L'AI è una "black box"? I grafi della conoscenza possono renderla controllabile
Spesso si sente dire che gli algoritmi di Intelligenza artificiale sono delle "black box", le quali danno risposte ma non danno spiegazioni. I grafi della conoscenza potrebbero rappresentare una spiegazione per rendere gli algoritmi più affidabili Vediamo come!


Punti salienti
- La "scatola nera" dell'AI
L'AI spesso è percepita come una "scatola nera" che restituisce risposte senza spiegare il processo che le genera, creando un senso di imperscrutabilità. - Pesi e parametri delle reti neurali
In una rete neurale, i pesi assegnati agli input influenzano l'output, ma con miliardi di parametri diventa impossibile comprendere l'intero processo. - Sistemi di autoapprendimento
L'AI moderna tende a creare autonomamente i propri dati di training, come un algoritmo che "gioca contro sé stesso," complicando ulteriormente la trasparenza. - Fiducia e trasparenza nell'AI
Le applicazioni future devono poter spiegare i propri output per garantire maggiore fiducia da parte degli utenti. - Il ruolo dei grafi della conoscenza
I grafi della conoscenza permettono all'AI di fornire raccomandazioni spiegabili, poiché contengono informazioni strutturate sugli oggetti e le loro relazioni. - Provenienza dei dati di addestramento
La tracciabilità delle fonti dei dati di training è fondamentale per controllare la qualità delle previsioni dell'AI e assicurare l'affidabilità delle risposte. - Verso un'AI più affidabile e controllabile
I knowledge graph rappresentano il futuro dell'AI spiegabile, poiché consentono sistemi più ispezionabili e verificabili, rendendo l'AI più trasparente e affidabile.
Perché si sente spesso dire che l'intelligenza artificiale è una "scatola nera" che dà risposte ma non dà spiegazioni su come ha ottenuto tali risposte? Proviamo a spiegarlo in maniera semplice.
Prendiamo in considerazione una semplice rete neurale artificiale. Dal punto di vista matematico, una rete neurale rappresenta una funzione che trasforma degli input (i1 e i2) in un output (o).
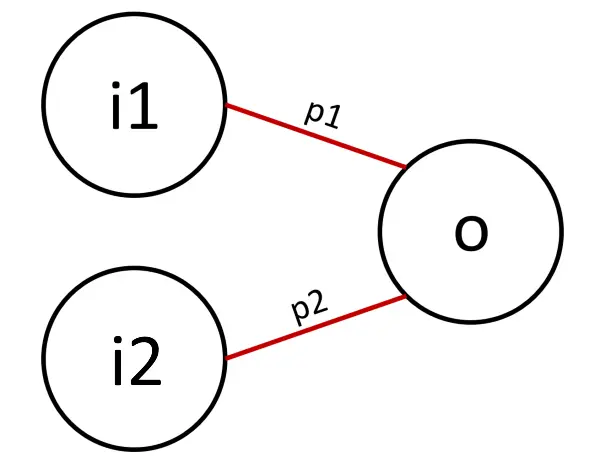
Le connessioni tra input e output prendono il nome "pesi" (p1 e p2).
Che compito hanno i pesi all'interno della funzione? Rappresentano, come dice la parola stessa, il peso (l'importanza) di ogni input. Quindi possiamo immaginare che gli input che entrano nella funzione vengano moltiplicati per i pesi.
I pesi sono proprio i famosi parametri della rete neurale, ovvero i valori che vengono fatti variare in fase di training in modo che l'output della funzione sia in linea con la previsione attesa.
Come funziona una rete neurale artificiale? Una spiegazione semplice
Finché ragioniamo su una rete neurale così semplice, tutto è molto facile da comprendere ed i pesi possono essere determinati anche "con carta e penna". Ma se le rete diventa molto ampia, con un grande numero di livelli di output intermedi (che diventano a loro volta input per altri nodi), e con miliardi di parametri che variano ad ogni esempio di training per ottimizzare la determinazione dell'output..
diventa davvero impensabile capire come lavora l'algoritmo per generare la previsione, e diventa impensabile capire quali dati di training hanno influenzato l'output.
Ecco perché spesso si associa l'AI ad una "black box".
Oggi, inoltre, si va verso soluzioni che creano autonomamente gli esempi di training, come se un "algoritmo scacchistica" imparasse giocando contro sé stesso milioni di partite invece di apprendere da strategie conosciute, aggiornando automaticamente i parametri della sua rete neurale.
Il video che segue spiega in maniera molto interessante questo approccio.
AI e biologia sintetica
Questo tipo di tecnologia ha creato e sta creando modelli potentissimi applicati al linguaggio, alla classificazione e all'elaborazione delle immagini, con risultati spesso sbalorditivi. Allo stesso tempo, però fa trasparire delle preoccupazioni derivanti proprio dall'imperscrutabilità dei sistemi di deep learning.
Per questo motivo, la prossima generazione di sistemi di intelligenza artificiale andrà a valorizzare la fiducia tra l'utente e l'IA nelle applicazioni del mondo reale.
Perché è importante sapere come vengono determinate le risposte?
Immagina di considerare due siti web che consigliano libri da leggere. Il primo fornisce semplicemente una classifica di testi suggeriti, anche in base ad una cronologia di letture precedenti. Il secondo, invece, include un suggerimento e anche le motivazioni che l'hanno determinato. Ad esempio, consiglia il primo libro perché hai appena finito il prequel dello stesso autore; il secondo perché sei un fan dei contenuti di fantascienza che con i viaggi nel tempo.
Di quale sito web ti fideresti di più?
Il primo sito web opera come la maggior parte dei sistemi basati sull'intelligenza artificiale che sono stati sviluppati negli ultimi anni. Si basano, infatti, su modelli statistici estratti da dati di utenti acquisiti per lunghi periodi di tempo. Gli algoritmi non sono trasparenti e non è chiaro l'obiettivo finale del sistema.
Si stanno ottimizzando i consigli in base ai gusti degli utenti o a ciò che porta maggiori entrate al sito web?
Le raccomandazioni si basano su un comportamento recente o sul modello di preferenze datato e creato al momento della registrazione? Se una raccomandazione dovesse risultare sbagliata, non c'è modo di capire le motivazioni che hanno condotto quell'output.
Anche l'accesso al codice sorgente dei sistemi e la conoscenza dei pesi impostati da modelli di deep learning non sarebbero sufficienti a fornire spiegazioni soddisfacenti sulle previsioni.
L'ottimizzazione cieca dell'accuratezza porta a consigli senza contesto!
Nel secondo sito web le raccomandazioni hanno delle spiegazioni perché il sistema "è a conoscenza" dei prodotti che sta consigliando; questo significa che i prodotti consigliati non sono soltanto correlazioni statistiche, ma corrispondono a dati strutturati relativi all'oggetto del "mondo reale". Il secondo sistema, in pratica, ha accesso a un database contenente informazioni organizzate (noto come "grafo della conoscenza"), con l'entità del libro, i relativi attributi (es. genere, trama, autore, personaggi), e le correlazioni con le entità ad esso connesse.
Nei sistemi di intelligenza artificiale di prossima generazione, le previsioni verranno generate anche in base al grafo di conoscenza al quale hanno accesso.
Proprio come un insegnante chiede allo studente di illustrare il procedimento per dimostrare di aver compreso un concetto durante un'interrogazione, anche i sistemi di intelligenza artificiale avranno tale capacità, spiegando le loro previsioni in base alla conoscenza del sistema.
L'importanza della provenienza dei dati
Un altro aspetto da osservare degli attuali modelli di intelligenza artificiale (non tutti ovviamente) è la potenziale provenienza dei dati di addestramento da fonti sulle quali non è possibile avere il controllo.
I sistemi di nuova generazione che si baseranno anche sui knowledge graph, potranno contare su una catena di provenienza dei dati, proprio come uno studente cita le fonti quando scrive un documento di ricerca. Questo consentirà di "controllare le fonti" ed il processo di ragionamento del sistema.
Se per determinate elaborazioni, ad esempio, si desidererà utilizzare esclusivamente delle fonti estremamente affidabili, la catena di provenienza consentirà al sistema di utilizzare soltanto i dati provenienti da tali informazioni.
L'AI sarà sempre più affidabile
Quando si utilizzano sistemi di intelligenza artificiale, probabilmente sarà sempre più importante non solo verificare la qualità delle previsioni, ma anche se si ha accesso alle fonti che hanno determinato il training dell'algoritmo.
L'era dei sistemi di intelligenza artificiale "black box" probabilmente è destinata a finire. Gli algoritmi di nuova generazione ottimizzeranno la capacità di spiegare le previsioni e l'affidabilità.
I grafi della conoscenza fungeranno da ingrediente chiave che renderà questi sistemi più spiegabili, ispezionabili, verificabili e, in definitiva, controllabili.
Per approfondire
 Mike Tung
Mike Tung
 Alessio Pomaro
Alessio Pomaro