12 spunti per il 2025 sull'evoluzione dell'AI
Prendendo spunto dalle innovazioni presentate da OpenAI nei 12 giorni di live prima delle festività, vediamo altrettanti spunti e riflessioni sulle evoluzioni dell'AI che ci portano al 2025.


Si sono recentemente conclusi i "12 Days" di OpenAI: dodici giorni di live streaming in cui il brand ha presentato le innovazioni e le nuove features sviluppate nell'ultimo periodo.
In questo contenuto li ripercorreremo insieme, ma con l'aggiunta di riflessioni e spunti che riguardano lo sviluppo dell'Intelligenza Artificiale nel prossimo futuro.
1) Dall'aumento della scala al miglioramento della qualità dell'inferenza
Con il "Day 1", e il rilascio di o1 "full" e "Pro", OpenAI continua il percorso del miglioramento delle performance dei modelli guidato dall'aumento della qualità dell'inferenza.
o1 è migliore, più veloce, multimodale, adattivo, e non solo dedicato a task di calcolo.
Day 1 di OpenAI: o1 e oi Pro
La recente storia dell’AI può essere riassunta in una parola: scala. Ovvero performance = modelli sempre più grandi e che necessitano di potenza di calcolo sempre maggiore. Sistemi come 01 dimostrano che non si tratta più dell'unico percorso di crescita.

Come funzionano questi sistemi? Quando il modello riceve il prompt in input, prima di dare la risposta, produce una serie di token di reasoning. In pratica, è addestrato per sviluppare catene di pensiero, in cui analizza il problema passo dopo passo, fa diverse ipotesi e le confronta; infine, dopo questi step, genera l'output con una qualità superiore.

Anche Google sta evolvendo i suoi modelli in questa direzione. Recentemente, infatti, ha rilasciato Gemini 2.0 Flash Thinking su AI Studio, che funziona anche su task con input multimodale.
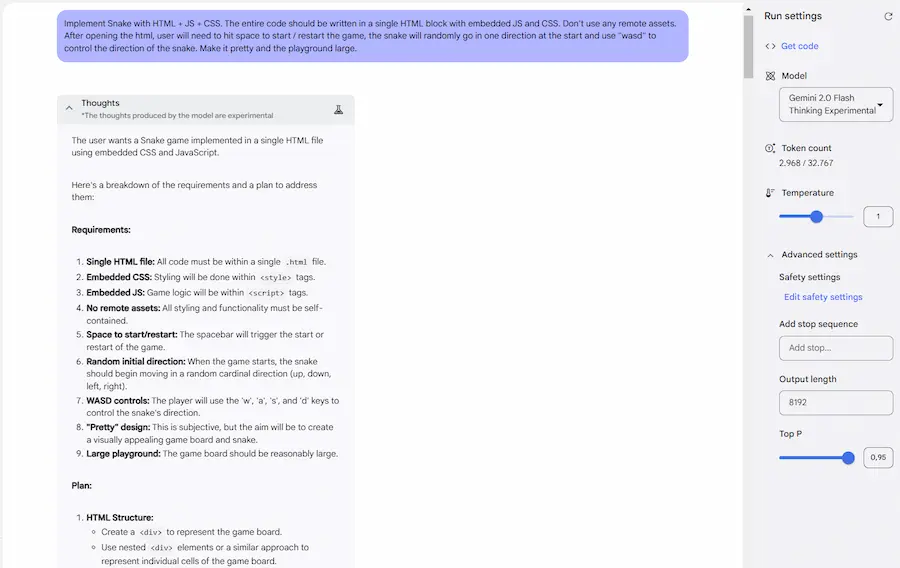
Un esempio di Gemini 2.0 Flash Thinking
Il potenziale di questi sistemi, unito ad architetture multi-agente in cui i "reasoner" guidano le azioni dei singoli agenti, porterà ad applicazioni davvero interessanti.
Qualche giorno fa, ho realizzato un software di questo tipo usando Autogen di Microsoft come framework, in cui diversi AI agent collaborano per fare una predizione su un dataset.
Gli agenti sono basati su GPT-4o e o1. Creano un piano d'azione autonomamente, sviluppano il codice necessario installando le librerie che mancano, lo eseguono correggendo eventuali errori fino ad arrivare all'output.
Il sistema valuta anche le performance e modifica la rete neurale che si occupa della predizione in modo da ottimizzarla.
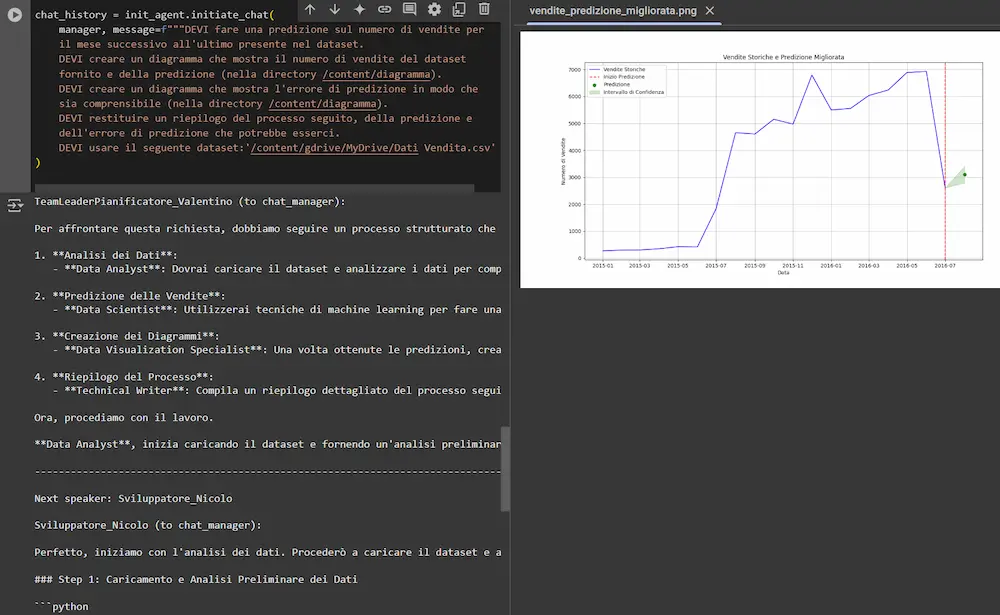
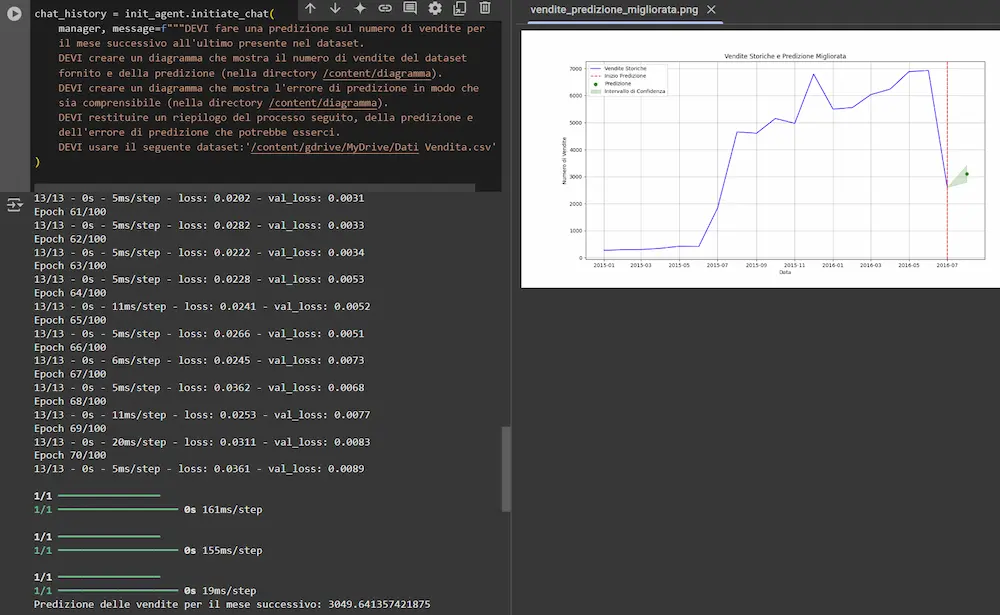
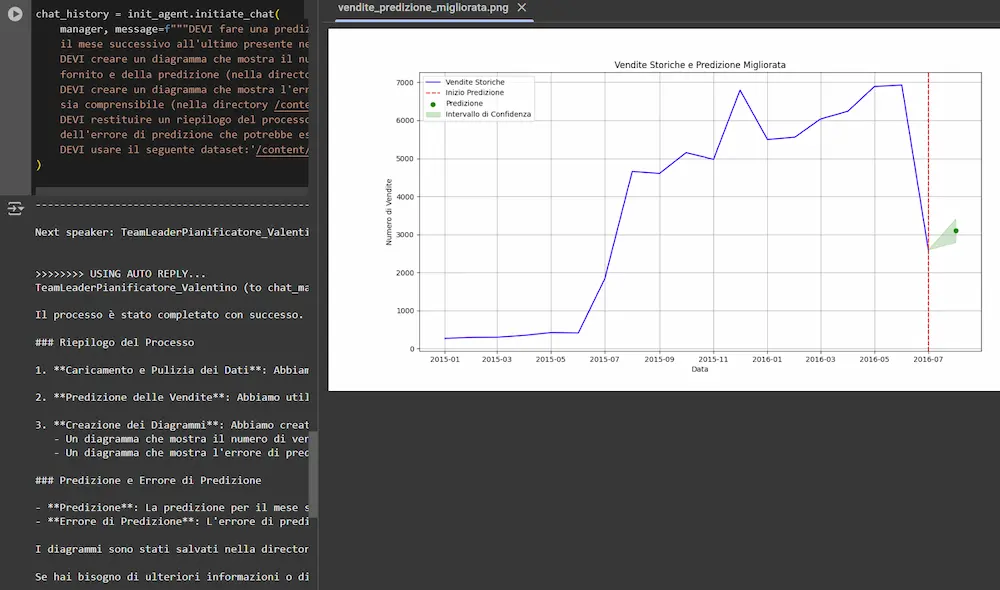
Sistema multi-agent che genera una prediction su un dataset
Mi aspetto un framework multi-agent da OpenAI, che vada oltre al progetto Swarm.
2) Migliora la capacità di generalizzazione dei modelli di linguaggio
Il "Day 2" di OpenAI è il giorno del Reinforcement Fine-Tuning (RFT), applicato ai modelli o1.
Day 2 di OpenAI: Reinforcement Fine-Tuning (RFT)
Mentre il fine-tuning si limita a fornire dati al modello, addestrandolo a imitarli (miglioramento di tono, stile, formato), il Reinforcement Fine-Tuning punta ad aumentare la capacità di generalizzazione: il modello riceve un dataset di training, e successivamente prova a risolvere un problema ricevendo un punteggio (dal grader) per la qualità della risposta.
Se la risposta è corretta, viene premiato, altrimenti viene "scoraggiato" a perseguire quella linea di ragionamento.
Questa nuova funzionalità mira a migliorare la capacità dei modelli di affrontare compiti complessi e specifici.
Nuove architetture che aumentano la precisione e la qualità dell'inferenza, addestrando i modelli a compiere un "ragionamento" in modo migliore.
3) La qualità degli output multimediali aumenta, creando strumenti potenti per i content creator
Il "Day 3" di OpenAI è il giorno di Sora, il tanto atteso modello per la generazione di video.
Si tratta di una nuova piattaforma disponibile su sora.com, in grado di creare video (da 5 a 20 s, e da 480p a 1080p) attraverso prompt testuali e immagini statiche, di editare e mixare video con stili diversi e di estenderli in entrambe le direzioni.
Day 3 di OpenAI: Sora
La funzionalità "storyboard" è quello che mancava per questi sistemi: permette di dirigere video complessi con una sequenza di azioni sulla timeline, e con transizioni fluide.
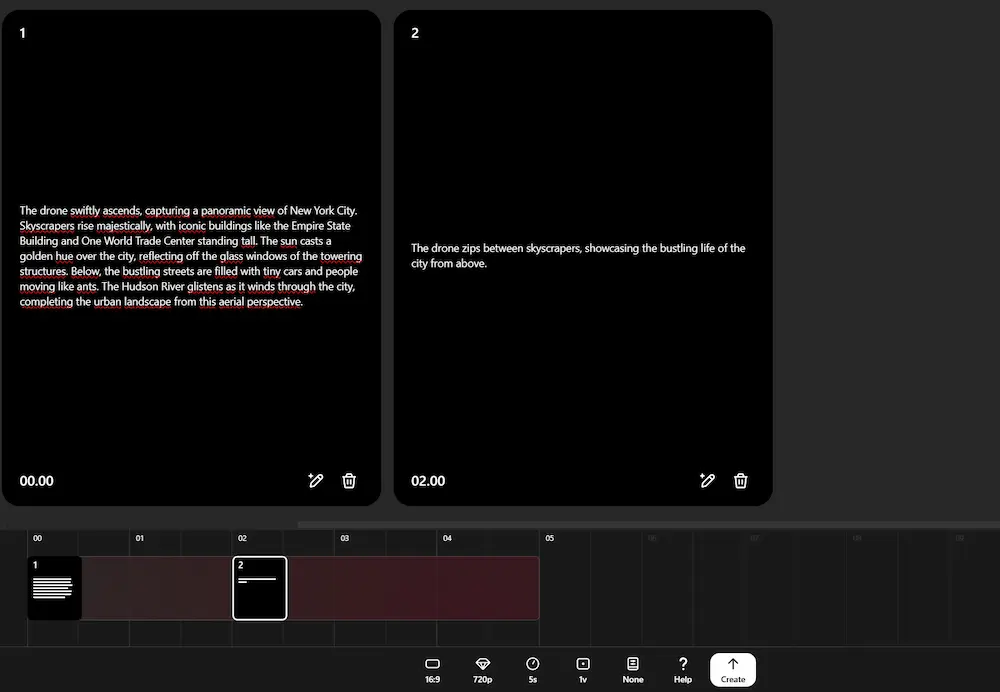
Il video che segue, mostra un esempio di video che ho generato attraverso lo storyboard che si vede nell'immagine precedente, e successivamente modificato con la funzione "Remix", che permette di modificare degli elementi in un video attraverso prompt testuali.
Un esempio della funzionalità "Remix" di Sora
Sora è già usabile negli USA e in altri paesi non specificati nella presentazione, ma è stato sottolineato che per Europa e UK ci vorrà del tempo.
Il modello viene distribuito in versione limitata (video, qualità, durata, filigrana) per gli abbonati ChatGPT, con funzionalità complete per gli abbonati Pro.
Sicurezza: i video vengono contrassegnati da una filigrana e da metadati C2PA. In fase di caricamento delle immagini che fanno da driver per i video, inoltre, l'utente deve dichiarare che si tratta di materiale che non riguarda minorenni, contenuti espliciti o violenti, e materiale protetto da copyright.
Dopo il lancio di Sora, Google ha annunciato Veo 2, che dimostra una qualità impressionante, con la capacità di generare video in 4k.
Esempi di video generati attraverso Veo 2 di Google
Anche Pika ha lanciato la versione 2.0 del suo modello, introducendo (in risposta allo Storyboard di Sora) uno strumento per una generazione di video più controllata, chiamato "Scene Ingredients".
Scene Ingredients di Pika 2.0
E non poteva mancare la risposta di Runway, che introduce i fotogrammi chiave intermedi per Gen-3. Si tratta di un sistema per passare facilmente da una scena all'altra avendo maggior controllo della creazione, che ormai è l'obiettivo principale di questi strumenti.
Video generato attraverso Runway Gen-3 e i fotogrammi chiave intermedi
La qualità di questi modelli non stupisce più. Quello che stupisce è come stanno diventando (con una forza sempre maggiore) degli strumenti chiave per i content creator.
4) L'evoluzione degli editor con LLM per una co-creazione sempre migliore
Il "Day 4" è il giorno dell'evoluzione di Canvas.
Day 3 di OpenAI: Canvs
Vediamo le tre innovazione più interessanti.
- La possibilità di portare qualunque testo su Canvas, anche semplicemente copiandolo e incollandolo da un file (prima era necessario eseguire un prompt per aprire l'interfaccia).
- L'esecuzione del codice. È possibile lavorare sul codice ed eseguirlo direttamente su Canvas. Il sistema può mostrare la console degli errori (con la possibilità di fixare), e l'output (testo e diagrammi).
Questa funzionalità è carina, ma, dopo alcuni test, ho delle perplessità. Che tipo di codice può essere eseguito in un ambiente come questo? Senza la possibilità di avere un dataset a disposizione, né accesso esterno.. Certo, poche righe di Python con dati simulati, ma non qualcosa di più strutturato. - Le nuove features che permettono ai GPTs custom di lavorare direttamente su Canvas, sia con il testo, sia con lo sviluppo di codice.
Gli editor dotati di assistenti basati
sui LLM sono una realtà consolidata.
Anche Anthropic ne ha una versione nel suo Artifacts, e abbiamo Gemini integrato su Colab. Tra le innovazioni più interessanti troviamo Spark di GitHub (oltre a Copilot), che permette di creare micro-applicazioni web utilizzando il linguaggio naturale, rendendo lo sviluppo accessibile anche a chi ha competenze di programmazione meno avanzate. Parallelamente, Replit ha sviluppato AI Agent, una piattaforma che guida l'utente nella generazione e distribuzione di applicazioni complete, riducendo significativamente i tempi di sviluppo e abbassando la barriera d'ingresso per la creazione di software.
5) L'integrazione negli ecosistemi
Il "Day 5" è il giorno dell'integrazione con Apple Intelligence.
ChatGPT è ora integrato in iOS, iPadOS e macOS. Siri, ad esempio, può passare le richieste a ChatGPT quando servono risposte più complesse. Può contribuire alla scrittura e all'analisi di documenti, e si integra con la fotocamera per analizzare elementi visivi.
Day 5 di OpenAI: Apple Intelligence
Una dimostrazione di agenti collaborativi integrati negli ecosistemi. Cosa che sta dimostrando anche Google con Gemini 2.0.
6) La multimodalità e l'interazione uomo-macchina
Il "Day 6" è il giorno del potenziamento dell'Advanced Voice Mode.
La funzionalità permette di conversare con ChatGPT usando video dal vivo e condivisione dello schermo: un'interazione con l'assistente in tempo reale per ricevere aiuti pratici.
Day 6 di OpenAI: Advanced Voice Mode
Quelli che seguono sono alcuni miei test della modalità, che purtroppo non è ancora disponibile in Italia (ho usato una VPN).
Advanced Voice Mode di ChatGPT con video in real-time
Nel frattempo anche Microsoft ha rilasciato Copilot Vision, che permette un'esperienza di navigazione collaborativa, con l'assistente che può "vedere" lo schermo in tempo reale dando suggerimenti e interagendo con l'utente attraverso la voce.
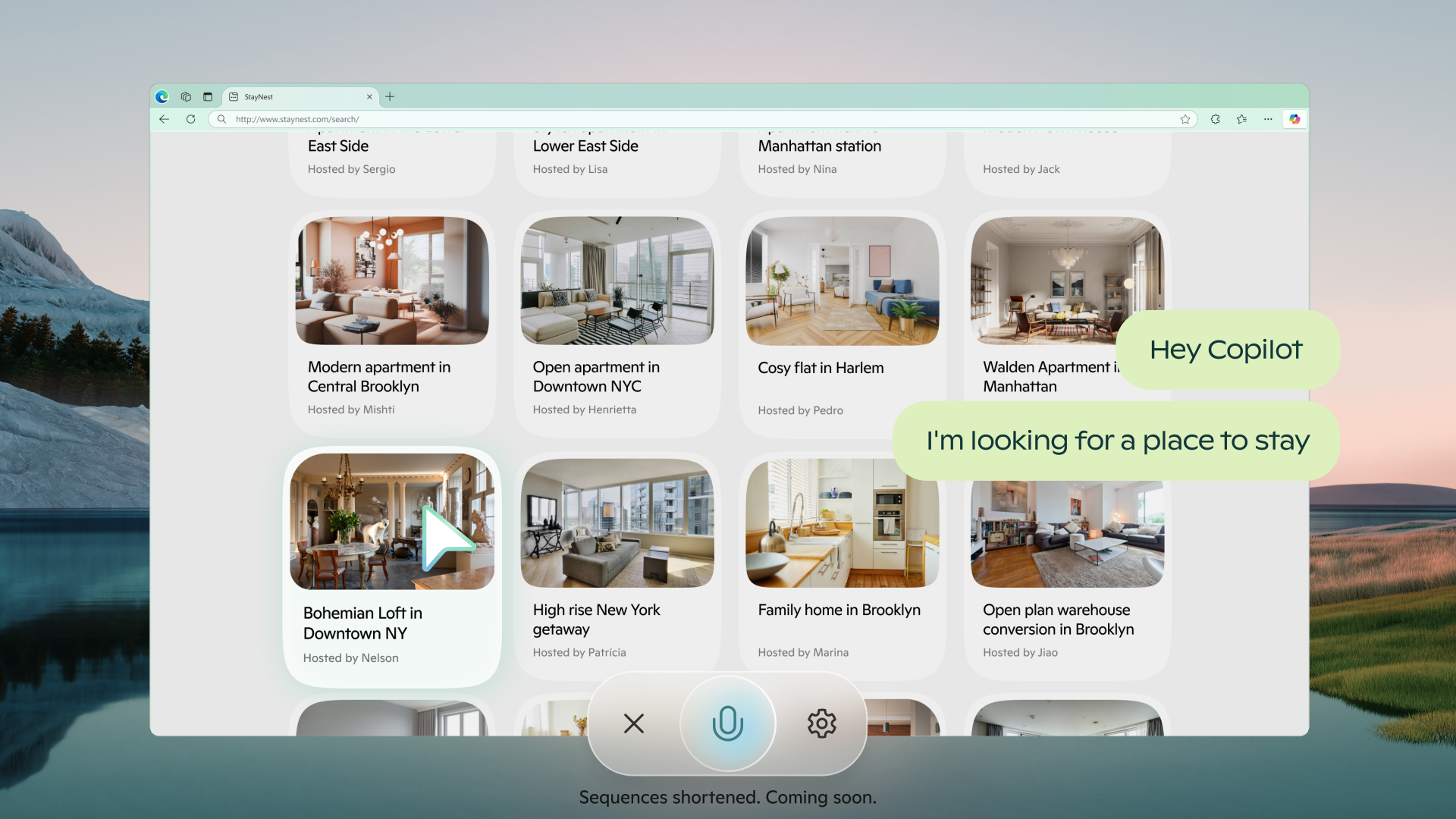
Google, procedendo nella stessa direzione, ha reso disponibile l'interazione multimodale con Gemini 2.0, con la possibilità di dialogare con l'assistente attraverso la voce, condividendo anche la camera del dispositivo e lo schermo.
Nel video che segue, una mia demo, in cui lavoro a schermo condiviso e uso la voce per comunicare con il modello (il sistema è usabile su Google AI Studio).
Gemini 2.0: un esempio di utilizzo con schermo condiviso e voce
Problemi con la lingua a parte, si tratta di un'esperienza davvero interessante, e fa capire il potenziale di questa tecnologia.
L'interazione multimodale è ormai a un livello di qualità importante, e migliorerà. Se due anni fa eravamo in preda alla delusione per Alexa e Google Assistant, oggi iniziamo a intravedere una nuova possibilità.
7) Migliora l'organizzazione dei progetti all'interno delle piattaforme
Il "Day 7" è il giorno dei progetti (Projects) su ChatGPT.
Si tratta di un sistema di organizzazione delle chat, che permette di raggrupparle e di centralizzare system prompt e l'utilizzo di file.
Day 7 di OpenAI: Projects su ChatGPT
Tutte le chat del progetto, in pratica, hanno nel contesto le istruzioni e i file di riferimento.
Le piattaforme non sono più solo interfacce in cui è possibile usare un LLM "one-shot", ma strumenti di organizzazione del lavoro.
8) L'ascesa dei sistemi ibridi che integrano un modello di linguaggio al motore di ricerca
Il "Day 8" è il giorno dell'ottimizzazione della Search di ChatGPT.
Più veloce, migliorata da mobile e integrata con mappe interattive.
Day 8 di OpenAI: Search di ChatGPT
Anche l'Advanced Voice Mode è stata dotata della ricerca, eliminando il gap con Gemini Live su questo aspetto.
Perplexity, nel frattempo, fa notevoli passi in avanti, introducendo lo Shopping e il Merchant Program, attraverso il quale i brand possono mettere a disposizione il feed dei loro prodotti, per generare esperienze utente come quelle che si possono vedere nel seguente video.
L'esperienza di shopping con Perplexity
Anche Google introduce diverse novità in questo ambito, portando AI Overviews su Google Shopping (negli USA), e la Search su Gemini Advanced.
Nel video che segue, si può vedere un esempio della SERP di Google Shopping statunitense con AI Overviews.
AI Overviews su Google Shopping (SERP USA)
Quello che segue, invece, è un mio test della Search su Gemini Advanced, testabile selezionando "1.5 Pro with Deep Search" come modello.
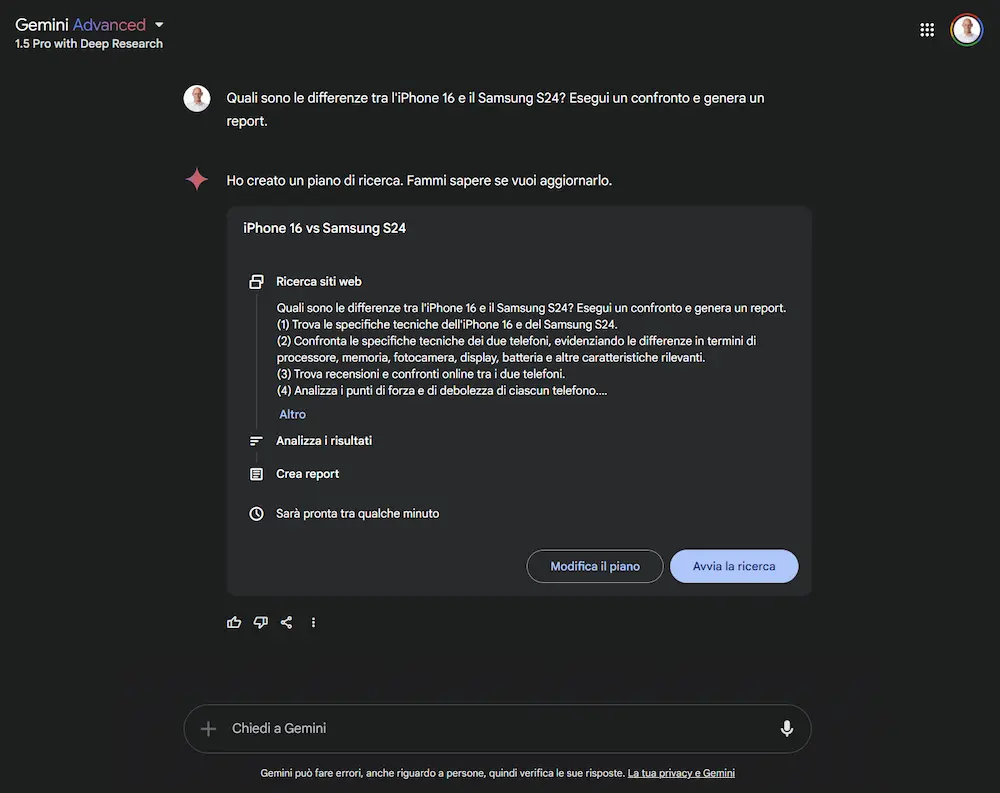
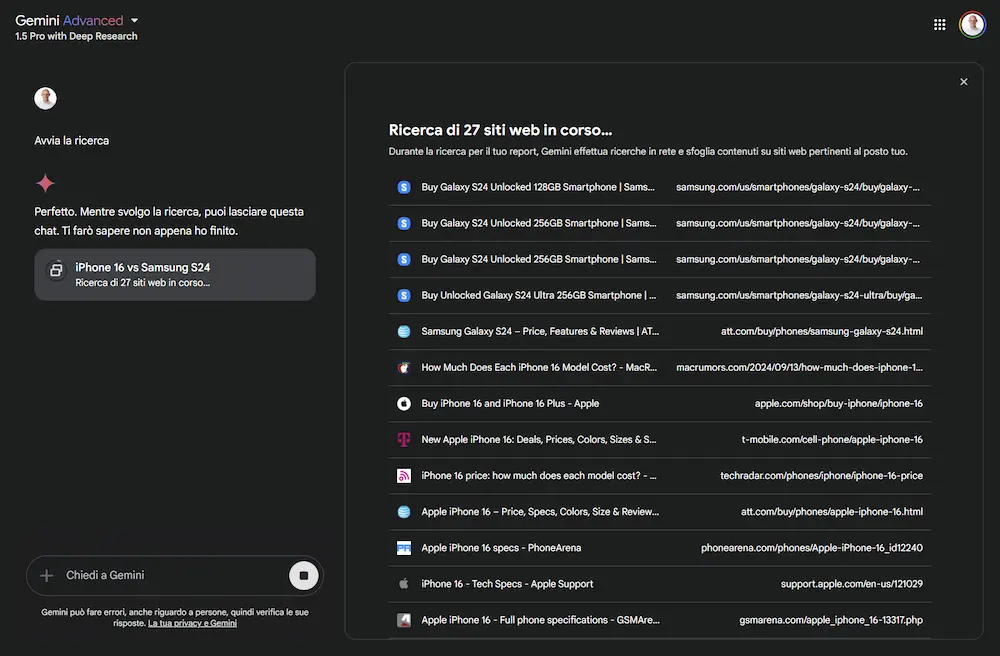
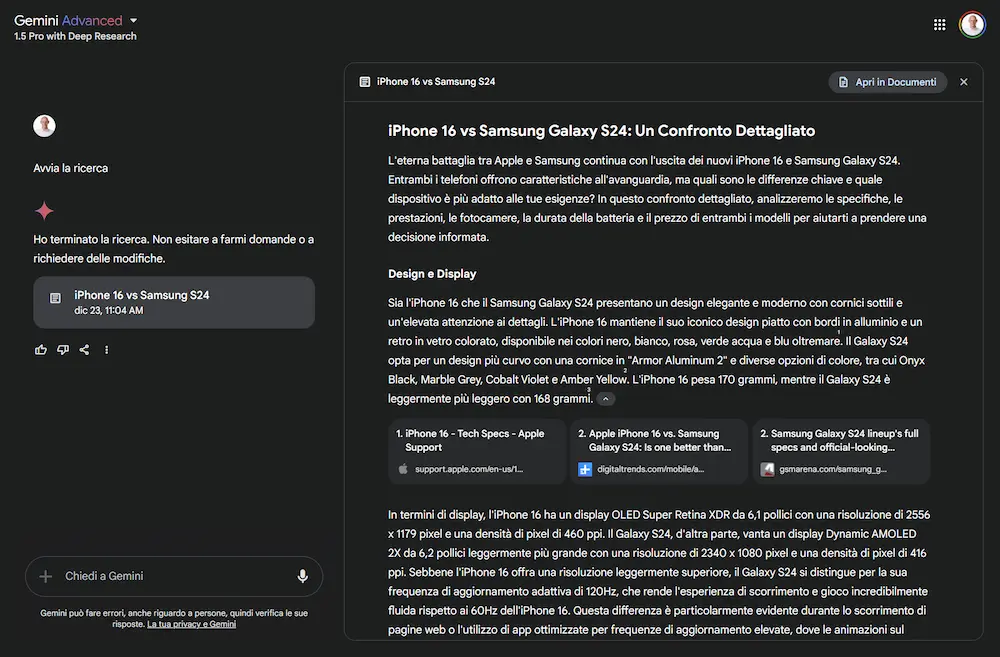
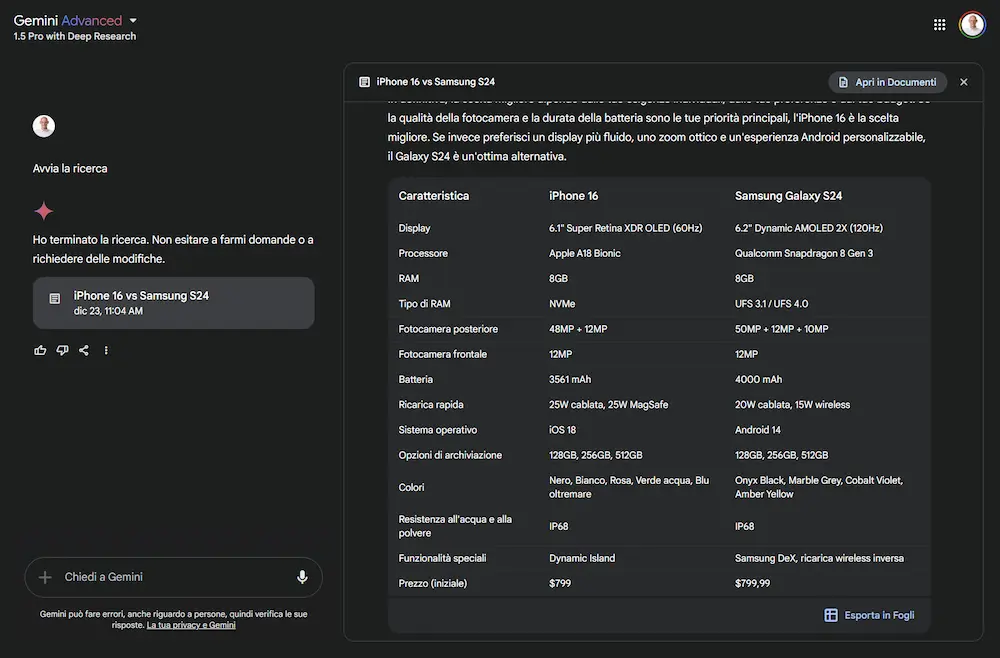
Un esempio della Search di Google integrata su Gemini
Ho posto una query di confronto tra due modelli di smartphone. Il sistema crea un piano di ricerca e lo esegue estraendo le fonti, e genera un output completo del confronto. L'output è visualizzabile di Google Docs e le tabelle su Spreadsheet. L'esperienza non è veloce, ma il risultato è molto interessante.
Un aspetto degno di nota: questa modalità è a disposizione anche via API attraverso la funzionalità definita "grounding con la Ricerca Google", per rendere le risposte di Gemini più affidabili.
I sistemi ibridi composti da un motore di ricerca e un LLM si stanno candidando a diventare una nuova modalità di consultazione delle informazioni disponibili online. E saranno completi quando avranno a disposizione i dati strutturati messi a disposizione dai brand (es. il feed dei prodotti degli e-commerce).
9) Le API diventano più performanti e l'integrazione si semplifica
Il "Day 9" è il giorno dedicato agli sviluppatori.
Le novità: o1 disponibile via API con function calling, output JSON e con un consumo di token di reasoning inferiore del 60% rispetto al modello in preview. Sono stati introdotti anche i "Developer Messages" (consentono di guidare meglio l'output senza interferire con le istruzioni degli utenti) e il "Reasoning Effort", per gestire il tempo di reasoning. È stato migliorato il supporto WebRTC, per conversazioni vocali a bassa latenza con integrazione semplificata anche su device fisici.
Day 9 di OpenAI: novità per i developers
È stato introdotto un nuovo metodo di fine-tuning: il Direct Preference Optimization (DPO). Invece di fornire al modello una singola risposta ideale, si forniscono coppie di risposte in cui una è preferita rispetto all’altra. L’addestramento si basa sull’apprendimento delle differenze tra risposte preferite e non preferite.
Queste tecnologie sono sempre più "controllabili" attraverso nuovi metodi di fine-tuning, e sempre più integrabili in modo semplice su applicazioni e dispositivi di qualunque genere.
10) Raggiungere l'utente, indipendentemente dalla tecnologia
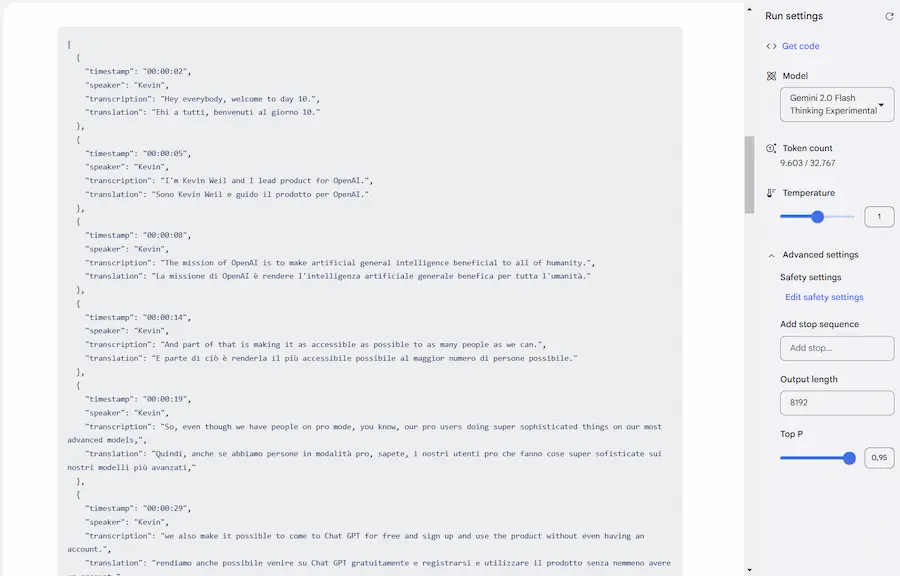
Il "Day 10" è dedicato alle chiamate vocali e WhatsApp. Negli USA è attivo un numero telefonico al quale risponde la Voice Advanced Mode di ChatGPT, con la quale è possibile interagire.
Day 10 di OpenAI: telefono e WhatsApp
In tutto il mondo, è possibile "chattare" con ChatGPT via WhatsApp.
Il tentativo?
Raggiungere qualunque utente, indipendentemente dalla tecnologia a disposizione.
11) L'interazione con le applicazioni
OpenAI si muove verso la creazione di un assistente che interagisce con le applicazioni e "compie azioni per conto dell'utente".
Il "Day 11" è il giorno del potenziamento dell'app desktop per MacOS (e a breve per Windows).
Day 11 di OpenAI: work with apps
Le azioni vanno dall'automazione delle attività sul desktop all'interazione con il terminale e IDE, e dall'assistenza alla scrittura alla generazione di diagrammi. Il tutto con il supporto della ricerca, accesso rapido e contestuale, e la possibilità di interazione vocale.
Anche Anthropic ha presentato un progetto di interazione con il computer per automatizzare le operazioni. E probabilmente anche Google sta introducendo un concetto simile con un progetto denominato Jarvis.

Si preannuncia uno scenario in cui gli utenti potranno interagire con diversi AI Agent attraverso il linguaggio naturale, i quali gestiranno processi e applicazioni su diversi dispositivi per raggiungere gli obiettivi.
12) Le nuove architetture alla base della crescita delle performance dei Large Language Model
o3, presentato durante il "Day 12" è la dimostrazione (ancora una volta) del fatto che non basta aumentare la scala dei modelli precedenti per incrementare le performance: servono nuove idee e nuove architetture.
Day 12 di OpenAI: o3
L'aspetto più interessante è la capacità di adattamento che sembra avere il modello su compiti inediti, ottenendo risultati mai visti prima, riuscendo a sintetizzare nuove soluzioni.
Ho la sensazione che questi modelli usino una struttura multi-agent, con agenti che valutano la richiesta (sicurezza), interagiscono autonomamente creando catene di ragionamento (reasoning), per valutarle e per validarle.
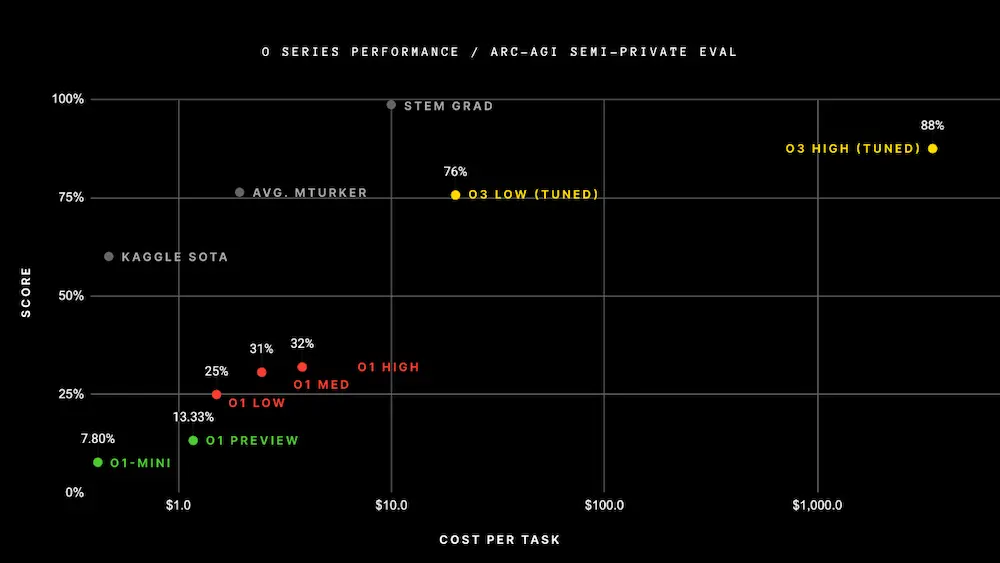
Sulla carta, stiamo parlando di un passo in avanti sbalorditivo.. oltre ogni aspettativa.
Nel 2025 potremo analizzarlo più a fondo. I benchmark, attualmente, sono tutti in ambito coding e su task matematici, e non è ancora ben chiaro come sia stato addestrato il modello, e come siano stati condotti i test.
Dall’AI nel 2025 mi aspetto ottimizzazione, miglioramento delle performance, ma soprattutto INTEGRAZIONE.
Perché non esiste innovazione senza integrazione.
- GRAZIE -
Se hai apprezzato il contenuto, e pensi che potrebbe essere utile ad altre persone, condividilo 🙂