Cosa sono gli embeddings? Esempi di utilizzo
Cosa sono e come funzionano gli embeddings (o incorporamenti): una spiegazione semplice con alcuni esempi di utilizzo in ambito SEO, e riflessioni sull'importanza della consapevolezza di questi sistemi.


Punti salienti
- Cosa sono gli embeddings?
Gli embeddings, o incorporamenti, sono rappresentazioni numeriche (vettori di numeri reali) di contenuti (es. parole, frasi, paragrafi, documenti) in uno spazio multidimensionale. Si tratta di un metodo impiegato nel campo del machine learning e dell'elaborazione del linguaggio naturale (NLP), che rende possibile una rappresentazione semantica del linguaggio, e la capacità di elaborazione del testo da parte dei modelli di linguaggio (LLM). - Formazione degli embeddings
Durante il training, il modello perfeziona i vettori numerici per avvicinare quelli con significati simili, facilitando la comprensione delle relazioni semantiche tra le parole. - Tokenizzazione e embeddings contestualizzati
I modelli suddividono il testo in token, generano embeddings per ogni token e li combinano per rappresentare il significato dell’intero testo. - Utilità degli embeddings nella SEO
L’uso degli embeddings supporta il miglioramento della SEO con applicazioni come redirection automatizzata, gestione dei 404 e rafforzamento della rete di link interni. - Calcolo della similarità
La similarità tra embeddings si può misurare con vari metodi, con la similarità del coseno spesso preferita, anche se il prodotto scalare e altre tecniche possono offrire risultati comparabili. - Integrazione nei tool SEO
Strumenti come Screaming Frog permettono di generare embeddings durante la scansione dei siti web, integrando le API di modelli di AI (es. OpenAI, Google, Ollama). - Consapevolezza nell'uso degli embeddings
Per massimizzare i benefici degli embeddings, è cruciale comprendere la loro natura e i metodi di calcolo utilizzati, evidenziando l’importanza di un approccio consapevole e ben studiato.
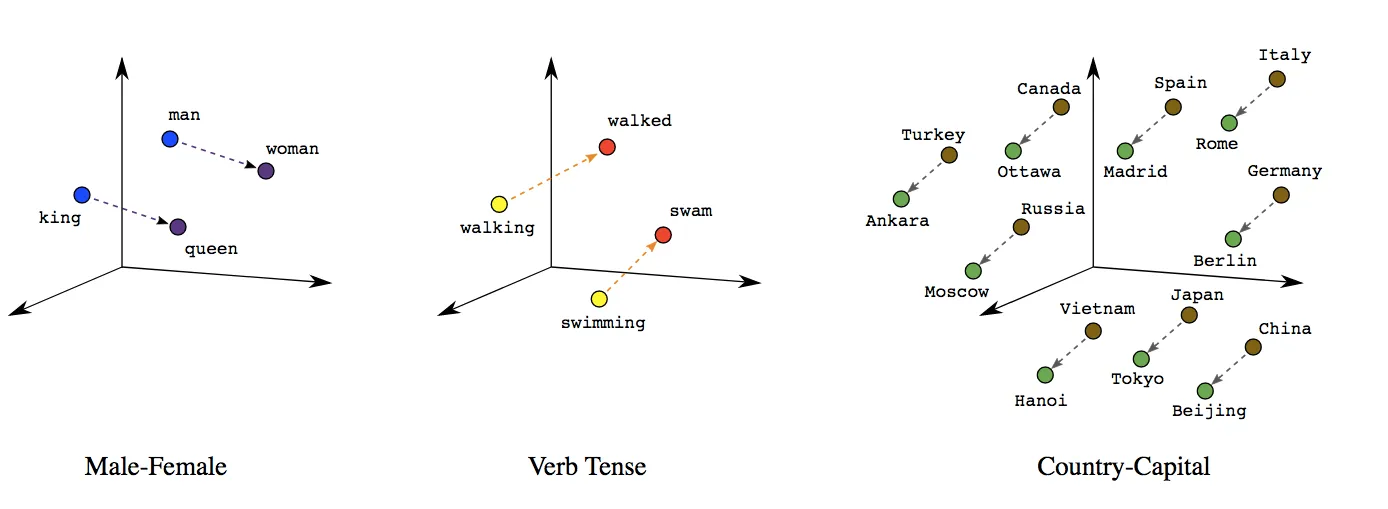
Immaginiamo che lo spazio 3D che segue rappresenti uno spazio semantico del linguaggio.
In questo scenario, ogni puntino viola rappresenta l'embedding di una parola, ossia la sua rappresentazione numerica in uno spazio tridimensionale (la sequenza numerica dell'embedding corrisponde alle coordinate nello spazio multidimensionale del puntino).
Gli embeddings sono rappresentazioni numeriche che trasformano parole o frasi in vettori di numeri reali.
Si tratta di un metodo impiegato nel campo del machine learning e dell'elaborazione del linguaggio naturale (NLP), che rende possibile una rappresentazione semantica del linguaggio, e la capacità di elaborazione del testo da parte dei modelli di linguaggio (LLM).
Nell'esempio, li vediamo rappresentati in 3 dimensioni, ma nella realtà questi vettori esistono in spazi con molte più dimensioni. Gli embeddings di OpenAI, ad esempio, arrivano a oltre 3000 dimensioni: uno spazio che non possiamo visualizzare facilmente.
La potenza degli embeddings risiede nel fatto che i vettori "catturano" le caratteristiche semantiche e sintattiche del linguaggio, permettendo ai modelli di linguaggio di "comprendere" e manipolare il testo in modo matematico.
In che modo riescono a rappresentare queste caratteristiche? Le coordinate dei vettori nello spazio multidimensionale fanno sì che parole con significati simili siano vicine tra loro. Ad esempio, parole come "gatto" e "felino" si troveranno vicine nello spazio degli embeddings, mentre parole come "gatto" e "automobile" saranno molto lontane.
Possiamo intuire con semplicità, quindi, che più aumentano le dimensioni dello spazio, e più aumenta la precisione della rappresentazione.
Come vengono definiti gli embeddings?
Nella fase iniziale del training di un LLM, i vettori numerici che rappresentano le parole sono casuali o derivano da una pre-inizializzazione. Il modello, durante l'addestramento, analizza ampie collezioni di testo, che includono dati provenienti da libri, articoli e contenuti web, osservando l’uso delle parole in vari contesti.
Attraverso questo processo di ottimizzazione, il modello raffina progressivamente i valori numerici dei vettori, in modo da avvicinare tra loro quelli che rappresentano parole con significati simili, rendendo così esplicite le relazioni semantiche tra le parole. Ad esempio, parole che appaiono frequentemente in contesti simili avranno rappresentazioni vettoriali simili.
Una volta concluso il training, i vettori diventano altamente raffinati e riescono a cogliere molte delle sottigliezze del linguaggio umano, come sinonimi e analogie.
Ecco perché i modelli di linguaggio sono così abili nell’interpretare e generare testo.

Successivamente, quando usiamo un modello per generare gli embeddings, forniamo una parola in input, e il modello recupera l'embedding corrispondente dalla matrice di embeddings ottimizzata durante la fase di training. Il vettore restituito rappresenta le caratteristiche semantiche della parola, basate sulla conoscenza acquisita dal modello.

Se, ad esempio, diamo in input al modello "text-embedding-3-large" di OpenAI la parola "marketing", otteniamo il vettore numerico che segue.

I valori che si percepiscono dall'immagine sono le 3.072 dimensioni con le quali il modello rappresenta la parola.
"marketing" = [-0.0021438375115394592, -0.00014348721015267074, -0.0066122193820774555, 0.001951836864463985, ..., -0.004653195384889841, 0.018990622833371162, 0.008846410550177097, -0.0012166894739493728, 0.015064360573887825, -0.0035094046033918858, -0.0026982782874256372]
Parole o Token?
Fino a questo punto, abbiamo ragionato in termini di "parole." Ma i LLM non si basano direttamente sulle parole come unità di base, bensì sui token.
Un token è una sequenza di caratteri, e può rappresentare una parola, una parte di parola o persino un singolo carattere, a seconda del contesto e della lingua. È l’unità fondamentale che i modelli di linguaggio utilizzano per processare il testo.
Ricostruiamo il flusso delle operazioni
Con questa precisazione, rivediamo il flusso con il quale il modello genera gli embeddings di un testo.
- Forniamo al modello un testo (che può essere una parola, una frase o un paragrafo, o un documento),
- il modello lo divide in token (un processo chiamato tokenizzazione),
- recupera gli embeddings contestualizzati per ogni token, ovvero rappresentazioni numeriche che catturano il significato di ogni token nel suo contesto,
- infine, attraverso tecniche come l’attenzione e la media pesata, combina gli embeddings dei singoli token per ottenere un embedding complessivo, che rappresenta il significato dell’intero testo.

Naturalmente, anche la fase di training, e quindi di ottimizzazione dei vettori, deve essere rivista in ottica di utilizzo di token
A cosa servono gli embeddings?
Ora che abbiamo compreso la natura di questi sistemi, che sono alla base del funzionamento dei modelli di linguaggio (LLM) possiamo chiederci: a cosa può servire la vettorializzazione dei testi nei flussi operativi?
La trasformazione di contenuti in sequenze numeriche che ne rappresentano il significato permette di determinare la similarità dei testi attraverso semplici calcoli matematici. E questo può trasformarsi, ad esempio, in sistemi di recommendation (di prodotti, di articoli, o di contenuti multimediali in base alle preferenze degli utenti), ricerche evolute su richieste in linguaggio naturale (i moderni sistemi RAG - Retrieval Augmented Generation - si basano esattamente su questi concetti), automazioni di processi su larga scala.
NOTA: il calcolo della similarità non è l'unica operazione attuabile sugli embeddings, ma è probabilmente quella più usata.
Esempi di utilizzo nella SEO
In ambito SEO, possiamo usare gli embeddings in diversi contesti, ad esempio la redirection in fase di migrazione, la gestione dei 404 post migrazione e il rafforzamento della rete di link interni.
Per la trasformazione di contenuti testuali in embeddings possiamo usare uno script in Python (o in altri linguaggi di programmazione) che implementa le API del modello di linguaggio che scegliamo. Ecco un esempio di codice Python che sfrutta le API di OpenAI per ottenere l'embedding di un testo.
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
input="Your text string goes here",
model="text-embedding-3-small"
)
print(response.data[0].embedding)
Oppure possiamo usare Screaming Frog SEO Spider, che ha introdotto la generazione degli embeddings (compatibile con i modelli di OpenAI, Gemini di Google e Ollama) direttamente in fase di scansione dei siti web.
Questo significa che, mentre il sistema effettua il crawling, può considerare dei contenuti presenti nelle pagine come testi da trasformare in embeddings. E siamo noi a poter configurare il sistema in modo da scegliere i testi di interesse.
La configurazione può avvenire in due modalità:
- usando uno snippet nella sezione JavaScript personalizzato (documentazione);
- usando una connessione diretta alle API dei modelli (dalla versione 21.0).
Chiaramente lo strumento può fare anche altre operazioni usando gli LLM, ma rimaniamo sul tema degli embeddings.
Redirection in fase di migrazione
In questo caso, possiamo scansionare il vecchio sito web e il nuovo sito web (quello che lo sostituirà), ottenendo gli embeddings dei contenuti delle diverse pagine. Con uno script Python, quindi, possiamo misurare la similarità tra le pagine, e, in base a questa, determinare delle associazioni tra gli URL delle vecchie risorse e gli URL delle nuove risorse.

Infine, sempre attraverso semplici istruzioni in Python, possiamo ottenere automaticamente le regole di rewrite per la redirection.
Gestione dei 404 post migrazione
In questo caso, abbiamo a disposizione la lista delle pagine che restituiscono uno status code 404 in Search Console. Come possiamo gestirle in modo automatizzato? O comunque, come possiamo avere un'automazione che ci fornisce un aiuto per gestirle?
Possiamo, ad esempio, trasformare in embeddings gli URL (la stringa dell'URL), oppure gli slug degli URL. Allo stesso modo, dalla scansione del sito web online, possiamo ottenere gli embeddings delle stringhe dei nuovi URL.

Attraverso un calcolo della similarità, quindi, possiamo, ancora una volta, ottenere un'associazione tra vecchi URL e nuovi URL, producendo una redirection automatizzata.
Con questa tecnica, in alcuni progetti, abbiamo ottenuto un matching corretto quasi al 100%. Chiaramente, una condizione determinante per il funzionamento è che gli URL siano "parlanti".
Rafforzamento dei link interni
Usando Screaming Frog, possiamo scansionare, ad esempio, le categorie di un e-commerce ottenendo gli embeddings dei contenuti al loro interno. Usando uno script per determinare la similarità, possiamo ottenere una lista di link tra le categorie più simili che possono diventare link in pagina verso categorie semanticamente affini e "related link" nei dati strutturati.

Note sull'uso di Screaming Frog
In questi esempi ho usato la modalità basata sugli snippet JavaScript per creare gli embeddings, perché permettono una configurazione come quella che segue.
In pratica, non sto usando lo snippet di default dedicato agli embeddings (il quale vettorializza tutto il testo presente nel body), ma una variante in cui vado a creare una precisa stringa da vettorializzare, composta dal nome della categoria e dal testo della categoria.
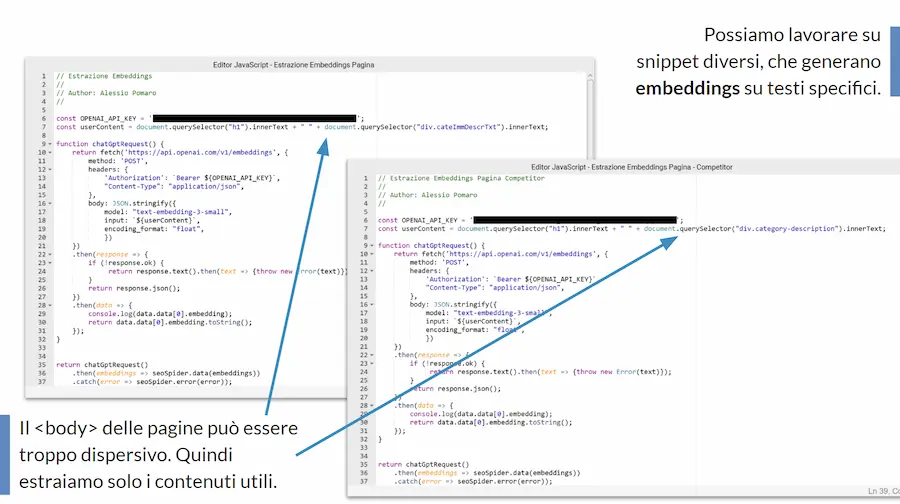
Grazie a questo accorgimento, possiamo ottenere degli embeddings che rappresentano dei testi molto precisi, e soprattutto confrontabili. Considerare tutto il testo presente nel body sarebbe troppo dispersivo e poco preciso per dei confronti sulla semantica.
Dobbiamo usare dati puliti e confrontabili, se vogliamo ottenere il massimo da questi sistemi!
Come calcoliamo la similarità tra gli embeddings?
Come calcoliamo la similarità? Questo è un tema importantissimo, perché fa parte del processo necessario all'ottenimento di un output usabile a partire dagli embeddings.
Il metodo più usato è la similarità del coseno, che si basa sull’angolo tra due vettori (angolo piccolo = vettori simili; angolo grande = similarità scarsa).
Ma è sempre la scelta giusta?
Secondo uno studio di Netflix, la risposta è NO.
Piccola parentesi: perché Netflix fa uno studio sulla similarità tra embeddings? Perché anche queste piattaforme usano tecnologie di questo tipo per l'analisi dei contenuti che propone agli utenti.
Può non essere sempre la scelta giusta perché la similarità del coseno, come visto in precedenza, considera l’angolo, ma non della lunghezza dei vettori (la cosiddetta magnitude). E se usiamo embeddings in cui la magnitude è un elemento utile alla rappresentazione del testo, non stiamo effettuando un confronto corretto.
Facciamo un test
Proviamo a usare gli embeddings di uno degli esempi precedenti per confrontare il calcolo della similarità effettuato con diversi metodi: similarità del coseno, prodotto scalare, similarità di Jaccard, distanza euclidea, distanza di Manhattan.
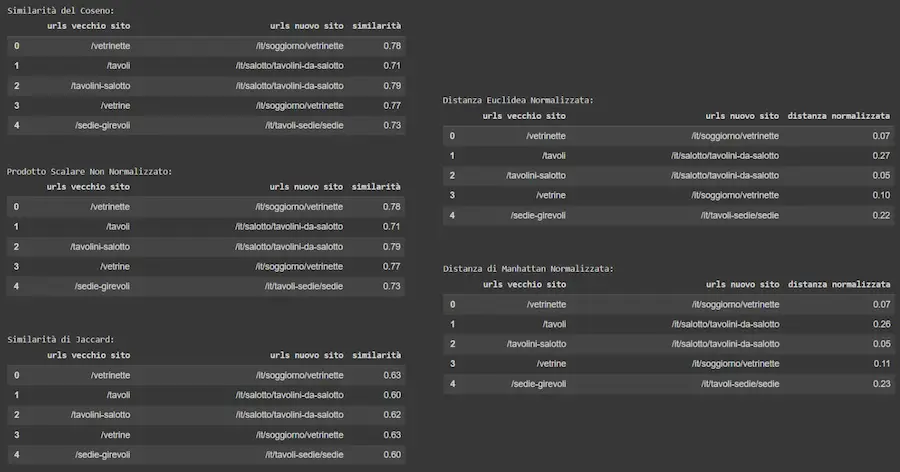
In base ai risultati del test, usando gli embeddings generati con i modelli di OpenAI, la similarità del coseno è effettivamente il metodo migliore.
Ma il test mette in evidenza un aspetto interessante: come si vede, infatti, gli indici di similarità del coseno e del prodotto scalare sono identici. Eppure sono determinati da calcoli diversi: il prodotto scalare tiene conto anche della lunghezza dei vettori, mentre, come visto in precedenza, la similarità del coseno no.
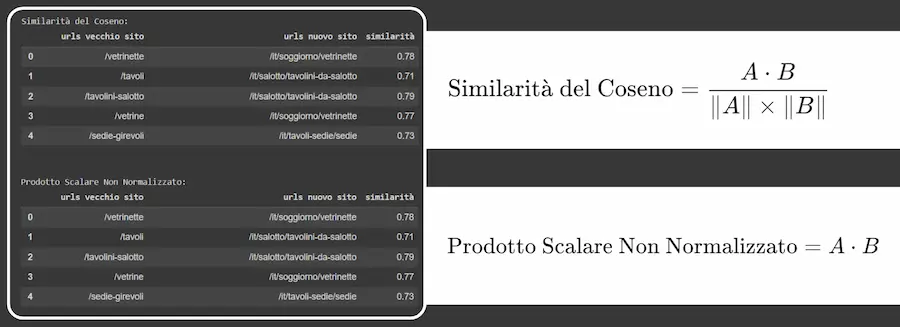
Quindi perché otteniamo risultati identici? Non è magia, e la spiegazione la troviamo nella documentazione degli embeddings di OpenAI.

Molto semplicemente, gli embeddings di OpenAI sono normalizzati alla lunghezza "1". Questo fa sì che usando la similarità del coseno, il prodotto scalare, o anche la distanza euclidea, otterremo sempre lo stesso ranking di similarità.
Tutto questo per arrivare a una conclusione che mi sta particolarmente a cuore.
Se vogliamo ottenere performance da questi sistemi, dobbiamo essere consapevoli della natura degli strumenti che stiamo utilizzando.. e per farlo ci sono 3 consigli: studiare, studiare, studiare.
Advanced SEO Tool
Il 30 ottobre ho raccontato questi concetti all'Advanced SEO Tool a Milano. Quello che segue è il video completo dell'intervento.
Embeddings e SEO.. è QUASI magia - Advanced SEO Tool 2024
- GRAZIE -
Se hai apprezzato il contenuto, e pensi che potrebbe essere utile ad altre persone, condividilo 🙂