Agents e Reasoners: dalla scala all'ottimizzazione.. fino all'integrazione
L’AI sta evolvendo oltre la semplice crescita della scala, puntando su efficienza e nuove architetture. Tecniche come la quantizzazione e il reasoning migliorano le prestazioni riducendo i costi. Gli AI Agents diventano centrali, trasformando i modelli in strumenti applicativi.


La recente storia dell'AI potrebbe essere sintetizzata in una sola parola: “SCALA”.
Così Noam Brown (Research Scientist di OpenAI) inizia il suo TED AI di San Francisco.
Quindi, performance = modelli sempre più grandi, addestrati da sempre più dati e con una potenza di calcolo necessaria sempre maggiore.
Agents e Reasoners - L'intervento integrale dall'AI Festival 2025
Le statistiche dimostrano questo aspetto: il diagramma che segue, infatti, mostra la crescita della potenza di calcolo necessaria per addestrare i modelli che utilizziamo abitualmente, con un incremento consistente in quella che viene definita "Deep Learning Era".
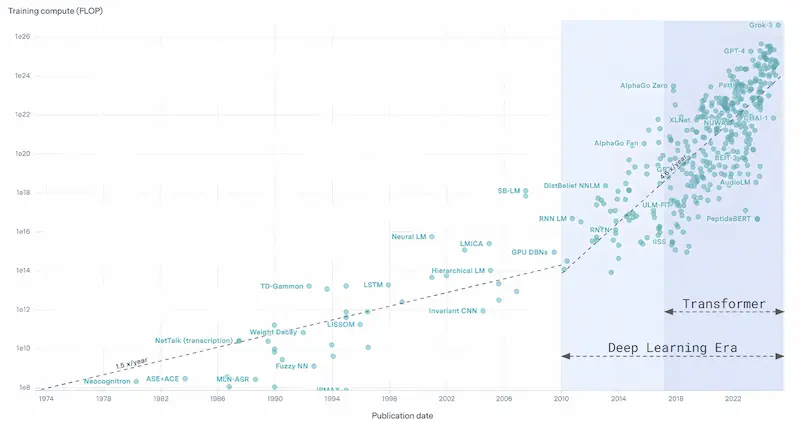
Ultimamente, però, sembra che la crescita di performance derivante direttamente dalla scala si stia attenuando. L’anno scorso, sul palco dell'AI Festival, dissi che il riferimento era ancora la serie di modelli GPT-4.. Oggi, un anno dopo, la situazione non è cambiata significativamente, ma i competitor, con modelli open source e non, hanno ridotto il gap.
Anche esperti influenti come Ilya Sutskever, hanno sottolineato questa attenuazione.

La stessa OpenAI ha nominato il nuovo modello GPT-4.5 e non GPT-5.. probabilmente perché non ha rappresentato un salto qualitativo degno di quel nome.
Anche Dario Amodei, CEO di Anthropic, in una recente intervista, ha affermato che Claude 3.7 è stato uno step evolutivo, ma non abbastanza da giustificare la versione "4".
Le leggi di scala e la sostenibilità
Si pone quindi una domanda cruciale: conviene ancora investire sulla scala? Per rispondere alla domanda ci sono due considerazioni da fare.
- Non è mai stato garantito che le leggi di scala sarebbero state valide per sempre: si tratta di osservazioni empiriche, regole statistiche e sperimentali.
- L'aumento della scala di altri ordini di grandezza comporterebbe costi e consumi di risorse enormi.
Questo avviene oggi, naturalmente. Sul futuro torneremo tra poco.
Fine della crescita o nuova fase?
Dunque, la crescita dell’AI è finita?
No, anzi, mi sento ancora di dire che siamo solo all’inizio.
Di certo si attenuerà l’investimento "cieco" sulla scala, a vantaggio di un maggiore interesse per l'efficienza, le architetture innovative e, soprattutto, l'integrazione.
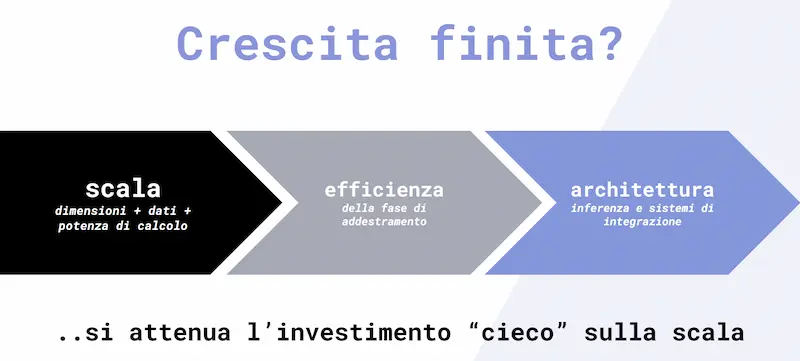
Efficienza: il nuovo paradigma
L'efficienza sta diventando una delle chiavi dello sviluppo futuro. Un ottimo esempio di questo è il paper di DeepSeek R1, che non introduce elementi rivoluzionari dal punto di vista architetturale (è un modello basato su transformer e reinforcement learning in fase successiva), concentrandosi però sull’efficientamento, cioè sulla capacità di ottenere performance elevate con meno risorse durante la fase di training.
La crescita dell'open source
In generale, i miglioramenti che stiamo osservando nei modelli open-source, ad esempio DeepSeek R1, QwQ-32B di Qwen (Alibaba), Ernie 4.5 e X1 (Baidu), permettono di ragionare su tecniche come la quantizzazione e la distillazione, che riducono significativamente le dimensioni dei modelli mantenendo elevate performance. Questo permette anche di far funzionare i modelli in dispositivi con hardware limitati.
Nel video seguente, ad esempio, è possibile vedere DeepSeek R1 funzionare sul mio laptop. Si tratta della versione 8B, basata su architettura Llama, con quantizzazione a 4 bit (Q4_K_M).
DeepSeek R1 in locale: un test sul mio laptop
E stanno nascendo nuove tecniche come MatQuant di Google DeepMind, che mette in azione una quantizzazione multi-scala che sfrutta la struttura nidificata degli interi per ottimizzare modelli a diverse precisioni (int8 → int4 → int2) mantenendo un’accuratezza elevata.
Architettura: "reasoning" e AI Agents
Noam Brown, che in OpenAI si occupa proprio di multi-step reasoning e multi-agent AI, durante il talk citato in precedenza ha raccontato un'esperienza del suo dottorato di ricerca, dicendo che permettere a un modello di "pensare" per 20 secondi (dove per pensare intende un’esecuzione lenta, step by step) ha generato un miglioramento delle prestazioni equivalente a un aumento della scala di ben 100.000 volte.

Ecco perché oggi stiamo assistendo a un rilascio costante di modelli basati sulla dinamica di “reasoning” o “thinking”. Alcuni esempi: la serie o1 e o3 di OpenAI, Gemini, DeepSeek, Claude, QwQ di Qwen, e Grok. E anche GPT-5 sarà basato su questo concetto.
Come funziona il "reasoning"? Il modello, prima di produrre l’output produce dei token dedicati a sviluppare catene di pensiero (o di ragionamento), con lo scopo di migliorare la qualità dell’inferenza. Quello che segue è un esempio in cui possiamo vedere la fase di reasoning di QwQ-32B nella chat di Qwen.
Un test di QwQ-32B nella chat di Qwen
E questo concetto di miglioramento della qualità dell’inferenza, non vale solo per i Large Language Model. "Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps", ad esempio, è un paper di Google DeepMind che dimostra come, lavorando sull’ottimizzazione della del processo di diffusione, sia possibile migliorare la qualità della generazione delle immagini senza agire sulla scala.
Latent Reasoning
Esistono già idee di sviluppo ulteriori in ambito di "reasoning". Il paper dal titolo "Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach", ad esempio, descrive un approccio per il quale il processo di "ragionamento" non avviene attraverso la generazione di token di reasoning (quindi catene di pensiero esplicite), ma all’interno dello spazio latente del modello.. ovvero prima dell’inferenza, attraverso calcoli vettoriali.
Il ruolo crescente degli AI Agents
Un ulteriore ambito di grande sviluppo, sempre in ambito dell'evoluzione dell'architettura, riguarda gli AI Agents. Ma arriviamoci partendo da due considerazioni sullo scenario che stiamo vivendo..
- In questo momento abbiamo una grande ricchezza di modelli performanti, sia open source, sia "chiusi": possiamo dire, con una dose di semplificazione, che le prestazioni stanno convergendo, e i modelli andranno ad equipararsi.
- I prezzi per token, nel tempo, stanno scendendo in modo importante. E credo che nei prossimi anni si arriverà a zero. A questo proposito, ad esempio, Baidu ha recentemente rilasciato la versione 4.5 di Ernie, che costa la metà di DeepSeek e un infinitesimo di GPT-4.5.
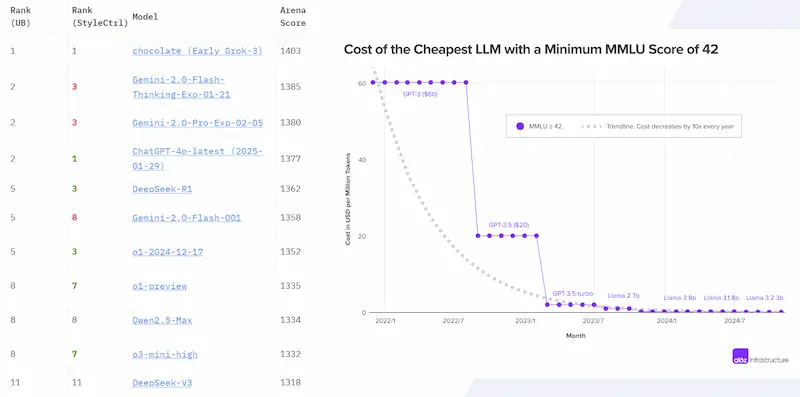
Questa situazione, in cui i LLM si equiparano e il prezzo per token diventa trascurabile, fa sì che l'attenzione si sposti dai modelli a quello che possiamo definire "layer applicativo" (applicazioni basate sui modelli).. e gli AI Agents sono proprio quel layer applicativo.
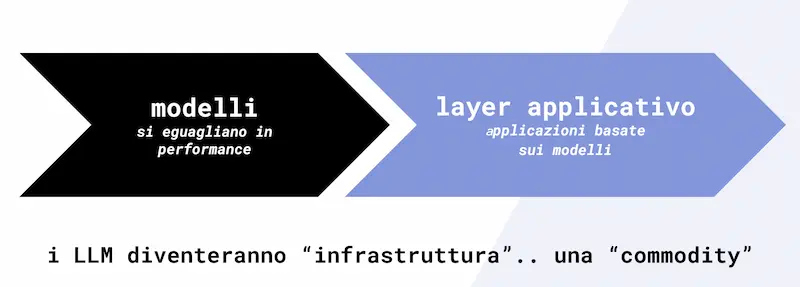
I LLM, in un certo senso, diventeranno parte dell’infrastruttura, una sorta di commodity che permette di dare vita alle applicazioni del futuro.
Struttura e vantaggi degli AI Agents
Un AI Agent presenta una struttura composta principalmente da un modello, un sistema di orchestrazione (che ne determina il comportamento, la metodologia nella pianificazione delle operazioni, e può essere dotato di memoria per migliorare e personalizzare le performance nel tempo), e l'interfacciamento con tool esterni per eseguire azioni specifiche.
Lo schema che segue, che deriva dal paper di Google dal titolo "Agents", sintetizza in modo esaustivo l'architettura.
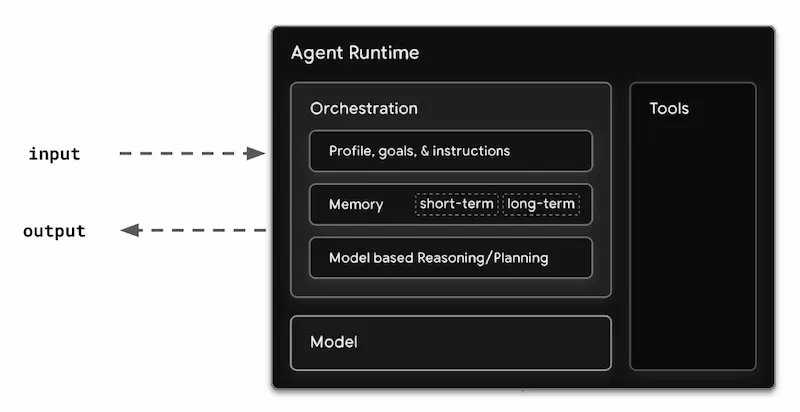
Mella prenotazione di un volo, ad esempio, un utente può interagire con un agent specializzato che processa la richiesta, orchestra i processi, interroga i servizi esterni, e restituisce una risposta completa e contestualizzata.
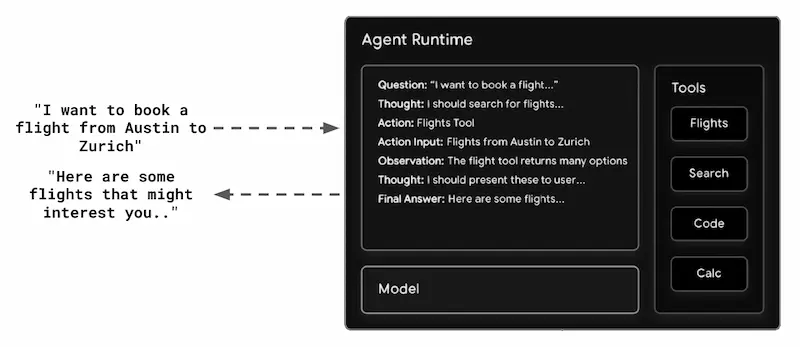
Rispetto a un'interazione diretta con un LLM una struttura di questo tipo ha diversi vantaggi, ad esempio:
- accesso a dati in tempo reale;
- memoria e personalizzazione;
- ragionamento avanzato;
- maggiore affidabilità;
- scalabilità e automazione.
Framework e workflow agentici
Nel prossimo futuro, potremo creare sempre più facilmente AI Agents sfruttando dei framework. Parallelamente, le piattaforme metteranno a disposizione agenti per ogni funzionalità. Google, ad esempio, sta lanciando l’Agent Space e Microsoft il Copilot Studio. E abbiamo già iniziato a usare sistemi basati su agenti, ad esempio Operator di OpenAI, Deep Research, e OmniParser di Microsoft.
Framework come Autogen, Crew AI e Lang Graph, invece, permettono di creare agenti e workflow agentici per creare sistemi di automazione.
OpenAI, a questo proposito, ha appena rilasciato nuovi strumenti dedicati allo sviluppo di AI Agents personalizzati e sistemi multi agente. Nello specifico:
- Responses API – L’API per la costruzione di agenti, che combina la semplicità della Chat Completions API con le capacità di utilizzo degli strumenti dell’Assistants API. Con una singola chiamata, gli sviluppatori possono orchestrare più strumenti e modelli, rendendo gli agenti più intelligenti e operativi.
- Agents SDK – Un framework open-source per orchestrare gli agenti e gestire flussi di lavoro complessi. Grazie a questo strumento, gli sviluppatori possono creare agenti che collaborano tra loro con handoff intelligenti, tracciamento avanzato e guardrail di sicurezza integrati.
Andrew NG, riferendosi agli AI Agent, afferma addirittura che i workfow basati su AI Agent guideranno il prossimo sviluppo dell’AI più della prossima generazione di foundation models.

Online troviamo diversi schemi di workflow agentici, più o meno teorici. Con il mio team, stiamo realizzando una sperimentazione con Alpinestars in cui usiamo un workflow multi-agent per ottenere traduzioni di alcuni contenuti dell’e-commerce in 9 lingue. Il seguente video mostra un'esempio di interazione.
Un sistema multi agent per generare traduzioni di qualità
Come funziona?
- I dati da tradurre vengono estratti dal database e consegnati da un agente proxy al team di lavoro.
- Nel "team virtuale" sono presenti diversi agenti traduttori esperti del dominio, ma con verticalità diverse, i quali si confrontano ottimizzando la traduzione ad ogni interazione, migliorando i termini utilizzati, la forma, ecc..
- Il lavoro passa a un agente SEO Specialist, che, accedendo anche a dei tool di analisi delle ricerche degli utenti, suggerisce al team l’utilizzo di determinati termini.
- Un agente specializzato nell'inserimento di link nei contenuti, sfruttando la conoscenza dell’e-commerce, inserisce nel testo tradotto dei link strategici verso le categorie più interessanti.
- Un agente editor manager produce la revisione finale ottimizzando l'output (ad esempio, togliendo eventuali ripetizioni e migliorando le forme di espressione nella lingua di destinazione).
- Infine, l'agente team leader consegna l’output che viene salvato nel database.
Il sistema è stato realizzato usando Autogen come framework, mentre gli agenti sono basati su modelli di OpenAI. Alcuni sfruttano anche il reasoning di o3-mini.
Quali sono i vantaggi di un sistema come questo?
- Specializzazione e collaborazione: ogni agente è verticale in un'attività e collabora con gli altri per migliorare l’output.
- Scalabilità e flessibilità: per aggiungere ulteriori funzionalità al sistema, è sufficiente aggiungere uno o più agenti con specifiche capability.
- Robustezza e affidabilità: nel workflow possiamo avere agenti dedicati al controllo dei flussi e dell'output. Nell'esempio, l'agente "editor manager" e "team leader" hanno proprio questa funzione.
I sistemi agentici si stanno evolvendo rapidamente, e iniziamo a vedere applicazioni interessanti. Un esempio è AI co-scientist di Google: un sistema multi agent basato su Gemini 2.0 che genera ipotesi, pianifica esperimenti e migliora in modo iterativo i risultati, fungendo da collaboratore virtuale per i ricercatori.
Stanno nascendo, inoltre progetti come Manus. Si tratta di un nuovo AI agent "generale" in grado di eseguire compiti attraverso la pianificazione e azioni autonome, il tutto attraverso l'interazione multimodale di un LLM con un computer.
La presentazione di Manus
Nel seguente esempio, invece, un agent (Operator di OpenAI) gestisce un altro agente su Replit per sviluppare un’applicazione in modo autonomo. In questo caso, non abbiamo un framework che gestisce gli agenti, ma si tratta di un'interazione multimodale via browser.. esattamente come farebbe un essere umano.
Operator di OpenAI che controlla l'agente di Replit
Quando ho visto questa interazione, ho pensato a un talk interessante che ho visto recentemente: quello del CEO di Nvidia al CES di Las Vegas.
Nell'intervento, viene mostrata una traiettoria che unisce l'AI Generativa all'AI Agentica, fino ad arrivare all’AI Fisica: un’AI che interagisce direttamente con il mondo reale, trovando applicazioni, ad esempio, in ambito della robotica.
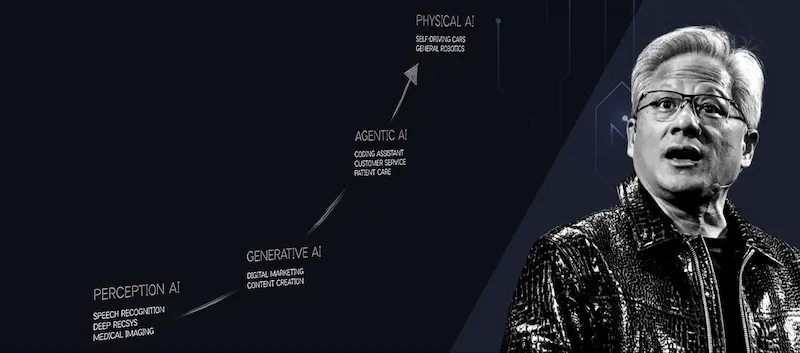
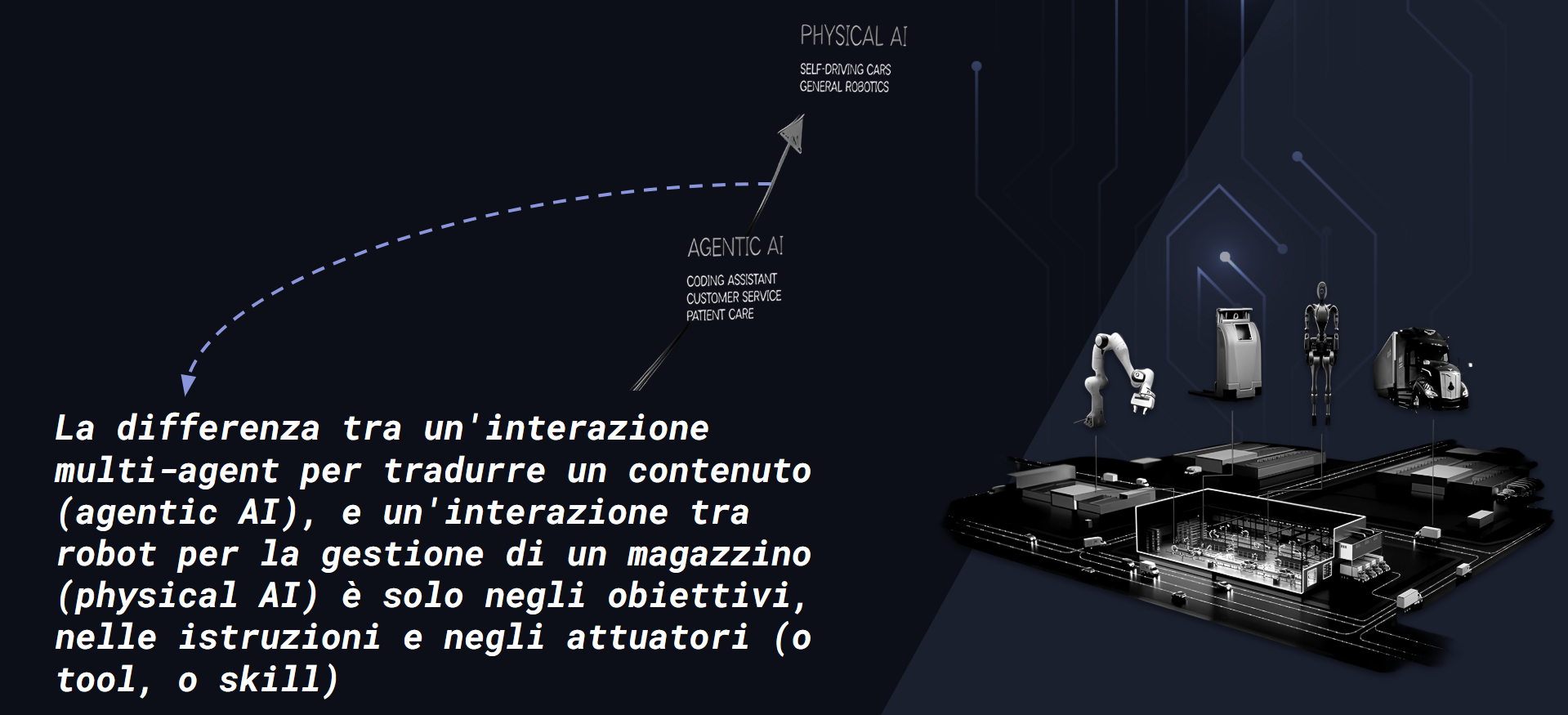
Questo passaggio fa capire molto bene un aspetto del quale si parla troppo poco.. o forse non se ne parla affatto:
La differenza tra un workflow multi-agent in grado di produrre una traduzione di qualità (AI Agentica), e un workflow multi-agent in grado di controllare dei robot che gestiscono un magazzino (AI Fisica) non è poi così marcata: cambiano gli input, cambiano le istruzioni di orchestrazione, cambiano i tool a disposizione, che da digitali diventano fisici.. ma l'architettura del sistema è praticamente la stessa.
Per sottolineare ulteriormente questo concetto, Google DeepMind ha recentemente rilasciato Gemini Robotics: un modello basato su Gemini 2.0 (lo stesso che usiamo nella chat!) con l'aggiunta di "azioni fisiche" come tipologia di output allo scopo di controllare direttamente i robot.
Gemini Robotics: un esempio di applicazione
Il robot nel video, è controllato dallo stesso modello che usiamo nella chat di Gemini.
Credo che il passaggio all'AI fisica renderà molto più tangibile per tutti il progresso di questi sistemi, perché traccerà lo switch di pensiero da considerarli "giochini che scrivono testo in una chat" a "robot che ci affiancheranno in qualunque mansione".
Chi si ricorda il meme "Hey ChatGPT, finish this building.."?

Gli sviluppi futuri: modelli e hardware
Abbiamo visto il passaggio dalla "scala" all'efficienza e al miglioramento architetturale.. Ma tutto questo significa che l’evoluzione dei modelli si fermerà? Assolutamente no: stanno emergendo già nuovi approcci e tecnologie avanzate da questo punto di vista.
Allo stesso modo, anche l’hardware continuerà a evolversi rapidamente, come dimostrato da Nvidia al CES 2025:
ormai possiamo avere un supercomputer delle dimensioni di un laptop.
Forse, un giorno, potremo avere la potenza di calcolo, i dati sintetici e l’efficienza necessari per tornare a ragionare sulla scala.. e magari ci accorgeremo che le leggi di scala sono sempre state valide.
Non possiamo sapere come andrà, ma la direzione sembra chiara, e la scopriremo insieme.. Ma sempre più attenti, sempre più critici, sempre più consapevoli..
Ma dovremo lavorare con impegno per acquisire queste qualità, attraverso studio, ricerca, sperimentazione, e un approccio flessibile.

Buon percorso.
- GRAZIE -
Se hai apprezzato il contenuto, e pensi che potrebbe essere utile ad altre persone, condividilo 🙂