ChatGPT e Python per l'analisi dei dati
Come possiamo analizzare i nostri dati sfruttando ChatGPT (GPT-4) e Python? L'intelligenza artificiale può offrire degli strumenti potenti, utili a democratizzare dati e competenze.

Lo ammetto.. avendo un background da developer, e sapendo cosa significa creare un buon software, sono sempre stato abbastanza scettico nel considerare l'utilizzo di un modello di linguaggio per la generazione di codice di programmazione. Quindi, per affrontare il mio "demone", ho deciso di metterlo alla prova sul campo a supporto dell'analisi dei dati, per elaborare un dataset abbastanza ampio generando anche dei semplici widget per una potenziale dashboard.
Il dataset protagonista dell'analisi è un'estrazione dei dati di viaggio delle biciclette elettriche di Divvy, il sistema di bike sharing nell'area metropolitana di Chicago. Ho utilizzato i dati di spostamento dei mezzi di 5 giorni: i dati di ogni giorno vengono salvati all'interno di un file CSV che ha la seguente struttura.

I 5 giorni che ho utilizzato corrispondono a circa 1 GB di dati testuali.
Gli step per l'analisi sfruttando ChatGPT (GPT-4)
Vediamo le operazioni di estrazione dei dati e di creazione dei widget per la data visualization. Ho eseguito gli step in modo sequenziale sfruttando ChatGPT (GPT-4) per produrre il codice Python necessario.
1) La creazione del dataframe
Nel primo step andiamo a creare la struttura dei dati trasformando una lista di CSV in un "dataframe". Questo ci permetterà, prima di tutto di evitare di unire i CSV manualmente (Excel non riesce ad aprire file di dimensioni così elevate), ma anche di operare in maniera molto più veloce.
Quindi iniziamo con il seguente prompt.
Genera uno script python per importare tutti i file CSV di una directory ed inserirli in un unico dataframe. Lo script, inoltre, deve stampare le prime 20 righe del dataframe. Utilizza la libreria "os".
Nel prompt specifico la libreria da usare ("os"), ma non è necessario.
Quello che segue è l'output di ChatGPT.
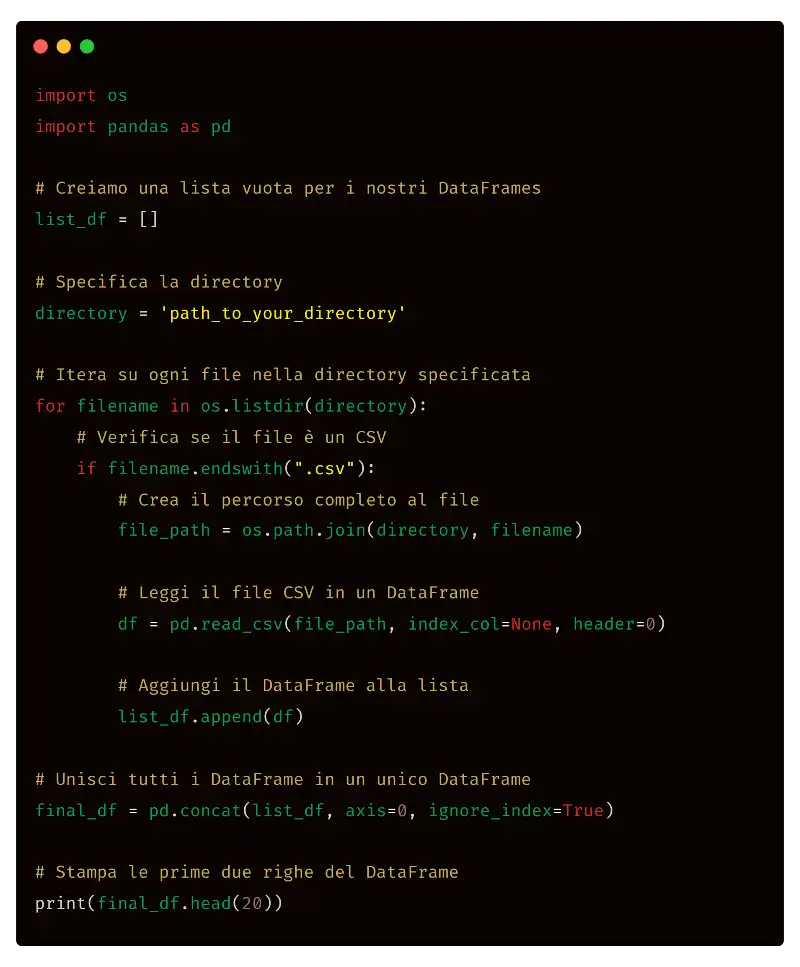
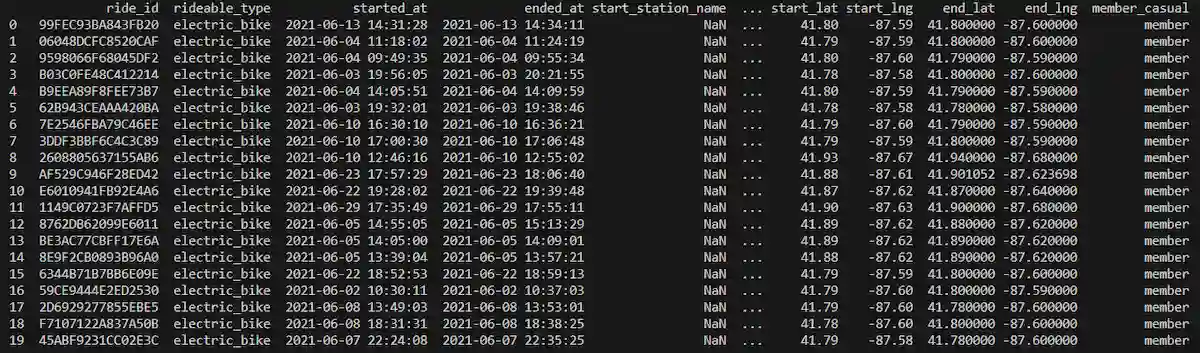
Come vediamo, lo script è molto semplice: per utilizzarlo, è sufficiente sostituire "path_to_your_directory" con la path della directory locale contenente la lista dei file CSV. Eseguendo il codice da una console Python, viene creato il dataframe e otteniamo la stampa delle prime 20 righe della struttura dati come richiesto dal prompt.
2) Le tipologie di utente
Attraverso il seguente prompt su ChatGPT andiamo a chiedere di estrarre la distribuzione delle diverse tipologie di utente.
Conta i diversi tipi di utenti presenti nel dataframe nella colonna "member_casual".
Come si può notare, non specifico più che l'output desiderato è uno script Python, perché il contesto della chat lo rende sottinteso.
L'output di ChatGPT è il seguente.
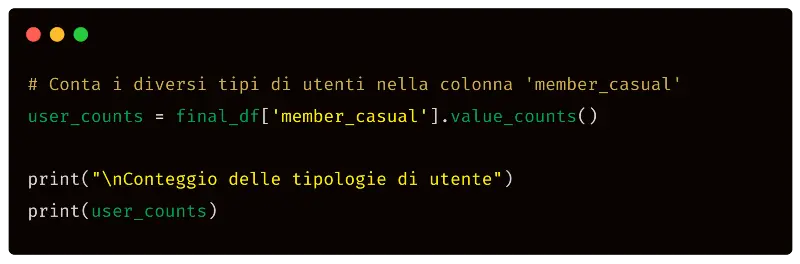
Eseguendo il codice in una console Python, otteniamo la seguente stama in console.

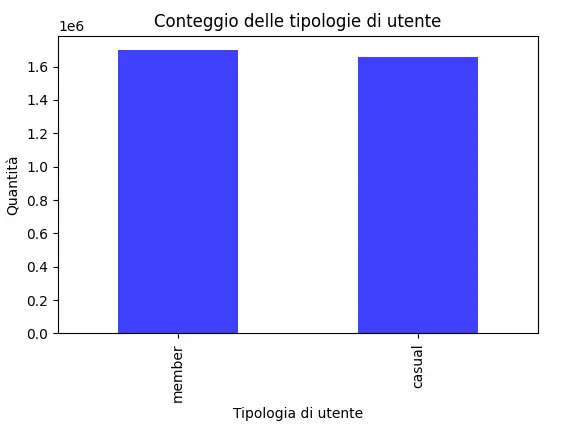
Il sistema, quindi, stampa il numero di utenti di tipologia "member" e di tipologia "casual". E perché non rappresentare i dati graficamente? Utilizziamo il seguente semplicissimo prompt per generare il codice Python necessario.
Rappresenta in un diagramma i dati estratti dall'ultima istruzione.
Quello che segue è il risultato dell'elaborazione di ChatGPT.
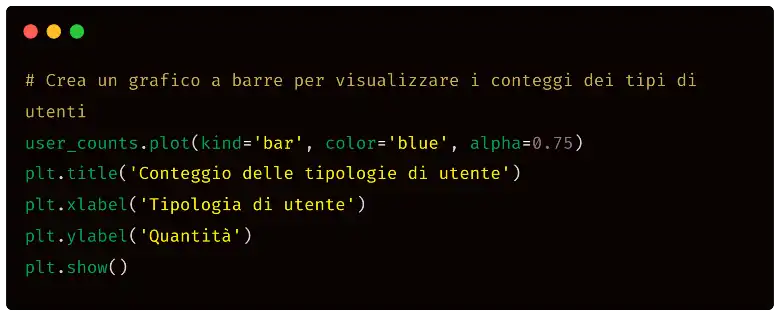
Eseguendo lo script in una console Python, otteniamo il seguente risultato, ovvero il diagramma che sarà il primo widget della nostra dashboaed di analisi.
3) Le tipologie di noleggio
Nello stesso modo in cui abbiamo estratto le tipologie di utente otteniamo quelle di noleggio, ovvero i mezzi utilizzati dalle persone per i loro spostamenti. Usiamo il seguente prompt.
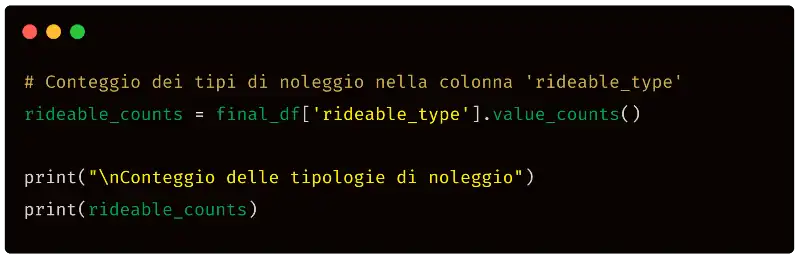
Conta i diversi tipi di noleggi nel dataframe attraverso la colonna "rideable_type".
Quello che segue è il codice Python prodotto da ChatGPT.
E questo è il risultato nella console di Python eseguendo il codice.
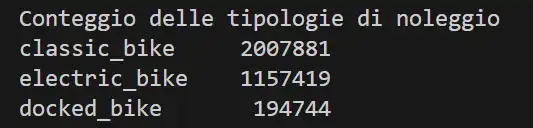
Il risultato è quello che si voleva ottenere, ovvero il numero di noleggi per ogni tipologia di mezzo. Ancora una volta, andiamo a rappresentare il dato, con un prompt identico al precedente, contando sul fatto che ChatGPT mantiene il contesto della conversazione. Quello che segue è il codice Python generato da ChatGPT.
Quello che segue, invece, è il diagramma prodotto dall'esecuzione del codice.
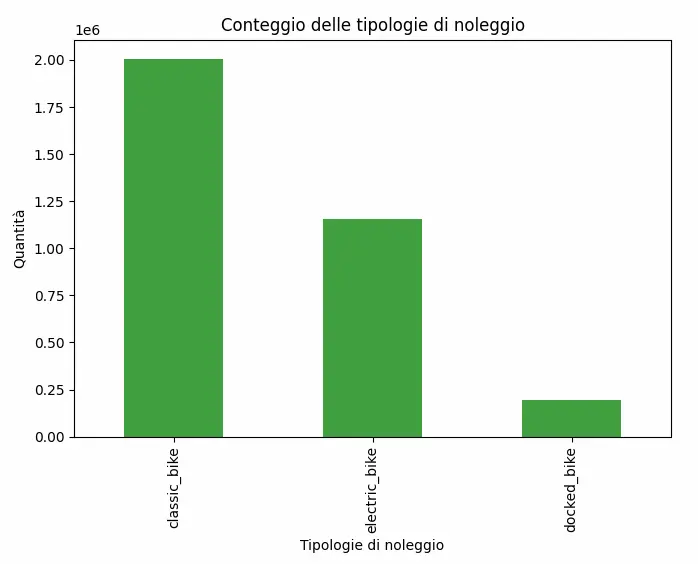
E con questo, abbiamo il secondo widget della dashboard di analisi dei dati.
4) Il tempo medio di utilizzo per tipo di noleggio
Continuiamo l'esplorazione dei dati andando ad estrarre il tempo medio di utilizzo per le singole tipologie di mezzo. Per farlo, utilizziamo il seguente prompt per generare il codice Python necessario.
Calcola il tempo medio di utilizzo (in minuti) per ogni tipologia di mezzo (colonna "rideable_type") usando la differenza tra tempo di fine e tempo di inizio. Nel dataframe è presente la colonna "ended_at" nel formato "2021-06-13 14:31:28" e la colonna "started_at" nel formato "2021-06-13 14:31:28".
Come visto fino a questo momento, il prompt descrive il task da eseguire e anche le caratteristiche del dataframe. ChatGPT, infatti, produce il codice per elaborare la struttura dati, ma non ne conosce il formato.
L'output con il codice Python ottenuto è il seguente.
E quello che segue è l'output stampato in console.
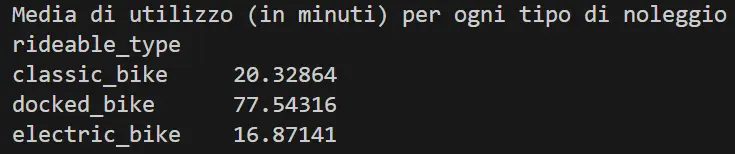
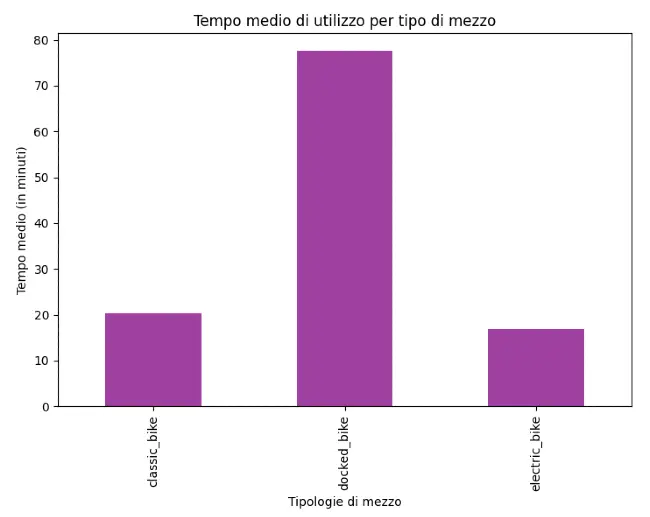
Quindi abbiamo una media di circa:
- 20.3 minuti per la "classic_bike",
- 77.5 minuti per la "docked_bike",
- 16.9 minuti per la "electric_bike".
Con lo stesso prompt, in cui chiediamo di rappresentare i dati, otteniamo il codice per il terzo widget della dashboard.
Ed ecco il risultato.
5) La distanza media per tipo di noleggio
All'interno del dataframe sono presenti le coordinate (latitudine e longitudine) della stazione di partenza del noleggio e dalla conclusione del percorso. Quanti chilometri percorrono mediamente i clienti per ogni tipologia di noleggio? Proviamo a chiedere a ChatGPT di generare il codice per ottenere questa informazione.
Nel dataframe sono presenti le coordinate di latitudine e longitudine della partenza (colonne "start_lat" e "start_lng") e dell'arrivo (colonne "end_lat" e "end_lng"). Calcola la distanza media in Km percorsa dai clienti per ogni tipologia di mezzo (colonna "rideable_type").
Quello che produce ChatGPT è il seguente codice Python.
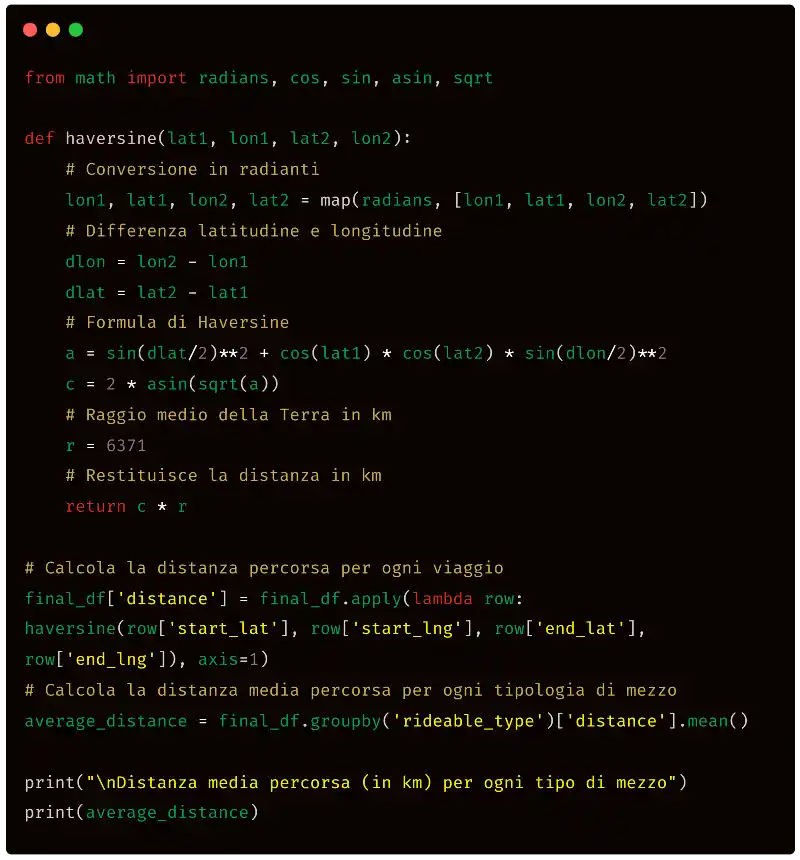
Per il calcolo, viene generata una funzione che applica la formula di Haversine, utile a determinare la distanza tra due punti sulla superficie di una sfera a partire dalle coordinate (ammetto che non la conoscevo prima che l'algoritmo me la presentasse). Chiaramente si tratta di una misura approssimata, che rimane accettabile per distanze brevi. Quello che segue è il risultato dell'esecuzione.
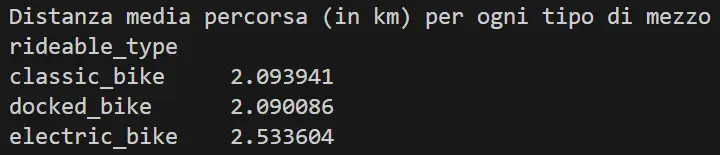
Abbiamo quindi una media di circa:
- 2.1 Km per le "classic_bike" e le "docked_bike",
- 2.5 Km per le "electric_bike".
Come sempre, andiamo a generare la componente visuale e un nuovo widget per la nostra dashboard. Ho utilizzato il seguente prompt.
Nel dataframe sono presenti le coordinate di latitudine e longitudine della partenza (colonne "start_lat" e "start_lng") e dell'arrivo (colonne "end_lat" e "end_lng"). Calcola la distanza in Km di ogni noleggio e genera il codice per un diagramma che mostra tutte le distanze percorse. Usa colori diversi per ogni tipo di mezzo (colonna "rideable_type").
A questo punto, mi aspettavo di ottenere il codice per un istogramma con tutti i noleggi, per ognuno la distanza percorsa, e con le barre di colore diverso per ogni mezzo. Ma non è andata così..

Il diagramma prodotto è un box plot: una tipologia di rappresentazione ideale proprio per descrivere una distribuzione di dati. Quello che segue è il risultato dell'esecuzione.
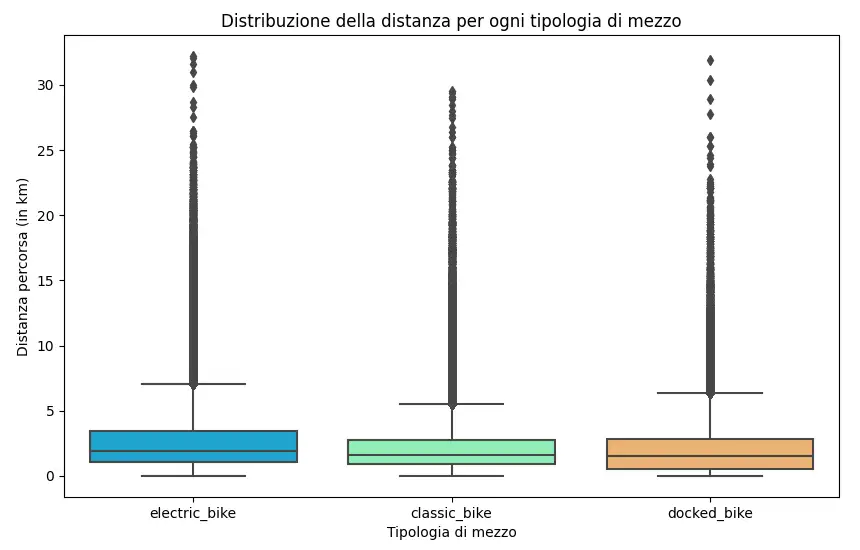
Come si vede, per ogni tipologia di noleggio, è possibile osservare l'area in cui si concentra la maggior quantità di distanze, la distanza media e anche i valori anomali (outlier).
Subito dopo, ho voluto provare a forzare la rappresentazione che avevo in mente (l'istogramma). Quindi, ho usato il seguente prompt.
Utilizza un istogramma con tutte le misure di distanza invece di un box plot, e usa colori diversi per i diversi mezzi.
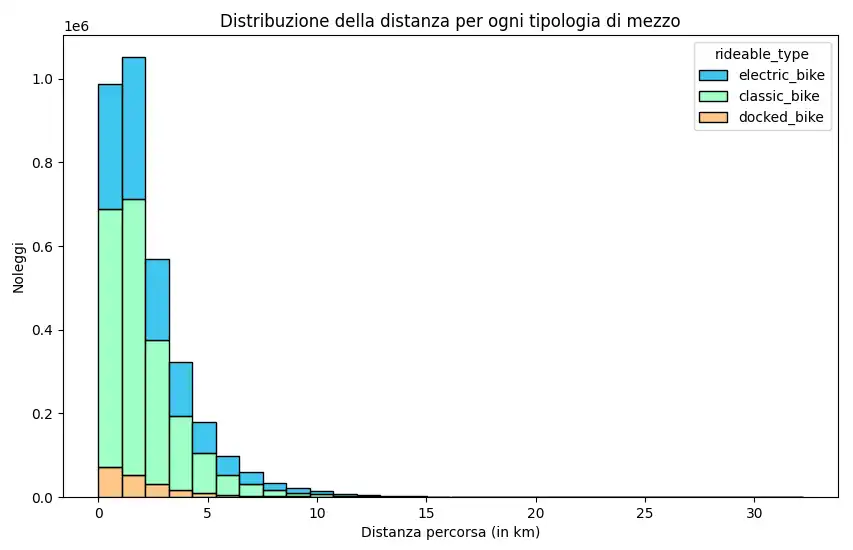
L'output di ChatGPT è il seguente.
Ancora una volta, l'algoritmo ha generato un diagramma diverso da quello che avevo in mente (pur essendo un istogramma).. ma, devo essere sincero, ancora una volta è una soluzione migliore dal punto di vista dalla data visualization.
Le ultime due interazioni fanno emergere un concetto sul quale è importante riflettere per acquisire consapevolezza in questo ambito.
Gli algoritmi generativi non sono interessanti solo come esecuzione di operazioni in modo più efficiente, ma anche per le idee che possono stimolare.
6) Clustering: raggruppamento dei noleggi
Proviamo a raggruppare i noleggi per similarità, in modo da capire maggiormente le caratteristiche delle dinamiche del comportamento degli utenti.
Ho usato il seguente prompt in modo da ottenere il codice Python necessario per eseguire il clustering.
Esegui le seguenti 2 operazioni: 1) Clusterizza i dati raggruppando i noleggi per similarità, considerando diversi dati, ad esempio la distanza percorsa (colonna "distance" del dataframe), il tempo di utilizzo (colonna "duration" del dataframe), le coordinate di partenza (colonne "start_lat" e "start_lng" del dataframe) e di arrivo (colonne "end_lat" e "end_lng" del dataframe), il tipo di mezzo (colonna "rideable_type" del dataframe). 2) Stampa i primi 10 noleggi di ogni cluster (solo le colonne " rideable_type ", "started_at", "ended_at", "start_station_name", "end_station_name", "start_lat", "start_lng", "end_lat", "end_lng", "member_casual", "duration", "distance").
Quello che segue è il codice prodotto da ChatGPT.
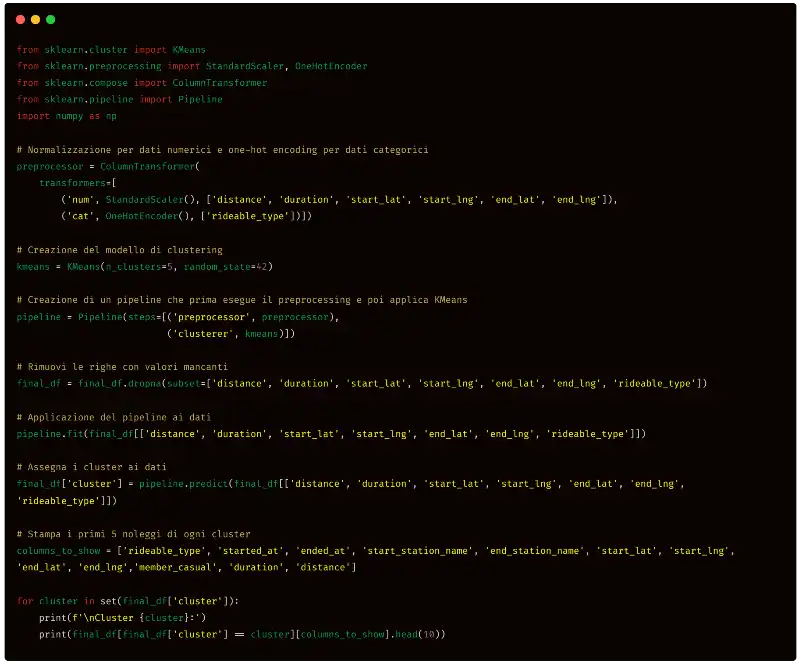
Come si vede, prima di tutto i dati vengono normalizzati per poter ottenere il miglior risultato possibile dall'algoritmo di clustering. Successivamente viene utilizzato K-means (una scelta abbastanza classica) per il raggruppamento.
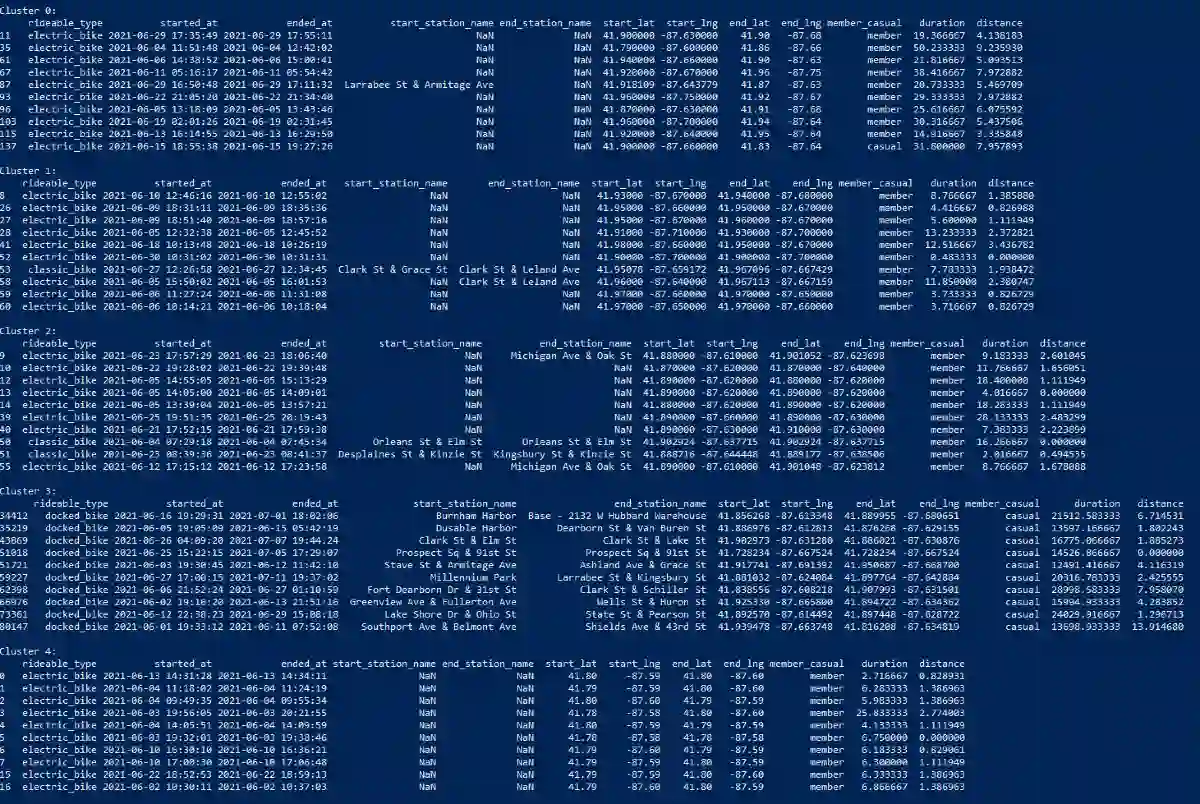
Ed ecco l'esecuzione in console, in cui si vedono i 5 cluster generati dall'algoritmo con i dati dei primi 10 noleggi del gruppo.
Anche in questo caso, vogliamo rappresentare i cluster. Per farlo, utilizzo un prompt per ChatGPT in cui chiedo di generare il codice Python per una rappresentazione in tre dimensioni.
Rappresenta i cluster in un diagramma in 3 dimensioni.
Il codice Python risultante, prima di tutto esegue la riduzione della dimensionalità usando la PCA (analisi delle componenti principali) e successivamente "disegna" il diagramma.
L'esecuzione del codice in console, produce il seguente diagramma.
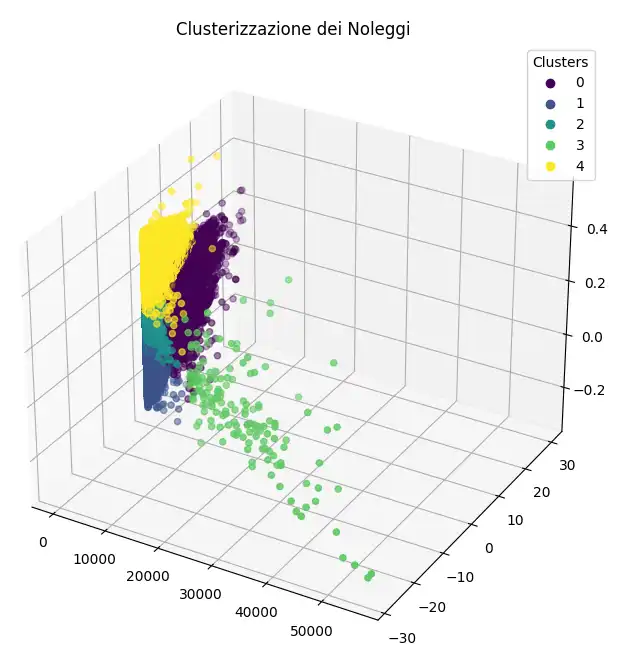
Questo tipo di rappresentazione ci fornisce da subito delle informazioni utili sui cluster: ad esempio possiamo vederne l'estensione e la densità.
Possiamo notare come il cluster numero 3 (quello verde) sia il meno numeroso e il meno denso. Questo potrebbe significare che si tratti di un cluster di "anomalie", ovvero di noleggi poco frequenti.
Tuttavia, il raggruppamento non è sufficiente per avere un buon quadro della situazione, perché, di fatto, non conosciamo le caratteristiche che hanno portato l'algoritmo a scegliere i gruppi di appartenenza delle entità. Trattandosi di set di dati ampi, fare un controllo "manuale" anche su un campione potrebbe significare l'impiego di un effort elevato. Quindi possiamo sfruttare l'intelligenza artificiale per eseguire il controllo al posto nostro. In particolare, usiamo GPT-4.
7) Nomi e descrizioni dei cluster usando l'AI
Per ottenere i nomi e le descrizioni dei cluster ad opera di GPT-4, possiamo utilizzare un prompt come il seguente.
Quelli che seguono sono 5 cluster di dati di noleggio di biciclette elettriche. Descrivi la similarità tra i dati e trova un nome per ogni cluster. Cluster 0: ... Cluster 1: ... Cluster 2: ... Cluster 3: ... Cluster 4: ...
Al posto dei puntini, ho inserito le prime 10 righe dei dati di ogni cluster che erano state stampate in console precedentemente. L'algoritmo, quindi, va a trovare le correlazioni generando titolo e descrizione di ogni gruppo.
Quello che segue è l'output di GPT-4: "i dati dei cinque cluster presentano delle differenze significative nelle caratteristiche di utilizzo delle biciclette elettriche, come ad esempio la durata del viaggio e la distanza percorsa".
Cluster 0: Viaggi prolungati di membri
In questo gruppo, tutti gli utenti sono membri. La durata media dei viaggi è relativamente alta, indicando viaggi più lunghi o frequenti fermate. Molte di queste corse non hanno una stazione di partenza o di arrivo definita.
Cluster 1: Viaggi brevi e locali
Si tratta principalmente di viaggi di durata inferiore con distanze ridotte, suggerendo che gli utenti potrebbero utilizzare le biciclette per spostamenti brevi o locali.
Cluster 2: Viaggi urbani medi
Questi viaggi tendono ad avere durate medie e distanze mediamente lunghe. La maggior parte delle corse sembra avvenire in centro città, indicando forse un uso per spostamenti quotidiani o pendolarismo.
Cluster 3: Noleggi estremamente prolungati
Questi noleggi durano per giorni, indicando forse un noleggio a lungo termine o errori nei dati. La distanza di questi viaggi non è proporzionalmente lunga, il che suggerisce che le biciclette potrebbero essere state utilizzate in modo intermittente o mantenute in un unico luogo per gran parte del periodo di noleggio.
Cluster 4: Viaggi con partenza e arrivo alla stessa stazione
Questi viaggi iniziano e terminano alla stessa stazione, il che suggerisce che potrebbero essere viaggi di piacere o di allenamento, piuttosto che viaggi da un punto all'altro. Anche in questo caso, la durata del viaggio è abbastanza lunga, il che corrisponde all'idea di viaggi di piacere o di allenamento.
Il modello ha prodotto quello che ci serviva, spiegandoci il contenuto dei singoli cluster.
Una curiosità. In precedenza, osservando il diagramma dei cluster, abbiamo ipotizzato che il gruppo 3 (verde), essendo il meno ampio e denso, probabilmente rappresenta dei "noleggi anomali". Infatti la descrizione dell'algoritmo di quel cluster riguarda proprio i noleggi estremamente prolungati (che per delle bici elettriche equivale a delle anomalie) o errori nei dati.
Conclusioni
Ha fatto tutto l'algoritmo? Certo! Ho eseguito delle modifiche leggerissime al codice generato (stringhe e commenti). Ma quello che dobbiamo ricordarci è che..
..sapevo esattamente cosa chiedere
e cosa volevo ottenere!
L'algoritmo è uno straordinario potenziamento delle nostre capacità, non una dose di magia che può trasformare il piombo in oro.
Tuttavia, flussi di questo tipo possono essere condivisi in azienda a persone che non si occupano di sviluppo in modo molto più semplice rispetto a far apprendere delle procedure basate sull'insegnamento del codice di programmazione. Aggiungo che oggi, usare Python in locale attraverso Visual Studio, e magari attraverso dei Notebook Jupyter è diventato davvero una procedura alla portata di tutti (nelle risorse sotto ho indicato una guida).
Questo racconto vuole essere un esempio per spiegare come, anche chi non ha solide basi di programmazione può sfruttare l'AI per generare semplici dashboard e analizzare dataset di grandi dimensioni.
Per approfondire

 Alessio Pomaro
Alessio Pomaro Alessio Pomaro
Alessio Pomaro Alessio Pomaro
Alessio Pomaro