logiche descritte direttamente nella mia console, nella quale eseguo gli script Python necessari.
Conclusioni
Abbiamo visto come, sfruttando l'endpoint specifico di OpenAI, sia semplice convertire stringhe (le recensioni in questo esempio) in vettori, quindi in sequenze numeriche che conservano un valore semantico. Facendo agire un algoritmo di clusterizzazione come K-means sugli embeddings, possiamo facilmente raggruppare le recensioni simili. Infine, attraverso un modello di linguaggio come GPT-4 abbiamo etichettato i cluster.
In pochi minuti, possiamo analizzare con precisione centinaia di migliaia di recensioni o altri contenuti generati dagli utenti, trasformandoli in dati utili a migliorare le performance degli e-commerce.
Anche se le recensioni sono contenuti che non comportano una grande complessità in fase di analisi, è necessario sottolineare che il modello di OpenAI dedicato agli embeddings (text-embedding-ada-002), è molto performante per la lingua inglese, ma molto meno per quella italiana. A questo proposito consiglio di fare dei test anche usando Cohere e Muse.
Per approfondire

